UMD Departments: Computer Science, Kinesiology, Mechanical Engineering
UMD Programs: NACS, Maryland Robotics Center, UMIACS
Collaborating Universities: Syracuse University, University of Virginia
This material was last updated in January 2020.
Imitation Learning by Cognitive Robots
ONR Grant N000141310597 (2013-2017) Lockheed Martin ETL Seed Grant N000141310597 (2017-2018) ONR Grant N000141912044 (2019-2021)
Participants
Faculty
Rodolphe Gentili, Assistant Professor, Kinesiology, NACS, Robotics Center*
S. K. Gupta, Professor, Mechanical Engineering, ISR, Robotics Center
Garrett Katz, Assistant Professor, Computer Science, Syracuse University*
Dana Nau, Professor, Computer Science, ISR, Robotics Center
James A. Reggia, Professor, Computer Science, UMIACS, Robotics Center*
Students
Joshua Brule, Graduate Research Assistant, Computer Science*
Greg Davis, Graduate Research Assistant, Computer Science*
Dale Dullnig, Graduate Research Assistant, Computer Science
Theresa Hauge, Graduate Research Assistant, Kinesiology*
Di-Wei Huang, Graduate Research Assistant, Computer Science
Janakiraman Kirthivasan, Graduate Research Assistant, Robotic Engineering*
Josh Langsfeld, Graduate Research Assistant, Mechanical Engineering
Hyuk Oh, Graduate Research Assistant, Kinesiology
Charmi Patel, Undergraduate Research Intern, Computer Science
Dhwani H. Patel, Graduate Research Assistant, EE&CS, Syracuse University
John Purtilo, Undergraduate Research Intern, Computer Science
Jingxi Chen, Undergraduate Research Intern, Computer Science*
Alexandra Shaver, Graduate Research Assistent, Department of Kinesiology*
Vikas Shivashankar, Graduate Research Assistant, Computer Science
Isabelle Shuggi, Graduate Research Assistent, Department of Kinesiology*
Akshay, Graduate Research Assistant, EE&CS, Syracuse University*
Machines
Baxter
, Kinesiology, University of Maryland*
Poppy
, EE & CS, Syracuse University*
Tiger
, Mechanical Engineering, University of Virginia*
*currently/recently active participants
Project Overview
Manually programming robots to carry out specific tasks is a difficult and time consuming process. One approach to addressing this issue is to use imitation learning, or "learning by demonstration", in which a robot watches a person perform a specific task, and then the robot tries to perform the same or a similar task via imitation. Most past work on robotic imitation learning has focused on having a robot literally copy/duplicate the human demonstrator's actions without any deeper "understanding" of the demonstrator's goals and intentions. While this can be effective, it tends to not generalize well to even mildly novel situations or unexpected events, and its use with robots that are substantially different from the human demonstrator (six rather than two arms, non-humanoid, very large or very small, etc.) represents a very challenging barrier.
In this context, the primary overall goal of this research project is to create and critically evaluate a general-purpose neurocognitive architecture for imitation learning by an autonomous system. Our emphasis is on producing a robotic system that can learn bimanual arm movement control from a single demonstration, generalizing its actions much as a person does. We are also experimentally comparing our robotic learner to human subjects learning to carry out similar tasks. Our existing learning system, named CERIL, currently uses causal reasoning algorithms to construct plausible explanatory hypotheses for a demonstrator's actions during learning.
In the following, we first describe our Ongoing Work (2019 - present), and then give a more detailed summary of our past Previously Completed Work (2013-2018).
Ongoing Work (2019 - present)
The primary goal of our ongoing research is to develop a purely neurocomputational cognitive architecture for humanoid robots that supports high-level cognitive activities such as procedure learning, logical reasoning, goal-directed cognitive control, and planning. Our previous work successfully developed a cognitive robotic system (CERIL) for imitation learning of bimanual tasks, evaluated this system, and compared its abilities to those of human subjects learning to perform similar tasks from demonstrations. CERIL's cognitive-level functions are entirely based on symbolic AI programming methods. Past neurocomputational methods, including those used in deep learning systems, are simply not competitive with symbolic AI methods for such high-level cognitive tasks.
