Integrating Heterogeneous Data Sources: Certain obvious advantages exist in being able to integrate information across multiple data sources. Clearly, such an integration alleviates the burden of duplicating the data gathering efforts. More importantly however, is that it enables the extraction of information that would otherwise be impossible. As examples, law enforcement agencies such as Interpol would benefit from having the ability to access databases of various national police forces, to assist their efforts in fighting international terrorism, drug trafficking, and other criminal activities. Insurance companies, using data from external sources including other insurance companies and police records, can identify possible fraudulent claims. Medical researchers and epidemiologists, having access to records across geographical and ethnic boundaries, are in a better position to predict the progression of certain diseases. In each case, the information extracted from the diverse sources would not have been possible had the data sources been viewed in isolation.
Integrating Heterogeneous Reasoning Paradigms: In conjunction with the ability to integrate a variety of data sources is the need to integrate diverse forms of reasoning. Access to such reasoning systems provides mediators with sophisticated abilities to extract and produce new information from existing data. As a simple example, consider the problem of terrain reasoning [3] used to analyze the terrain of a given region, which can be used to optimize the deployment of certain resources (e.g. defensive weapons systems, first aid centers, etc.) over the region. This region may be part of a ``rogue'' nation developing nuclear or chemical weapons. It may also be the terrain of a planet such as Mars or Venus. The resources deployed may be defensive weapons or scientific observation equipment. Determining where these resources can be physically situated requires access to multiple terrain databases containing information about soil structure, vegetation maps, elevation maps, and road maps. In addition, the deployment strategy may require reasoning over certain properties that involve numerical optimization of an objective function, and the actual movement of the resources from their current locations to their destinations may use another reasoning method that incorporates route planning. Hence the availability of two reasoning techniques in this case is critical in the successful extraction of a deployment plan over several data sources. More generally, solutions to complex problems require integrating multiple forms of reasoning that may include logical inference, numerical optimization, planning, pattern recognition, scheduling, and learning.
Our Contributions: The aim of the system described in this paper is to take the first steps towards the development of a principled methodology for integrating multiple data sources and reasoning systems, and to propose a mediator language within which access to the data sources and reasoning systems can be expressed uniformly. There are two important aspects to constructing a mediator: domain integration and semantic integration . Intuitively, domain integration is the physical linking of the data sources and reasoning systems, while semantic integration is the coherent extraction and combination of the information provided by the data and reasoning sources, serving a given purpose.
Previous approaches to software integration have generally used relatively ad-hoc coding methods. Extending such a system with new software presents formidable challenges for various reasons. The process through which a new domain may be integrated into our mediated system on the other hand, follows a simple sequence of steps. Indeed, certain of these steps can even be automated, and a set of integration toolkits have been designed for further simplifying the integration process. (One of us (Robert Ross) integrated Paradox into the existing mediated system in under 60 hours using the above methodology.) One reason for our ability to integrate new softwares with relative ease is due to the clean separation of the domain integration phase from the semantic integration phase described below.
Each of domain integration and semantic integration entails conceptually very different sets of activities. In the former case, the knowledge to perform the required set of activities includes system dependent information, such as details needed to access the pre-existing functions of a specific database/software package. In the latter case, the implementor must have a clear understanding of the application requirements of the resulting mediated system. Examples include law enforcement or terrain reasoning. The primary purpose of the implementor -- called the mediator author -- in this case is to build a system that satisfies the application requirements. Clearly, the mediator author should be able to perform this task from the logical perspectives of the application, without having to concern him/herself with the details of how information is extracted from each of the data and reasoning sources. It is this observation that prompts us, in our system, to clearly delineate the domain integration phase from the semantic integration phase. This is in sharp contrast to existing mediated systems, where there is typically no clear logical separation between the code that performs the mediation, and the code that accesses the data sources required to carry out the mediation. From a software engineering perspective, our approach gains the important advantages of modularity and abstraction, since packages are incorporated into the larger system independently of specific mediation tasks. To the actual mediating code, domains/packages are treated as abstract entities whose internal details are hidden, and mediating code may be written without being concerned about how different domains can be, or have been, integrated.
The language that we use for writing semantic integration code is rule-based, and hence is declarative. For instance, suppose an integration is to be performed between a database DB1 , stored in Borland's Paradox DBMS, and a database DB2 , stored in DBase V. The language offers mechanisms to extract the data in DB $ and DB2 in a systematic way. The data can then be logically combined in a semantically meaningful way. Note that the semantics of the combined data may contain conflicts, which can be resolved naturally through our language. In addition, the combined data may be used to define new derived operations based on one or more compositions of the operations in the original databases DB1 and DB2 . These new operations can subsequently be used to specify additional new operations. A query processing engine for the language is under development.
Our system contains a yellow pages facility to assist the mediator author in locating data sources. As more domains are incorporated into our system, this facility will prevent the mediator author from having to manually navigate through the potentially complex maze of data sources. Interestingly, the yellow pages server is not all that different from other domains being integrated. Indeed, they may be regarded as domains as well. We will show how the mediator language may access and query yellow-page servers, and how the databases indicated by these yellow pages servers may then be queried for the desired information.
It is possible to couple actions to the results of query
processing. Thus, the result of executing a given query, and
obtaining an answer
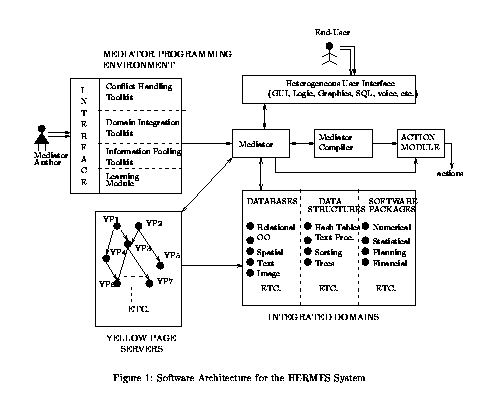
The principle result of our work is a piece of software that can currently be seen at the University of Maryland. An initial release is expected by anonymous ftp in the Spring of 1995. The system conforms to the software architecture shown in Figure 1, which provides a pictorial sketch of the ideas discussed in this paper. At present, two versions of the system exist, one on the IBM-PC platform running under DOS/Windows 3.1, and one on the SUN/Unix platform running under XWindows. The PC version currently integrates the following.
The system, even in its current experimental form, has been applied to the two tasks below. Other applications are being researched and developed.