Departments: Computer Science, Kinesiology
Programs: UMIACS, NACS, Maryland Robotics Center
Supplemental Information
The information below is intended to supplement
A Novel Parsimonious Cause-Effect Reasoning Algorithm: Implementation for
Robot Imitation and for Plan Recognition
G. Katz, D. Huang, T. Hauge, R. Gentili, J. Reggia; 2016, under review
which we refer to as simply "the paper" in the following.
The material is organized into several sections:
Videos
Illustrate robotic imitation learning from a single demonstration using cause-effect reasoning.
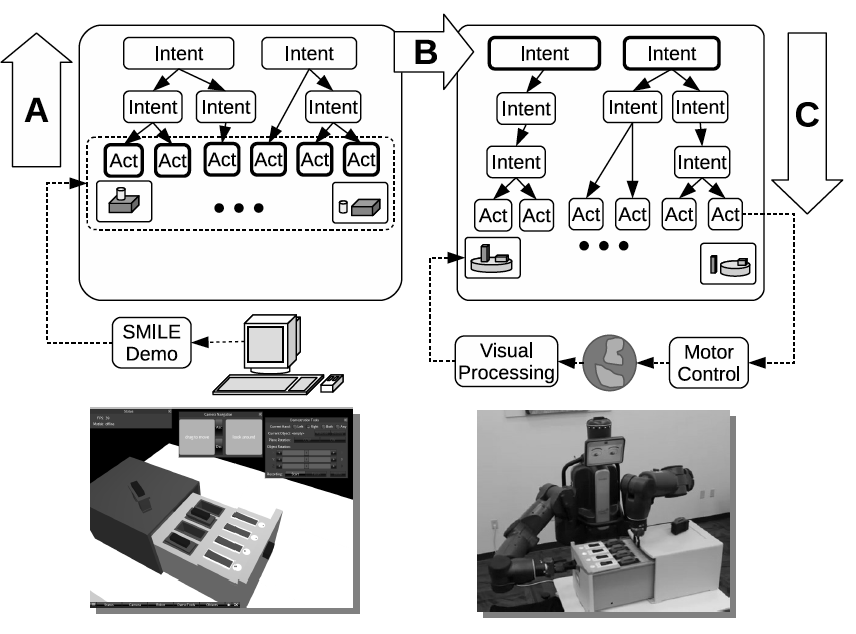
As described in the paper, our approach to general-purpose imitation learning is based on cause-effect reasoning.
During learning, a robot infers a hierarchical representation of a demonstrator’s intentions that explains why the demonstrator performed the observed actions.
This allows the learning robot to create its own plan for the same task, rather than focusing on duplicating the precise movements of the human demonstrator.
Here we present two pairs of videos to illustrate how a physical robot (Baxter from Rethink Robotics)
can learn simple tasks by using our algorithms.
In each case, a demonstration is created in a virtual world using the software environment named
SMILE.
The event record from this demonstration is given to the robot, which interprets the demonstration
and then can act upon a similar real physical environment task.
To a limited extent, the robot can successfully generalize observed skills presented in SMILE demonstrations, as illustrated in the videos below, deriving a suitable plan of action to carry out the demonstrated task.
Our work currently focuses on tasks involving bimanual manipulation of composite objects in 3D.
The first two videos give an example of a Baxter robot learning to replace disk drives, a
task that we used to evaluate the causal reasoning algorithms described in the paper.
The video on the left illustrates using SMILE to create a demonstration related to device
maintainance. The device in this case is a mock-up of a disk drive dock cabinet.
The intent is for the robot to manipulate the dock drawer, and the disks and
toggle switches inside, to carry out various tasks (e.g., swapping a failing disk,
marked by a red indicator light, with a new one).
The video on the right shows the Baxter robot, having learned this task from a single
demonstration, executing the task in the physical world. Note that in the video, the robot
encounters an initial physical state that
is somewhat different than that in the demonstration (a different disk
is replaced), and that the robot uses coordinated bimanual actions in opening/closing
the dock drawer and in passing a disk from one hand to the other.
Disk Drive Dock Demo: Replace disk drive indicated by red LED
Disk Drive Dock Execution: Generalizes to a different faulty drive
The second pair of videos, shown below, illustrate our approach in a different domain,
that of stacking up toy blocks to form simple structures.
The video on the left below illustrates creating a SMILE demonstration
with the toy blocks. The intent is to show a robot how to take randomly placed blocks and
use them to construct two structures shaped like the letters "U" and "M"
(for University of Maryland). The subwindow at the bottom right shows the observing
robot's view.