Our current approach is distinguished from past related work in its emphasis on cause-effect knowledge and plausible reasoning rather than deductive logic methods, its use of recurrent neural networks having itinerant attractor states that correspond to represented knowledge and actions, its focus on one-step Hebbian methods to quickly learn from limited data, its integration of short-term and long-term memory, its inspiration by human neuroanatomical organization and cognitive control mechanisms, and its incorporation of comparative studies of human subjects learning the same/similar tasks as the robot. To our knowledge, this work is the first effort to create an AI system for robotic imitation learning based on cause-effect reasoning that is completely directed by neurocomputational mechanisms, including its cognitive-level and executive components. Our ongoing work is focused on the following tasks.
Neural Virtual Machine
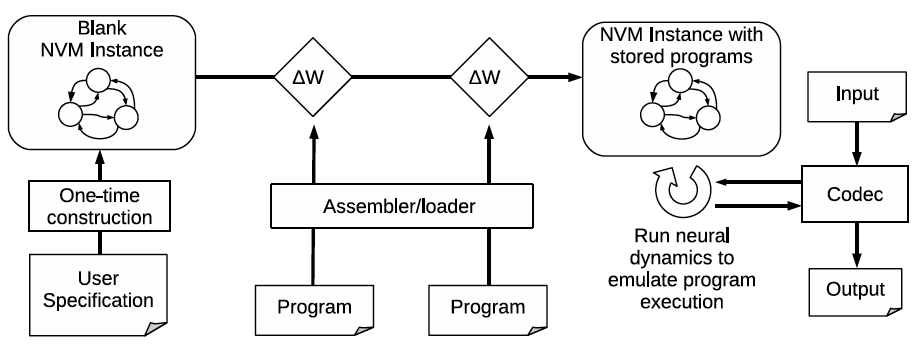
Our objective here is to create a neural virtual machine (NVM), a purely neurocomputational platform for implementing cognitive-level algorithms. Such algorithms are currently readily implemented via more traditional symbolic AI methods, but much less so via existing neural network methods. The idea is to then use the NVM to implement a neural version of CERIL. An initial, application-independent version of the NVM has been implemented and tested, verifying its functionality and demonstrating how different neural representations of symbolic components influence its performance [Katz et al., 2019a, 2019b].
The NVM's modeled knowledge and cognitive processes are acquired through a learning process and represented by distributed patterns of activity over an underlying neural substrate. From a user's perspective, to model a cognitive process using the NVM one writes assembly language level programs for a virtual machine that is emulated by the NVM (see the illustration; only two programs are shown here for illustrative purposes). In actuality, the NVM converts any given program into a region-and-pathway system of recurrently-connected neural networks that perform the indicated computations on distributed activity patterns representing symbols, based on the network's dynamics and synaptic weight changes. Innovations in the NVM include the use of learned itinerant attractor sequences to represent sequential cognitive states, top-down gating whereby high-level cognitive processes control the contents of working memory and task execution, and the use of very fast weight changes implemented via a store-erase Hebbian learning rule. A detailed description of the initial NVM with a link to an open-source implementation is available [Katz et al., 2019].
Our objective here is to use the NVM to implement a goal-directed, purely neurocomputational system for robotic imitation learning based on cause-effect knowledge. As the NVM has become available, we have started work on this task. The intent is to have the resulting system, whose cognitive-level mechanisms are modeled after those of CERIL (currently implemented in a Baxter robot; see figure at the right), be evaluated in multiple inspection and maintenance application domains to ensure generality. The needed causal knowledge is being authored using traditional, symbolic representations, but each symbolic token is then encoded as a distributed neural activity pattern by the NVM. The NVM can represent hierarchical data structures and causal networks.
The key components of CERIL that are being implemented using the NVM are a causal knowledge network, a causal inference algorithm (used during learning), and a planning algorithm (used during imitation). Building on the capabilities of the NVM, we currently have a preliminary implementation of the tree construction and traversal algorithms that are needed, and an initial implementation of information exchange between the NVM and an external environment. A key point here is that the modeled causal knowledge and cognitive processes are a learned virtual machine, represented by distributed patterns of activity over the underlying neural substrate, and are not built into this underlying neural hardware.
