XSQ evaluates XPath queries over streaming XML data. That is, it makes only pass over the data, in an order determined by the data source. This behavior is useful for streaming data sources such as news feeds and RSS channels, and also for disk-resident data that is best accessed using a sequential scan. XSQ provides high throughput with minimal buffering.
XSQ is implemented using Java and a SAX parser. The design is based on generating an automaton from the given XPath query. The automaton may be described briefly as an hierarchical arrangement of pushdown transducers augmented with buffers. (For details, please refer to the paper referenced below.) Unlike DOM-based query engines, XSQ does not need to load the entire dataset into memory. As a result, it has a small memory footprint and provides high throughput and low response times. For example, XSQ easily processes datasets 2GB and larger on a modest PC-class machine. (We're always looking for larger and more interesting datasets; please contact us if you'd like to share yours.)
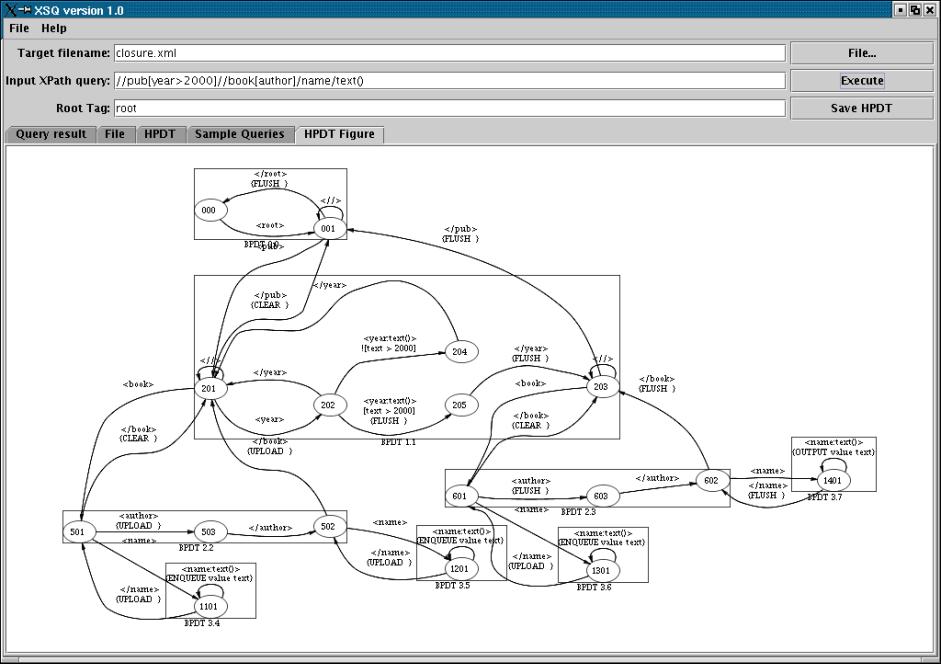
The screenshot below illustrates XSQ's graphical interface being used
to query XML files. In addition to the query results, XSQ presents the
automaton it uses to process the query. Each box is a standalone BPDT
(basic PDT) that has a separate buffer. The buffer operations are
labeled on the transitions. The HPDT is essentially a network of BPDTs
that can communicate using the buffer operation.
XSQ is written in Java and should run on any recent Java Runtime
Environment. The source code is released under GNU GPL license:
xsqf.tar.gz
The code comes with instructions for setup and use. For further details, please refer to the following or contact us.
We welcome your comments and suggestions. We would be grateful if you could inform us of how you are using XSQ. In particular, if you make some code modifications that you would like to share, we would be happy to incorporate them in the next version.
XSQ uses Xerces for parsing the input and Graphviz to display the automaton.