
|
| Our framework disentangles spatial and style information for image synthesis. It predicts a latent spatial layout for the target image, which is used to produce per-pixel style modulation parameters for the final synthesis. |
|
|
|
|
|
|
|
|||
|
|
|
|
|
| Our framework disentangles spatial and style information for image synthesis. It predicts a latent spatial layout for the target image, which is used to produce per-pixel style modulation parameters for the final synthesis. |
| We propose a novel approach for few-shot talking-head synthesis. While recent works in neural talking heads have produced promising results, they can still produce images that do not preserve the identity of the subject in source images. We posit this is a result of the entangled representation of each subject in a single latent code that models 3D shape information, identity cues, colors, lighting and even background details. In contrast, we propose to factorize the representation of a subject into its spatial and style components. Our method generates a target frame in two steps. First, it predicts a dense spatial layout for the target image. Second, an image generator utilizes the predicted layout for spatial denormalization and synthesizes the target frame. We experimentally show that this disentangled representation leads to a significant improvement over previous methods, both quantitatively and qualitatively. |
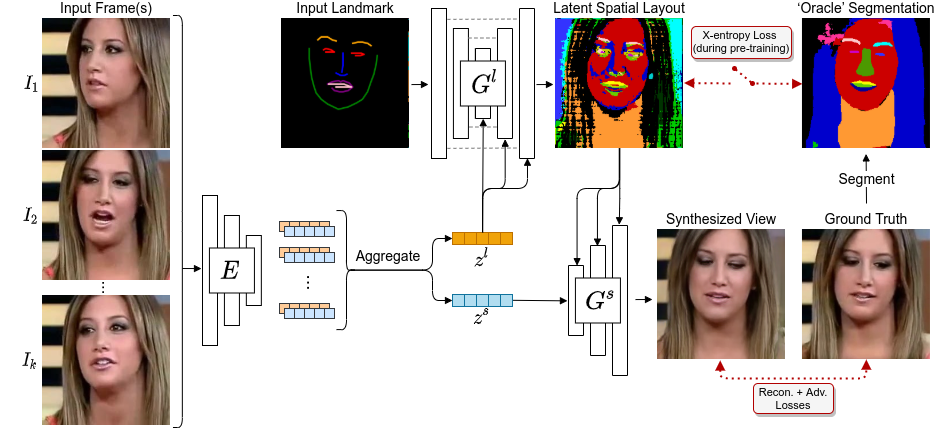 |
| Overview of our training pipeline. The cross-entropy loss with the oracle segmentation is used during pre-training the layout predictor, and then turned off during the full pipeline training. |
In-domain results |
Out-of-domain results |
|

|
| Qualitative comparison in the single-shot setting. We show three sets of examples representing low, medium and high variance between the source and target poses. Our method is more robust to pose variations than the baselines. |

|
| Reenactment results with different K-shot inputs and with vs. without subject fine-tuning. Our model extrapolates well to challenging poses and expressions even with a single-shot input (shown in source), while preserving the source identity. |
 |
Moustafa Meshry, Saksham Suri, Larry S. Davis, Abhinav Shrivastava. Learned Spatial Representations for Few-shot Talking-Head Synthesis. (Paper | Supplementary | arXiv | Bibtex) |
|
|