Human Subjects Doing Imitation Learning
Our objective here is to conduct experimental studies with human participants who learn the same tasks as the neuro-computational robotic system, as well as standard cognitive-motor tasks having similarly complex sequential actions. The intent is to determine the similarities/differences between humans and robots during learning, to gain insight into human imitation learning mechanisms, and to provide new ideas to incorporate into our robotic imitation learning system. Few studies have examined high-level motor plans underlying cognitive-motor performance during practice of complex action sequences, and these investigations have typically assessed performance through simple metrics without informing how practice affects the structures of action sequences.
In contrast, we have adapted a Levenshtein distance (LD) metric to the motor domain (based on differences between a subject's actions and a reference action sequence) to capture performance dynamics during practice of action sequences, combining it with mental workload metrics. For example, we used this approach on human subjects performing a Tower of Hanoi task, a well-known paradigm which requires one to generate a high-level motor plan for an action sequence that moves a stack of disks from one peg to another while constrained by permissiblity rules [Hauge et al., 2019]. We found that throughout practice this method could dynamically capture action sequence performance improvements as indexed by a reduced LD (decrease of insertions and substitutions), structural modifications of the high-level plans, attenuation of mental workload, and enhanced cognitive-motor efficiency. We are currently extending this approach to evaluate learning to carry out tasks with a mock disk dock drive (pictured on the right). The goal in this latter work is to directly compare human subjects and a Baxter robot controlled by CERIL.
Generalizing Robotic Imitation Learning
Our objective here is to explore the issues involved in porting our existing imitation learning system CERIL to other physical platforms. CERIL is currently only implemented on a single physical platform, a bimanual Baxter robot. We are accordingly investigating the issues involved in porting CERIL to a very different, custom-built robotic system. To do this we have established a collaborative effort with Tomo Furukawa's robotics research group at the University of Virginia with the goal of demonstrating a robotic system for inspection and maintenance tasks. Professor Furukawa's team is focused primarily on developing innovative but practical mobile robots as a potential alternative shipboard workforce. Combining CERIL with such robots should synergistically result in much more powerful systems for inspection and maintenance tasks relevant to naval applications.
As an initial test of this hypothesis, we are implementing the current version of CERIL on a Tiger-HDT robot developed at UVA (see picture at the right), integrating our imitation learning software with Tiger's existing robotic control software. This is quite challenging in that it involves the issue of how force feedback from torque and tactile sensors affects learning and control. While we are initially using the existing CERIL software, as the NVM is developed and tested we would like to also explore using neurocomputational modules in this context.
Complementary Basic Research
Driven by the needs of the above tasks, we are carrying on basic computational research about the cognitive mechanisms that are relevant to and underlie imitation learning. This has involved investigating the role of working memory mechanisms and how they can be modeled by purely neurocomputational methods [Reggia et al., 2019], including those in the NVM. We have also taken some steps towards understanding causal relations in general, which are the basis of imitation learning in CERIL [Brule 2019a, 2019b], and we are studying the use of directional fibers to characterize the dynamics of recurrent neural networks [Krishnagopal et al., 2019].
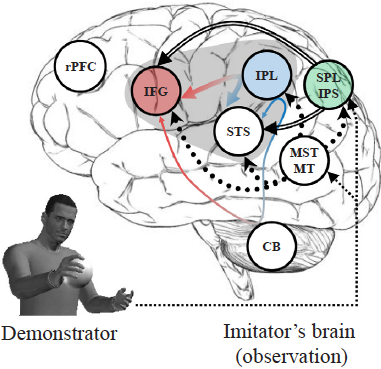
Finally, we have studied a neuroanatomically-constrained computational model of the visuospatial transformation processes that allow individuals to interpret and imitate actions observed from differing perspectives [Oh et al., 2019] (see illustration at the right). The model captures current knowledge about the dynamics the fronto-parietal mirror neuron system and visuospatial processes during observation and imitation of reaching and grasping actions. It includes representations of the inferior frontal gyrus (IFG), inferior parietal lobule (IPL), middle temporal (MT) region, middle superior temporal (MST) region, superior parietal lobule (SPL), and intra-parietal sulcus (IPS). Of great interest for development of robotic imitation learning, the model can imitate individual arm movement independently of demonstrator-imitator differences in anthropometry, distance, and viewpoint.
