In the optimizer that I have implemented there are four distinct phases - local optimization, global constant propagation, loop-invariant code motion and dead code elimination. The fifth optimization - unreachable code elimination is implemented locally with each of the other optimizations.
In general, doing dead code elimination the last would be a good idea, based on the assumption that since users do not generally write dead code, it would be wasteful doing that earlier. Other optimizing passes might lead to generation of some dead code.
On the given set of benchmark programs, I performed a sequence of experiments, in which I varied the order in which the optimizations were performed, and also the number of optimizations performed.
All optimization passes that I tested the code with, produced correct code, in as much that it gives the output as the un-optimized code.
Below, I show the results of the following optimizations (the name in parentheses represent the name used in the tables for each optimization order) -
Results for all the sequence of optimizations that I tried is in the appendix, but below I present a few of the interesting optimization orders.
Result of each optimization tried individually (except dead code elimination, since dead code elimination by itself is not so interesting)
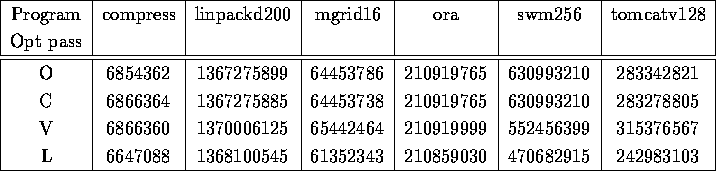
Number of instructions executed

Number of SimpleSUIF instructions generated as compiler output
From these tables it can be seen that clearly loop-invariant code motion is a very powerful optimization technique. This manages to produce a good amount of optimization for most of the programs. Local optimization managed to improve performance of swm256 in particular. Global constant propagation did not enhance performance much, when used solely by itself. Since, most of the program life time would be spent inside loops (straight lines of code, would not run for very long, the number of SimpleSUIF instructions for the largest of the above programs is 6317), optimizing loops is thus a very good way to optimize programs.
To show that dead code elimination indeed is an useful postphase for most optimizations, let us compare data in the following table.

Number of instructions executed
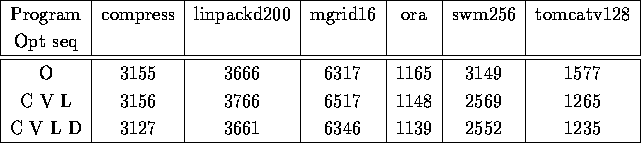
Number of SimpleSUIF instructions generated as compiler output
C V L : C followed by V followed by L
C V L D : C followed by V followed by L followed by D
Note, in all cases, the extra post phase of dead code elimination reduced the number of SimpleSUIF instructions and also reduced the number of instructions executed.
The next table compares the performance of these programs for some interesting orders of the optimization sequence.
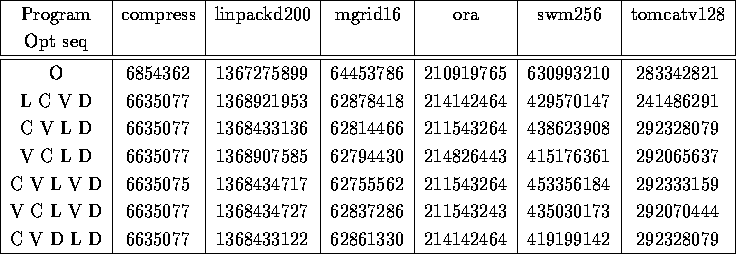
Number of instructions executed
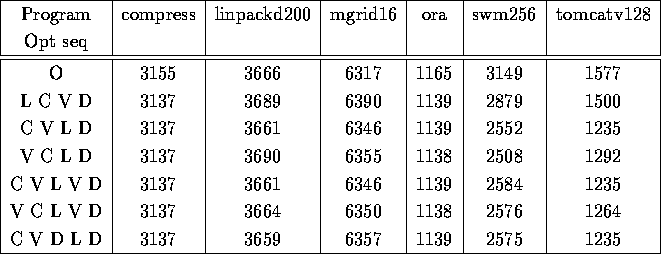
Number of SimpleSUIF instructions generated as compiler output
From the above table it can be seen that among the optimization passes, performing loop-invariant code motion first does not provide the most optimized code. In most cases, (4 out of 6), the best optimization sequence is global constant propagation followed by local optimization followed by loop-invariant code motion and terminated by dead code elimination gives the best results.
I also tested multiple passes of some of the optimizations. An exhaustive set of results is listed in the appendix. But, it can be seen from the above table, that multiple passes of local optimizations and that of dead code elimination is pretty useful. In particular, if local optimization is done first, then another pass of local optimization after doing global constant propagation appears to be pretty helpful. Likewise, performing dead code elimination after doing global constant propagation and local optimizations appear to help in optimizing the code better.
It is interesting to note that in many cases that have less number of instructions actually executed (ie. faster code), the number of SimpleSUIF instructions generated in the output tended to be higher, probably reflecting that the code has more optimizing instructions inserted into it.
In general, only compress, linpackd200 and swm256 showed a noticeable better performance in the optimized versions. Some of the other programs in fact had a degraded performance. Most of the optimizations in all these programs were through loop-invariant code motion.
A reason for this low optimization in some of the programs can be attributed to the fact that some of the optimization scope in these programs were lost due to lack of alias analysis and interprocedural analysis. As explained before, these caused some opportunity of optimizations to be lost, due to the conservative assumptions being made. Also, register allocation and other such phases take place in the optimizer back-end. Some of the optimizations that I implemented would result in increasing the live ranges that might cause register allocation to generate more code than it would it in the un-optimized version. This would easily happen in both loop-invariant code motion as well as in local common sub-expression elimination.