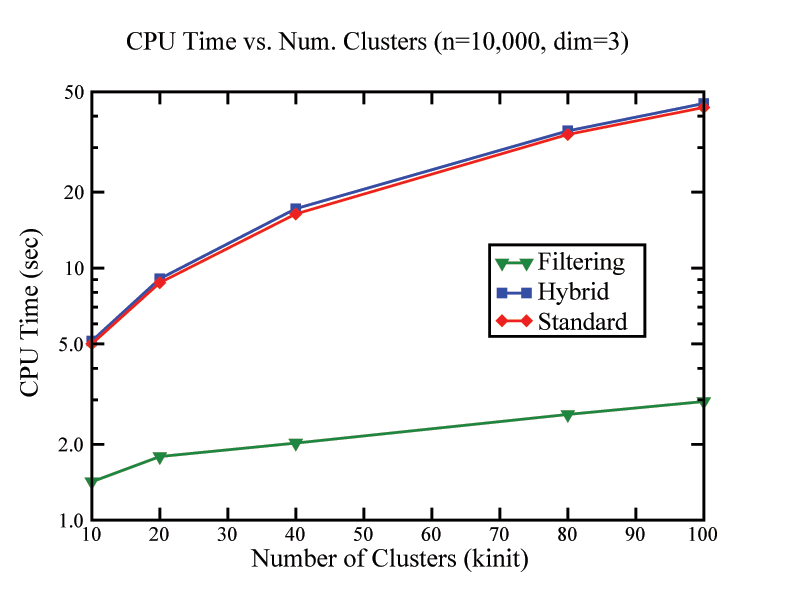
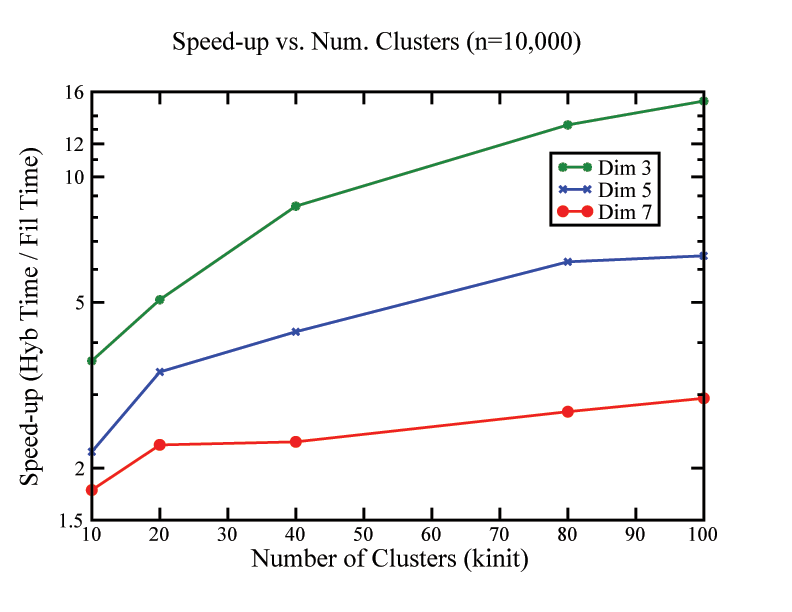
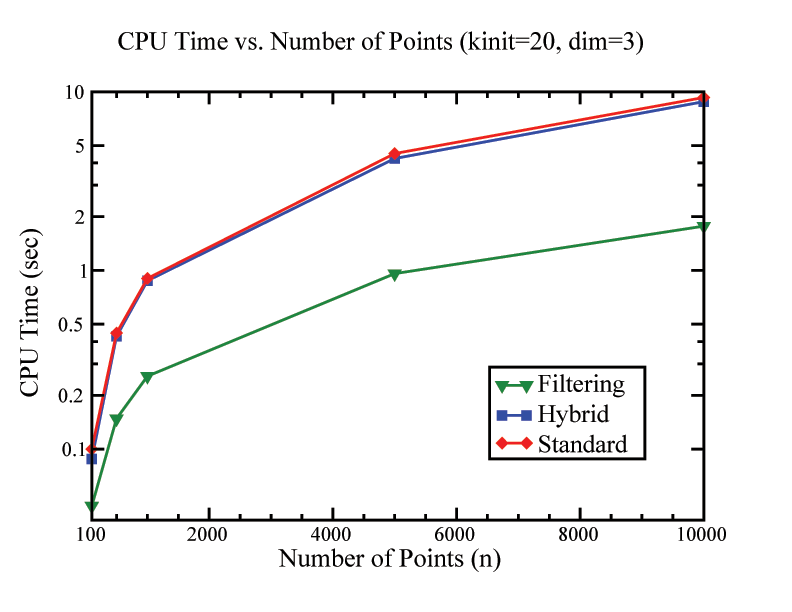
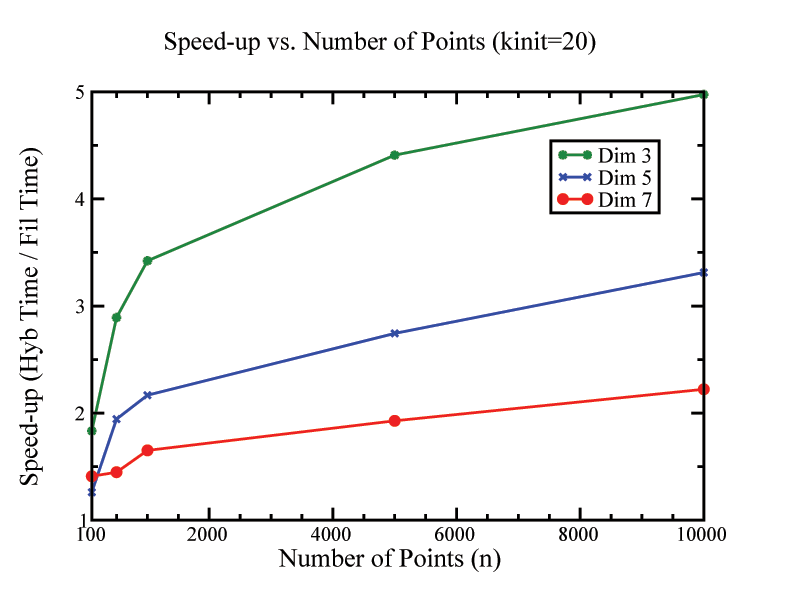
|
This is a collection of C++ programs that implement the
popular clustering algorithm known as ISODATA. (See
Algorithms for Clustering Data by A. K. Jain and R.
C. Dubes, Prentice Hall, 1988). Intuitively, the algorithm
tries to find the best set of cluster centers for a given
set of points in d-dimensional space through an iterative
approach until some maximum number of iterations are
performed. It uses a number of different heuristics to
determine when to merge or split clusters.
At a high level, in each iteration of the algorithm the
following takes place: points are assigned to their closest
cluster centers, cluster centers are updated to be the
centroid of their associated points, clusters with very few
points are deleted, large clusters satisfying some
heuristics are split, and small clusters satisfying other
heuristics are merged. The algorithm continues until
maximum number of iterations are performed. Here we go over
the algorithm in more detail. See the related publications
below for further information.
The code is written in C++ and has been successfully
compiled and run on a SUN Blade 100 running Solaris 2.8,
using the g++ compiler (version 2.95.3). After downloading
and unzipping each version, type "make" to compile
the program into the executable called "IsoClus". To run
the code, type "IsoClus < filename" where
"filename" is the name of the input file containing running
time parameters. A sample input file listing all directives
is available
here.
Various implementations of the algorithm as mentioned in the
paper below are available below for download. These are
described below.
|