Selected Recent Publications (2019 - present)
Brule J. Whittemore: An Embedded Domain Specific Language for Causal Programming, in Beyond Curve Fitting: Causation, Counterfactuals, and Imagination-Based AI, AAAI Spring Symposium, March 2019a, Stanford, CA.
Brule J. Causal Programming, PhD Dissertation, Dept. of Computer Science, University of Maryland, May 2019b.
Hauge T, Katz G, Davis G, Jaquess K, Reinhard M, Costanzo M, Reggia J, Gentili R. A Novel Computational Approach for Assessment of Higher-Level Motor Planning Dynamics Underlying Performance During Practice of Complex Action Sequences, Journal of Motor Learning and Development, 2019, in press.
Katz G, Davis G, Gentili R, Reggia J. A Programmable Neural Virtual Machine Based on a Fast Store-Erase Learning Rule, Neural Networks, 119, 2019a, 10-30.
Katz G, Gentili R, Reggia J. Robotic Imitation Learning of Maintenance Tasks Using Causal Reasoning, SSC Pacific Workshop on Naval Applications of Machine Learning, San Diego, Feb. 2019b (abstract).
Krishnagopal S, Katz G, Girvan M, Reggia J. Encoding a Chaotic Attractor in a Reservoir Computer: A Directional Fiber Investigation, Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, IEEE, July 2019.
Oh H, Braun A, Reggia J, Gentili R. Fronto-Parietal Mirror Neuron System Modeling: Visuospatial Transformations Support Imitation Learning Independently of Imitator Perspective, Human Movement Science, 65, 2019, 121-141.
Patel, D, Empathy Based Reinforcement Learning, M.S. Thesis, Dept. of Electrical Engineering and Computer Science, Syracuse University, August 2019.
Reggia J, Katz G, Davis G. Modeling Working Memory to Identify Computational Correlates of Consciousness, Open Philosophy, 2, 2019, 252-269.
Previously Completed Work (2013 - 2018)
As elaborated below, some past accomplishments of this research project include:
Virtual Demonstrator Environment
The imitation learning process is simplified by using a virtual demonstration environment where the human demonstrator is effectively invisible to the learning robot.
Imitation Learning via Cause-Effect Reasoning
Cause-effect reasoning is used to infer the demonstrator's goals/intentions
rather than trying to literally replicate the demonstrator's arm movements.
Learning to Manipulate Non-Rigid Entities
Learning methods are developed for manipulating non-rigid entities, such as fluids and flexible manufacturing components, via dexterous bilateral arm movements.
Investigating Planning Methods
Methods are derived for integrating planning and acting,
and for exploring different hierarchical planning methods.
Learning Neural Control Methods
Neurocomputational methods are used to implement the control system for a robot's bimanual arm movements, including the cognitive aspects of the system.
The physical platforms used in this work include Baxter robots and a pair of Kuka arms.
Virtual Demonstrator Environment
We have developed a virtual demonstrator environment, SMILE
(Simulator for Maryland Imitation Learning Environment), in which a human demonstrator manipulates objects on a table to show a robot how to perform a task. The simulator implements basic physics in an artificial reality. SMILE's object interface also supports loading complex custom 3D models using external STL files (generated using CAD tools), and allows one to specify controls such as switches and lights using XML. Object templates and instances support variable substitutions, so that one can create different objects from the same template with different parameters.
Videos
The video on the left below illustrates creating a demonstration in a tabletop world
with toy blocks. The intent is to show a robot how to take randomly placed blocks and
use them to construct two structures shaped like the letters "U" and "M"
(for University of Maryland). The subwindow at the bottom right shows the observing
robot's view.
The video on the right below illustrates creating a demonstration related to device
maintainance. The device in this case is a mock-up of a disk drive dock cabinet.
The intent is for the robot to manipulate the dock drawer, and the disks and
toggle switches inside, to carry out various tasks (e.g., swapping a failing disk
marked by a red indicator light with a new one).
