CMSC 412 (shankar, exam 2, dec 6, 1994)
SOLUTION
1. [6 pts]
a. LRU 1 2 3 4 2 1 5 2
F F F F H F F H # faults 6
1 2 3 4 2 1 5 2 final contents in order: 2, 5, 1
1 2 3 4 2 1 5
1 2 3 4 2 1
b. FIFO 1 2 3 4 2 1 5 2
F F F F H F F F # faults 7
1 2 3 4 2 1 5 2 final contents in order: 2, 5, 1
1 2 3 3 4 1 5
1 2 2 3 4 1
c. The optimal replacement policy yields least number of faults.
OPTML 1 2 3 4 2 1 5 2
F F F F H H F H # faults 5
1 2 3 4 4 4 5 5 final contents: 5, 2, 1 or 5, 2, 4
1 2 2 2 2 2 2
1 1 1 1 1/4 1/4
2. [6 pts]
-
Install a faster CPU. C. Cpu will now take even less time to execute before
page fault.
-
Install a bigger paging disk. C. Won't make any difference.
-
Decrease the degree of multiprogramming. A. Gives more memory per process,
thus fewer page faults/proc. Note that other i/o devices are not bottleneck.
-
Install more main memory. A. Gives more memory per process, thus fewer
page faults/proc.
-
Install a faster paging disk disk. A. Less time handling page faults.
-
Add prepaging to the page fetch algorithms. B. May decrease the disk service
time, leading to ``faster'' disk.
3. [5 pts]
-
a.
-
21 disk accesses needed to read block 20, since i+1 accesses are
needed to read block i.
-
b.
-
102 or 103 disk accesses needed: [ 1 to read head of free list (and update
free list ptr to next block) ] + [ 100 to get next ptr in block 99 ] +
[ 1 to update next ptr and write back block 99 ] + [ 1 to write new block
(OPTIONAL) ].
4. [5 pts] Assume that for each dir/file accessed, the desired
info is in block 0.
-
a.
-
8 accesses: /.inode + / + usr.inode + usr + adam.inode + adam + hw.inode
+ hw.
-
b.
-
12 accesses: /.inode + / + u.inode + u + sue.inode + sue + usr.inode (assuming
/ still cached) + + usr + adam.inode + adam + hw.inode + hw.
5. [5 pts] 4M messages sent from one write to the next
write.
Just prior to a write, there are M remote copies. WRITE does
following: sends M invalidate messages, waits for M acks,
does write, and return. Each READ by cpu i does following: cpu i
sends read copy request, and cpu 1 sends read copy. Thus 2 messages per
read, thus 2M messages for M reads.
6. [6 pts]
v addr vp# (leftmost two hex digits and leftmost two bits of next hex digit)
in bits in decimal
0x 023FE 0010 00 2*4 = 8
Ox 031FD 0011 00 3*4 = 12
Ox 022A0 0010 00 2*4 = 8
0x 01570 0001 01 1*4 + 1 = 5
0x 02F01 0010 11 2*4 + 3 = 11
0x 01F00 0001 11 1*4 + 3 = 7
7. [7 pts]
-
a.
-
For N = 1: cpu utilization =
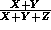 and T = X+Y+Z.
and T = X+Y+Z.
For arbitrary N < 100, cpu utilization = 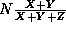 and T = X+Y+Z. (So for N = 10, cpu utilization
=
and T = X+Y+Z. (So for N = 10, cpu utilization
= 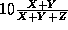 and T = X+Y+Z.)
and T = X+Y+Z.)
-
b.
-
N=1 case is same as in part a.
N=10 case is a bit more complicated. Note that the disk is the
bottleneck. Processes will always be queued there. Once every Z
seconds a process finishes its disk io, goes to the cpu, stays for X+Y,
and then rejoins the disk queue. Z seconds after the last departure
from the disk, another io request is completed, and the cycle is repeated.
So for any N > 1: the cpu executes once every Z seconds;
and process 1 comes back to the cpu once every N*Z seconds.
Thus cpu utilization =
and T = N*Z (or 10Z for N=10).
-
c.
-
The assumption in part a is more realistic. It is true that the disk can
serve only one request at a time. However, the disk- process typically
uses a non-FIFO discipline (e.g. elevator, scan, etc.). The net effect
is that the disk response time increases sublinearly with N and
is almost constant for small N. [If this were not true, there would
be no point in multiprogramming.]
8. [5 pts]
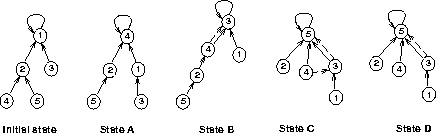
9. [5 pts] Each cpu i maintains a local queue of waiting
cpu ids, instead of the next pointer. The last pointers are
handled as before.
Upon reception of a request, if last = i and status(i) 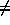 thinking then add request to local queue; else if last = i and status(i)=thinking
then send a message containing the page and an empty queue to the requester.
thinking then add request to local queue; else if last = i and status(i)=thinking
then send a message containing the page and an empty queue to the requester.
Upon completion of access to page, if queue
empty then send a message containing the page and the queue to the first
cpu in the queue, and set the queue to empty.
Upon reception of message containing page and queue, add the received
queue to the local queue ahead of entries already present.
A. Udaya Shankar
Thu Nov 19 13:18:08 EST 1998