The video on the right below illustrates our Baxter, having observed the event record from
the demonstration, carrying out the corresponding demonstrated task. Note that the
initial arrangement of the blocks that it starts with is different from what was used
in the demonstration: The learned task has been generalized.
Toy Blocks Demo: Stack blocks to make "UM"
Toy Blocks Execution: Stack blocks to make "UM"
The Dock Maintenance Domain
Listed here are the core causal intention relations defined in our dock maintenance knowledge base
that was used to evaluate algorithm EXPLAIN,
tailored to the Baxter robot. Each causal relationship is written
with a "==>" symbol, a right arrow that represents "causes", not logical implication.
In some cases, the same cause can have multiple possible effect sequences.
Three asterisks "***" are used to indicate the "intentions" that are considered directly observable as actions in the SMILE event transcript. The relations are ordered roughly from lowest-level to highest-level.
This list of causal relations is meant to paint a concrete picture of how much knowledge is built into our system, but the following details are omitted from the list for clarity of presentation.
Specifically, the "==>" symbol masks certain non-trivial operations necessitated by physical robot execution, as follows:
The plan-arm-motion relation invokes a motion planner to convert end-effector targets in 3D space to joint angle trajectories that avoid obstacle collisions. Grasping and putting down objects must incorporate geometric transformations describing the grasped object pose relative to the end-effector and relative to the destination, and must test for collisions when selecting which grasp pose to use for the manipulated object. Disk drive hand-offs require three trades between grippers, during which the drive is gripped on its side, since the robot's arms are too thick for both grippers to be simultaneously positioned near the handle.
move-grasped-object includes a special branch for inserting drives into slots, since it is a fine motor skill that requires a special motor planning and execution routine. This distinction is not made in SMILE output.
move-unobstructed-object moves an object to either another destination object or to one of the arms. It assumes that one or both grippers are free as necessary and may or may not perform hand-offs depending on which arms can reach the source and destination positions.
move-object clears any grippers as necessary so that the unobstructed movement can be achieved. This requires identification of a free spot in the environment during plan execution where currently gripped objects can be placed down so that the grippers are clear, which is accomplished using a simple search strategy of the suitability of a set of candidate free spots.
Parameters of the parents cannot simply be propogated to the children; the full causal relation is complex and non-deterministic. These complex relationships are accounted for in the CAUSES function when it processes a sequence of child intentions. There are also auxiliary causal relations necessary for physical execution but not modeled in CAUSES since they would not be observed in SMILE. In particular, several listed intentions include unshown children for visual processing routines that are interleaved with planning and execution, such as inspecting the dock slots and LEDs after the drawer is opened and updating the object matching.
The Monroe County Emergency Response Domain
The Monroe County Corpus is a well-known benchmark data set from the field of plan recognition
[Blaylock, N., Allen, J.: Generating Artificial Corpora for Plan Recognition. In: Ardissono, L., Brna, P., Mitrovic, A. (eds.) User Modeling 2005, LNAI, vol. 3538, pp. 179-188. Springer, Edinburgh (2005)].
This corpus is based on an HTN planning domain for emergency response in a county in upstate New York.
Top-level goals, such as clearing a car wreck or repairing a power line, are accomplished through sequences of lower-level tasks such as navigating a snow plow or calling a power company.
The corpus consists of 5000 planning examples, each of which is the HTN plan tree for a randomly chosen top-level goal in a randomly generated initial state. The following is an example entry
taken verbatim from the corpus:
The latter sequence is an example of what is used as inputs to our EXPLAIN algorithm
during its evaluation.
We refer to the top-level goals in the examples as the "original" or "ground-truth" top-level goal.
Partial State Reconstruction
As seen in the example above, the initial and intermediate states used when originally generating the HTN plan trees are not retained in the corpus. However, these states often contain important information that is necessary to uniquely determine parent tasks for an observed child sequence. Fortunately, the states can be partially reconstructed as follows.
Each operator in the domain definition includes a list of preconditions, which specifies propositions that must be true in the state immediately before the operator is applied.
The actions also include add and delete lists which specify propositions that become true or false in the state immediately after the action is applied.
For example, the
(!navegate-vehicle ?person ?veh ?loc) operator has the following signature:
The preconditions enforce constraints such as the person and vehicle being colocated; the add and delete lists change their location from the source to the destination. Leveraging this knowledge base, an automatic procedure can be used to traverse the HTN plan tree in any test example, adding and removing propositions in each state along the way, according to the planning operator definitions. We used this approach as a pre-processing step to generate sequences of partial states to accompany each testing example in the dataset. For instance, the following partial states were reconstructed for the HTN plan tree example given above:
Each state was paired with its corresponding low-level action, according to the intention formalization described in the paper, before being passed as input to EXPLAIN.