Toy Blocks Demo 1: Stack blocks to make "UM"
Disk Drive Dock Demo: Replace disk drive indicated by red LED
While most demonstrations created by SMILE are intended for export and use by physical robots,
it is possible to have fairly accurate simulated robots inside SMILE's artificial world,
as illustrated here with a Baxter robot.
The video on the left below illustrates creating a second demonstration in the toy blocks world,
again with the intent of constructing
two structures shaped like the letters "U" and "M".
The video on the right below shows how a simulated Baxter, introduced into the
artificial toy blocks world, can carry out the same task after seeing this
demonstration Demo 2.
Toy Blocks Demo 2: Stack blocks to make "UM"
Simulated Baxter Robot: Performs task within SMILE
Selected Publications
Huang, D., Katz, G., Gentili, R.J., Reggia, J. The Maryland Virtual Demonstrator Environment for Robot Imitation Learning. CS-TR-5039, Dept. of Computer Science, University of Maryland, College Park, MD, June 2014. (Superseded by CS-TR-5049, the next reference below.)
Huang, D., Katz, G., Gentili, R, Reggia, J. SMILE: Simulator for Maryland Imitation Learning Environment, Technical Report,
CS-TR-5049, Department of Computer Science, May 2016.
Huang D, Katz G, Langsfeld J, Gentili R, Reggia J. A Virtual Demonstrator Environment for Robot Imitation Learning,
Proc. Seventh Annual IEEE International Conference on Technologies for Practical Robot Applications (TePRA), 2015.
Huang D, Katz G, Langsfeld J, Oh H, Gentili R, Reggia J. An Object-Centric Paradigm for Robot Programming by Demonstration, Proc. Ninth International Conference on Augmented Cognition, Los Angeles, Lecture Notes in Computer Science 9183, Foundations of Augmented Cognition, Springer, D. Schmorrow and C. Fidopiastis (eds.), August 2015, 745-756.
Download SMILE
Visit our download SMILE web page
for further information about SMILE and to obtain an open-source copy.
Imitation Learning via Cause-Effect Reasoning
Our approach to general-purpose imitation learning takes the form of a cognitive robotic system named CERIL that learns from human demonstrations. The current implementation of CERIL learns to perform bimanual procedures based on representing the demonstrator's intentions, rather than on trying to replicate the observed actions verbatim. The robot's high-level reasoning during imitation learning is based on a knowledge base of cause-effect relations. During learning, a robot controlled by CERIL infers a hierarchical representation of a demonstrator's
intentions that explains why the demonstrator performed the observed actions.
This allows the learning robot to create its own plan for the same task, rather than focusing on duplicating the precise movements of the human demonstrator.
We have completed construction of the CERIL imitation learning system, and formalized the underlying algorithms, providing guarantees of their soundness and completeness, and analyzing their complexity. We also experimentally compared various criteria for what makes the system's explanation/interpretation of a demonstrator's actions plausible.
We evaluated the ability of a physical robot (Baxter from Rethink Robotics) to learn a series of maintenance tasks involving mock-ups of a disk drive dock and a pipe-switch-valve apparatus when using our algorithms. It can successfully generalize observed skills, as presented in SMILE demonstrations, involving bimanual manipulation of composite objects in 3D (examples in the videos below), deriving a suitable plan of action to carry out a demonstrated task in the situations we have tested so far. Our results indicate that the cause-effect reasoning approach we have introduced here can be an effective approach to cognitive-level imitation learning. Further, since cause-effect relations are involved, CERIL can support explaining why it performed actions in fairly intuitive ways.
Videos
These two videos show a Baxter robot, having observed the event records from
two of the SMILE videos given above, carrying out the corresponding demonstrated tasks.
The robot has learned the task in each case from a single demonstration. Note the
coordinated bimanual actions and that the robot
makes (quite limited at present) generalizations by starting from different
initial states.
The video on the left is based on learning from the SMILE blocks world demonstration Demo 1 above.
The video on the right is based on learning from the SMILE disk drive dock demonstration above (8x speed-up).
