|
|
| Our style-based pre-training enables simple and efficient training of multi-modal Image-to-Image translation networks using only reconstruction and adversarial loss terms. |
|
|
|
|
|
|
|
|||
|
|
|
|
|
| Our style-based pre-training enables simple and efficient training of multi-modal Image-to-Image translation networks using only reconstruction and adversarial loss terms. |
| We propose a novel approach for multi-modal Image-to-image (I2I) translation. To tackle the one-to-many relationship between input and output domains, previous works use complex training objectives to learn a latent embedding, jointly with the generator, that models the variability of the output domain. In contrast, we directly model the style variability of images, independent of the image synthesis task. Specifically, we pre-train a generic style encoder using a novel proxy task to learn an embedding of images, from arbitrary domains, into a low-dimensional style latent space. The learned latent space introduces several advantages over previous traditional approaches to multi-modal I2I translation. First, it is not dependent on the target dataset, and generalizes well across multiple domains. Second, it learns a more powerful and expressive latent space, which improves the fidelity of style capture and transfer. The proposed style pre-training also simplifies the training objective and speeds up the training significantly. Furthermore, we provide a detailed study of the contribution of different loss terms to the task of multi-modal I2I translation, and propose a simple alternative to VAEs to enable sampling from unconstrained latent spaces. Finally, we achieve state-of-the-art results on six challenging benchmarks with a simple training objective that includes only a GAN loss and a reconstruction loss. |
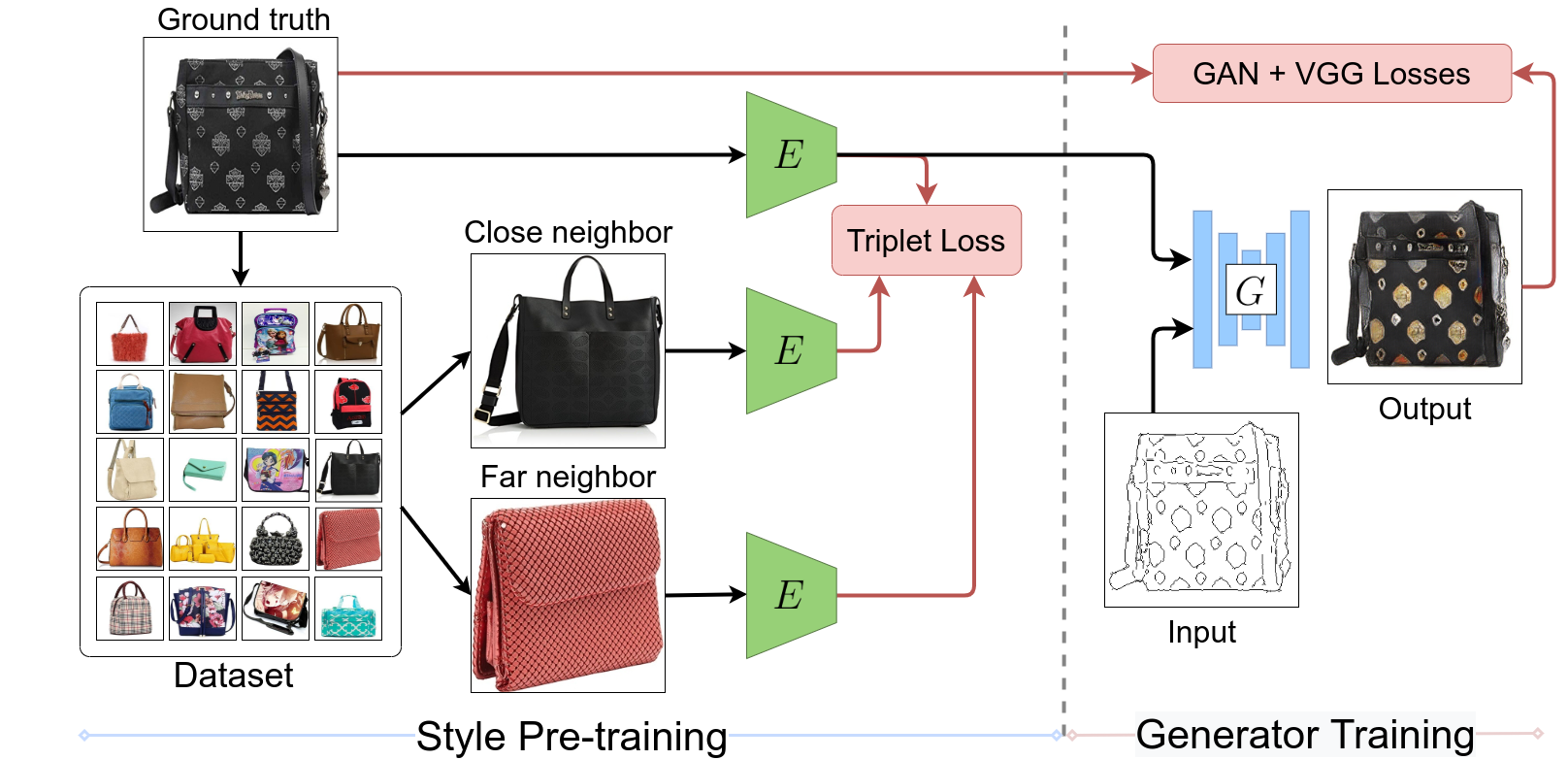 |
| Overview of our training pipeline. Stage 1: pre-training the style encoder E using a triplet loss. Stages 2, 3: training the generator G, and finetuning both G, E together using GAN and reconstruction losses. |

