Google Scanned Objects
Contains 300 scenes, with 20 random objects per scene. Cameras are placed on a hemisphere around the scene and are pointed towards the center of the scene. Scenes are lit by a single white dome light.










The RTMV dataset is composed of nearly 2000 scenes from 4 different environments exhibiting large varieties in view positions, lighting, object shapes, materials, and textures. Each quadrant shows a single scene from each environment, captured from multiple viewpoints.
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset were composed to exhibit challenging variations in camera views, lighting, shape, materials, and textures.
Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time.
Our dataset is generated by a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
Our dataset consists of scenes from four different environments, namely Google Scanned Objects, ABC, Bricks and Amazon Berkeley. Each scene has 150 renders at a 1600 x 1600 resolution.
Contains 300 scenes, with 20 random objects per scene. Cameras are placed on a hemisphere around the scene and are pointed towards the center of the scene. Scenes are lit by a single white dome light.
Contains 300 scenes, with 50 random objects per scene and random camera views. Objects have randomly selected color and material. Scenes are lit by a uniform dome light and an additional bright point light to produce hard shadows.
Contains 1027 scenes, with a single bricks (lego) model per scene and hemisphere views. The camera is aimed at random locations within 1/10 of the unit volume used to scale the object, thus producing images that are not centered on the model. Each scene is illuminated by a white dome light and a warm sun placed randomly on the horizon.
Contains 300 scenes, with 40 random objects per scene.
Similar to ABC, cameras are placed randomly within a unit cube and are aimed at any object.
We light scenes with a full HDRI map and apply a random texture on the floor.
This is our most challenging environment.
We present Sparse Voxel Light Field (SVLF); an efficient voxel-based light field approach for novel view synthesis. SVLF achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render.
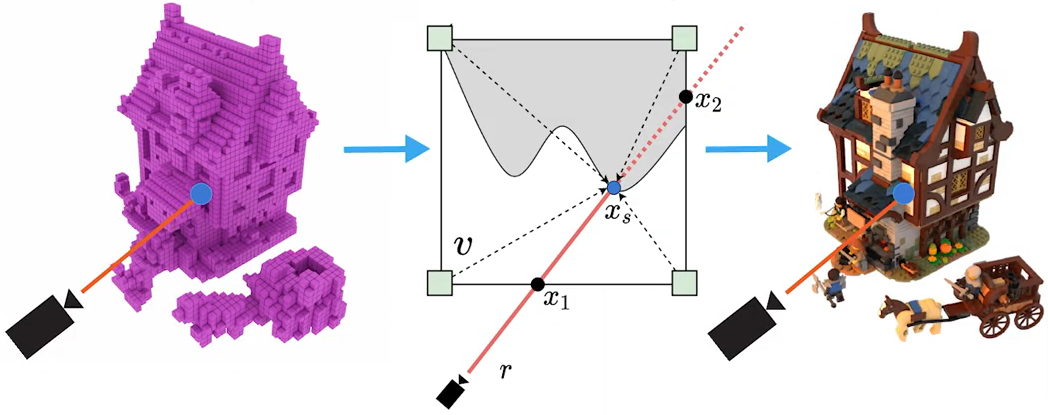
At a high level, SVLF maps a ray to the optical thickness and color values associated with each intersected voxel. This mapping is realized by evaluating two small decoder networks. The first decoder predicts the optical thickness as well as a within-voxel depth to a surface hit (if any), and the second decoder evaluates the color value at the estimated surface hit.
We also propose an accelerated standalone Python-enabled ray tracing / path tracing renderer built on NVIDIA OptiX with a C++/CUDA backend. The Python API allows for non-graphics experts to easily install the renderer and quickly create 3D scenes with the full power that scripting provides.
Using our python ray tracer, we can produce high-quality image renders and testing scenes as shown above.
@article{tremblay2022rtmv,
author = {Tremblay, Jonathan and Meshry, Moustafa and Evans, Alex and Kautz, Jan and Keller, Alexander and Khamis, Sameh and Loop, Charles and Morrical, Nathan and Nagano, Koki and Takikawa, Towaki and Birchfield, Stan},
title = {RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis},
journal = {IEEE/CVF European Conference on Computer Vision Workshop (Learn3DG ECCVW), 2022},
year = {2022},
}