Toy Blocks Execution: Stack blocks to make "UM"
Disk Drive Dock Execution: Generalizes to a different faulty drive
Selected Publications
Katz G, Huang D, Gentili R, Reggia J. Imitation Learning as Cause-Effect Reasoning, Proceedings of the Ninth Annual Conference on Artificial General Intelligence (AGI-16), P. Wang & B. Steunebrink (Eds.), NYC, July 2016. Received Best Student Paper Award.
Katz G, Huang D, Hauge T, Gentili R, Reggia J. A Novel Parsimonious Cause-Effect Reasoning Algorithm for Robot Imitation and Plan Recognition, IEEE Transactions on Cognitive and Developmental Systems, 10, 2018, 177-193.
Katz G, Huang D, Gentili R, Reggia J. An Empirical Characterization of Parsimonious Intention Inference for Cognitive-Level Imitation Learning, Proc. 19th Intl. Conf. on Artificial Intelligence (ICAI 17), Las Vegas, July 2017.
Katz G, Davis G, Gentili R, Reggia J. Bidirectional Cause-Effect Reasoning as the Basis of Imitation Learning, RSS Workshop on Causal Imitation in Robotics, June 2018, Pittsburgh, extended abstract.
Katz G, Dullnig D, Davis G, Gentili R, Reggia J. Autonomous Causally-Driven Explanation of Actions, International Symposium on Artificial Intelligence, Las Vegas, Dec. 2017.
Hauge T, Katz G, Huang D, Reggia J, Gentili R. Development of a computational method to assess high-level motor planning during the performance of complex actions. Accepted. 18th NASPSPA Conference, 4-7 June 2017, San Diego, CA, USA.
Reggia J, Katz G, Davis G. Humanoid Cognitive Robots that Learn by Imitation, Frontiers in Robotics and AI, Humanoid Robotics Section, 5, Jan. 2018.
We have been developing learning methods for manipulating non-rigid entities, such as fluids and flexible manufacturing components, via dexterous bilateral arm movements.
One study has focused on a fluid pouring task, where a Baxter robot holds a bottle of water in its right hand and learns to pour the correct amount of water into a moving flask.
Our approach explores the task parameter space via local models to optimize appropriate movements.
Learning was highly effective, with successful parameter values for new task variations being found very quickly.
We have also developed an approach to automatic robotic cleaning of deformable objects having unknown stiffness characteristics.
A bimanual robot setup (KUKA arms) is used where one arm holds the part to be cleaned, while the other holds the cleaning tool. The robot quickly learns models of the part deformation depending on the cleaning force and grasping parameters, and to select the correct grasp location and tool parameters for rapid cleaning.
Videos
On the left, Baxter has learned a model for pouring fluids into a moving
container while minimizing the number of attempts needed to
successfully pour a new target volume.
After a set of random trials to construct the initial model, the robot is typically able to learn how to pour new volumes in just a handful of attempts.
On the right, a bimanual robot setup is used to clean deformable parts
without prior knowledge of the part stiffness characteristics. One
arm grasps the part while the other cleans. As the system gains
additional knowledge about that part's behavior, it optimizes both the
leaning parameters and where to hold the part to minimize the cleaning time.
Pouring Liquids into a Moving Container
Cleaning Flexible Parts
Selected Publications
Langsfeld, J., Kabir, A., Kaipa, K., Gupta, S. Online Learning of Part Deformation Models in Robotic Cleaning of Compliant Objects. ASME 2016 Manufacturing Science and Engineering Conference (MSEC), Blacksburg, VA, 2016.
Langsfeld, J., Kabir, A., Kaipa, K., Gupta, S. Robotic Bimanual Cleaning of Deformable Objects with Online Learning of Part and Tool Models. IEEE Conference on Automation Science and Engineering (CASE), Fort Worth, TX, 2016, submitted.
Langsfeld, J., Kaipa, K., Gentili, R., Reggia, J., Gupta, S.K. Incorporating Failure-to-Success Transitions in Imitation Learning for a Dynamic Pouring Task, Proc. IEEE International Conference on Intelligent Robots and Systems (IROS 2014) Workshop on Compliant Manipulation, Chicago, Sept. 2014.