|
| Qualitative comparison with baselines. Our style-based pre-training approach better matches the ground truth (GT) style. |

|
| Style interpolation. Left column is the input to the generator G, second and last columns are input style images to the style encoder, and middle images are linear interpolation in the embedding space. |

|
| We propose two simple alternatives to VAEs to enable sampling from unconstrained latent spaces. Left: input and ground truth images. Middle: sampling results from a normal distribution emperically computed from the trainset. Right: sampling results using a mapper network trained to map the unit gaussian to the unconstrained latent distribution. |
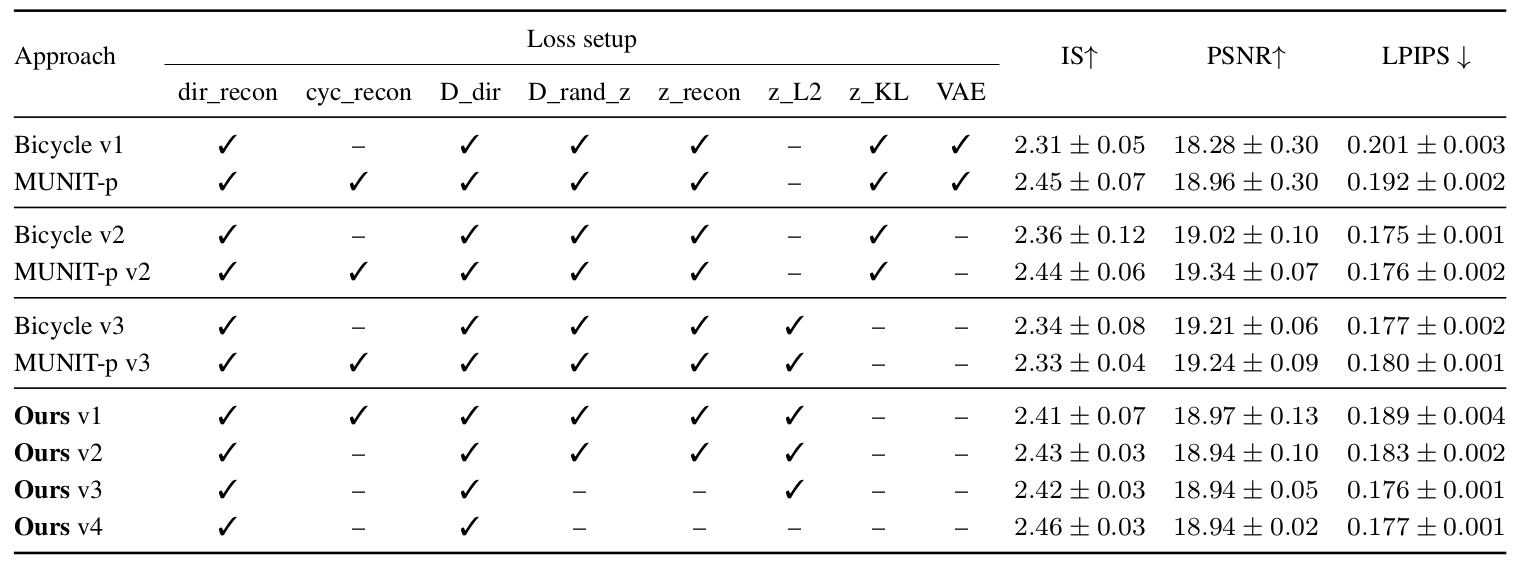
| We study the effect of different components and loss terms used for training curent Image-to-Image (I2I) translation pipelines. We study direct and cyclic reconstructions on ground truth images (dir_recon, cyc_recon), discriminator loss on direct reconstructions and on generated images with a randomly sampled style (D_dir, D_rand_z), latent reconstruction (z_recon), L2 and KL regularization on the latent vector z (z_L2, z_KL), and finally the use of VAE vs. just an auto-encoder. The proposed style pre-training greatly simplifies the training objective of current I2I translation pipelines while maintaining competitive performance. |
|
 |
Moustafa Meshry, Yixuan Ren, Larry S. Davis, Abhinav Shrivastava. StEP: Style-based Encoder Pre-training for Multi-modal Image Synthesis. (Paper | Supplementary | arXiv | Bibtex) |
|
|