Monroe County Domain Causal Relations
The causal relations used in the Monroe County Domain are paraphrased below, using the same notation as
for the disk drive dock domain described above.
Most of these causal relations have preconditions that are not shown to make these relations more readable: the parent task can only cause its children when certain preconditions are satisfied in the current state. Moreover, several parent tasks have parameters that do not occur in the parameter lists of the children, and can only be inferred by inspecting the accompanying state. This logic is included in our implementation of CAUSES for the Monroe Domain, but omitted below for ease of presentation.
As explained in the paper,
there is a small collection of anomalous examples in the Monroe County corpus, where the parameters of child tasks seem to conflict with the parameters of their parents. For example, the 1542nd example is:
The first GET-TO seeks to move CCREW1 to HENRIETTA-DUMP, but its sub-tree apparently gets CCREW1 to PITTSFORD-PLAZA. The plaza is in Pittsford, not Henrietta; and it's not in Rochester either, where ROCHESTER-GENERAL is. So these actions do not seem to accomplish the top-level goal, and the propogation of parameters from parent to children does not seem to match the method schema in the domain definition. At least two other examples are similar: 1298 and 2114. They seem to involve a common pattern of
(GET-TO
(GET-TO ...)
(GET-IN ...)
(GET-OUT ...))
where a crew simply gets in and out of a vehicle without navigating anywhere else.
Human Experiments
Our initial experimental testing of EXPLAIN as described in this paper
assumed that the disk drive dock and toy blocks experiments were sufficiently
simple that a person could learn to do them from a single demonstration
(and thus it is not unreasonable to aspire to have a robot do so too).
We tested a small number of human subjects, individuals who were unfamiliar with this
research project, to determine whether or not this assumption is reasonable.
Specifically, experimental work with five human participants was conducted to
assess to what extent they were able to perform, after a short demonstration,
disk drive dock maintenance and block stacking tasks very similar
to those the robot is required to learn. The participants were all
right-handed healthy individuals, and we followed procedures approved by
the Institutional Review Board of the University of the Maryland-College Park.
The tasks were demonstrated to the participants via SMILE-generated
videos (one per task) on a computer screen.
Immediately after watching each video, the participants had to physically (i.e.,
with real physical objects as was done by the robot) imitate what they previously
observed under slightly different initial conditions, just as was done by the
robot. Their performance was recorded with a camera. Each demonstration was presented
five times and the order of the tasks was counterbalanced for all the participants.
For each task and trial, the number of trials needed to successfully complete
the task was recorded.
The content of the videos used for these experiments was as follows.
Two videos showed a task that involved opening the docking station described in the
paper to move disk drives around. The first demonstrated the replacement of a
damaged hard drive by a new one, while the second showed the swapping of two drives.
After each video, the participants imitated the action previously demonstrated by
physically manipulating the same docking station and disks placed on the table in
front of them. While the hard drives to replace/swap were the same in the demonstrated
task and during the physical imitation task, the states of the other hard drives were
different between the video demonstration and the imitation. This allowed us to assess,
in only a very limited way, the generalization capabilities of human imitation.
Two other videos showed a task that stacked red and blue wooden blocks to build
a “UM” shape. The first included a simple color pattern (the letter 'U' made of all
blue blocks, and the letter 'M' made of all red blocks),
whereas the second incorporated more complex color patterns (each letter was built
with a mixture of both red and blue blocks). After each video, the participants
imitated the actions previously demonstrated by physically manipulating the same
red and blue wooden blocks that were spatially distributed on a table in front of them.
The spatial distribution of the physical blocks was different from that shown in the
corresponding demonstration videos that were made with SMILE, and two extra blocks were provided,
again allowing for some very limited assessment of generalization capabilities.
The results revealed that the human participants were usually but not always
able to imitate these four tasks after seeing just a single demonstration.
Specifically, for the two disk drive dock maintenance tasks, in 9 out of
the 10 trials the human participant successfully imitated the task after
viewing the videos once. In the remaining trial, the participant only imitated
the demonstrated task correctly after viewing the video three times.
Similarly, for the two block stacking tasks, in 8 out of the 10 trials
the human participants successfully imitated the task after viewing the videos once.
In the remaining two trials, all participants correctly performed the task
after viewing the videos twice.