Langsfeld, J., Kaipa, K., Gupta, S. Generation and Exploitation of Local Models for Rapid Learning of a Pouring Task. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Second Machine Learning in Planning and Control of Robot Motion Workshop, Hamburg, Germany, 2015
Langsfeld J, K Kaipa, and SK Gupta. Selection of Trajectory Parameters for Dynamic Pouring Tasks based on Exploitation-driven Updates of Local Metamodels. Robotica, 2017, in press.
Langsfeld J. Learning Task Models for Robotic Manipulation of Non-rigid Objects. PhD Dissertation, University of Maryland, College Park, USA, 2017.
Investigating Planning Methods
The planning component of our neurocognitive architecture needs to operate in environments that are open-world, partially observable and dynamic.
We developed a new knowledge-based planning formalism called Hierarchical Goal Network (HGN) planning to explore addressing these issues. Our HGN planning algorithm uses arbitrary amounts of planning knowledge, but falls back on domain-independent planning techniques to fill in gaps. We also developed a formalization of acting, the Refinement Acting Engine, and studied its integration with ongoing planning.
Selected Publications
Alford, R., U. Kuter, D. S. Nau, and R. P. Goldman. Plan aggregation for strong-cyclic planning in nondeterministic domains. Artificial Intelligence 216, 206 - 232, Nov. 2014.
Ghallab, M., Nau, D., Traverso, P. The Actor's View of Automated Planning and Acting, Artificial Intelligence, 208, 2014, 1-17.
Ghallab, M., Nau, D., Traverso, P. Automated Planning and Acting. Cambridge University Press, Cambridge, UK. 2016.
Ivankovic, F., P. Haslum, S. Thiebaux, V. Shivashankar, and D. Nau. Optimal planning with global numerical state constraints. In International Conference on Automated Planning and Scheduling (ICAPS), June 2014.
Nau, D., Ghallab, M., Traverso, P. Blended Planning and Acting: Preliminary Approach, Research Challenges, Proceedings of the 29th AAAI Conference on Artificial Intelligence, 2015.
Nau D, M. Ghallab, and P. Traverso. Refinement planning and acting. In Conf. on Advances in Cognitive Systems, May 2017.
Shivashankar, V. Hierarchical Goal Networks: Formalisms and Algorithms for Planning and Acting, PhD Dissertation, University of Maryland, College Park, May 2015.
Shivashankar, V., Kaipa, K., Nau, D., Gupta, S. Towards Integrating Hierarchical Goal Networks and Motion Planners to Support Planning for Human-Robot Teams, Proceedings of the IROS Workshop on AI and Robotics, Sept. 2014.
Shivashankar, V., Alford, R., Kuter, U., Nau, D. Hierarchical Goal Networks and Goal-Driven Autonomy: Going where AI planning meets goal reasoning, ACS Workshop on Goal Reasoning, Annual Conference on Advances in Cognitive Systems, 2013, 95-110.
Learning Neural Control Methods
We are studying the use of neurocomputational methods to implement both trajectory control and cognitive control for a robot's bimanual arm movements.
For example, we have evaluated a neural architecture that captures the visuo-spatial transformations required for the cognitive processes of mental simulation and imitation. Our model involves movements with 7 degrees of freedom arms towards targets in a 3D workspace while producing human-like kinematics.
It performed accurate, flexible and robust bimanual reaching movements while avoiding extreme joint positions under various conditions.
We also showed how, using these methods, the mechanical dependencies existing between finger joints can be accommodated in controlling robots with mechanically inter-dependent joints.
Complementary work has developed self-organizing maps (SOMs) that use limit cycles to represent external input sequences instead of the static encoding representations of past SOMs. This fundamental change in representation is more consistent with the oscillatory nature of brain activity.
We used this approach to build a combined open-loop, closed-loop multi-map neurocontroller for a Baxter robotic arm, as illustrated below, demonstrating that even though activity is constantly oscillating in the neural network controller the robot can perform fixed-point arm reaching tasks.
Finally, we are studying how to implement cognitive control of sequential behaviors with attractor neural networks in which the control neural modules act by gating the activity and learning of other neural modules.
This approach was used successfully to solve sequential card matching problems, and was found to match the performance of human subjects on such tasks. Finally, we introduced a new method, directional fibers, for identifying the fixed points of the dynamics of recurrent neural networks.
Video
A very short demonstration of how a limit-cycle SOM neural network can smoothly
direct a robot's arm trajectory to a fixed location and maintain it steady there
in spite of ongoing oscillatory activity in the neural networks.
Neural Net Arm Control:
Arm moves to a fixed position in spite of oscillating neural net activity.
Selected Publications
Gentili R, Oh H, Huang D., Katz G, Miller R, Reggia J. Towards a Multi-Level Neural Architecture that Unifies Self-Intended and Imitated Arm Reaching Performance, Proc. 36th Annual International Conf. of the IEEE Engineering in Medicine and Biology Society, August, 2014, 2537-2540.
Gentili R, Oh H, Kregling A, Reggia J. A Cortically-Inspired Model for Inverse Kinematics Computation of a Humanoid Finger with Mechanically-Coupled Joints, Bioinspiration and Biomimetics, IOP Press, 11, 2016, 036013.
Gentili R, Oh H, Miller R, Huang D, Katz G, Reggia J. A Neural Architecture for Performing Actual and Mentally Simulated Movements During Self-Intended and Observed Bimanual Arm Reaching Movements, International Journal of Social Robotics, 7 (3), 2015, 371-392.
Huang D. Self-Organizing Map Neural Architectures Based on Limit Cycle Attractors, PhD Dissertation, August 2016.
Huang D, Gentili R, Katz G, Reggia J. A Limit Cycle Self-Organizing Map Architecture for Stable Arm Control, Neural Networks, 85, 2017, 165-181.
Huang D, Gentili R, Reggia J. Limit Cycle Representation of Spatial Locations Using Self-Organizing Maps, Proc. of the IEEE Symposium Series on Computational Intelligence (SSCI), Dec. 2014.
Huang, D., Gentili, R., Reggia, J. Self-Organizing Maps Based on Limit Cycle Attractors, Neural Networks, 63, 2015, 208-222.
Huang D, Gentili R, Reggia J. A Self-Organizing Map Architecture for Arm Reaching Based on Limit Cycle Attractors, Proc. Ninth Intl. Conference on Bio-Inspired Information and Communication Technology (BICT 2015), New York City, Dec. 2015.
Katz G, Huang D, Gentili R, Reggia J. An Empirical Characterization of Parsimonious Intention Inference for Cognitive-Level Imitation Learning, Proc. 19th Intl. Conf. on Artificial Intelligence (ICAI 17), Las Vegas, July 2017.
Katz G, Reggia J. Applications of Directional Fibers to Fixed Point Location and Non-Convex Optimization, Proc. 16th Annual Conf. on Scientific Computing, Las Vegas, August 2018.
Katz G, Reggia J. Using Directional Fibers to Locate Fixed Points of Recurrent Neural Networks, IEEE Transactions on Neural Networks and Learning Systems, 29. 2018, 3636-3646.
Oh, H. A Multiple Representations Model of the Human Mirror Neuron System for Learned Action Imitation. PhD Dissertation, University of Maryland, College Park, Dec. 2015. Advisor: R. Gentili. http://drum.lib.umd.edu.
Oh H, Braun A, Reggia J, Gentili R. Role of Visuospatial Processes During Observational Practice, North American Society for Psychology of Sport and Physical Activity, Montreal, 2016.
Reggia, J., Monner, D., Sylvester, J. The Computational Explanatory Gap, Journal of Consciousness Studies, 21 (9), 2014, 153-178.
Reggia J, Huang D, Katz G. Exploring the Computational Explanatory Gap, Philosophies, 2, 5, 2017.
Sosis B, Katz G, Reggia J. Learning in a Continuous-Valued Attractor Network, Proceedings of the IEEE International Conference on Machine Learning and Applications, Orlando, December 2018.
Sylvester J, Reggia J. Engineering Neural Systems for High-Level Problem Solving, Neural Networks, 79, 2016, 37-52.


 , EE & CS, Syracuse University*
, EE & CS, Syracuse University* , Mechanical Engineering, University of Virginia*
, Mechanical Engineering, University of Virginia*