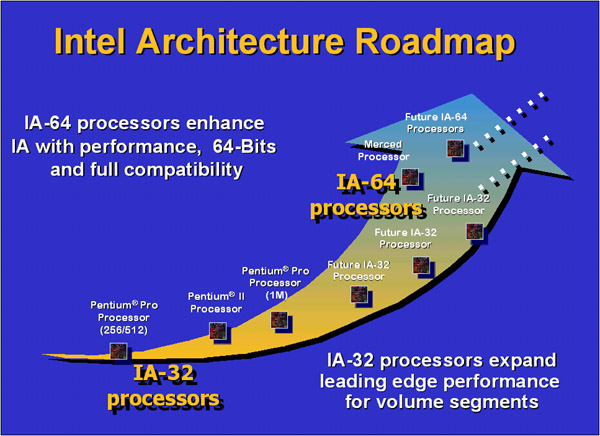
Major
Design Points
The IA-64 architecture will be a fully 64-bit architecture, though
it will retain backward compatibility with older 32-bit architectures (such
as the P6 architecture) and x86 architectures. The proposed improvements
will come from three major design elements: EPIC, branch predication and
control speculation. Branch predication and control speculation will be
illustrated later, but what does EPIC mean to me?
The major limitations on current RISC designs stem from memory latency and control hazards. In a typical RISC processor memory latency can cause miss penalties of up to 30 or 40 cycles. Caches and cache optimizations serve to reduce the impact of memory access, but they cannot eliminate the penalties associated with fetching from main memory. Control dependencies in any architecture also significantly degrade performance. In most processors, techniques including branch delay slots and branch prediction (both static and dynamic) help to decrease the number of control dependencies that cause hazards. Unfortunately, no combination of methods can fully eliminate control hazards and their associated penalties.
Intels
Solutions for the IA-64
Intel will introduce two new concepts for addressing these inherent limitations to parallel execution, branch predication and control speculation. Though they will not solve these problems outright, they will help to reduce related penalties. These are not difficult topics to comprehend, but they do require a look at some examples.
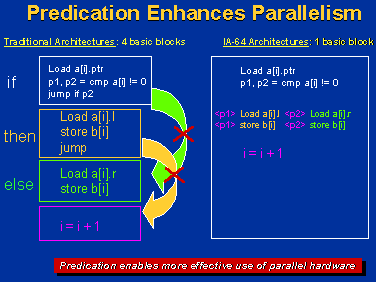
Branch Predication: In essence, the IA-64 processors will approach
a typical conditional block in a unique way. Rather than deciding which
path to execute, the processor will simultaneously execute both paths and
throw away results obtained from the path not needed. This is accomplished
using predicates, tags assigned to each path which evaluate to true or
false depending on the outcome of the branch. Instructions with a false
predicate will be killed in favor of those with a true predicate.
Control Speculation: This attempts to "hide" memory latency by loading operands before they are needed. In simple basic block this is quite straightforward and not a new optimization. When branches are involved however, the situation becomes more complicated. When the compiler encounters a branch, the necessary load is "hoisted" or moved before the branch condition statement. This can lead to undesired effects, especially exceptions if the address isn't valid. To prevent undesired behavior, the suspect load command is replaced with an instruction new to the architecture, ld.s. This command will carry out the memory fetch and detect any exceptions raised by this procedure. Rather than call the operating system if an exception is detected, it will write a flag to the target register and allow execution to continue. Following the branch statement, another command, check.s examines the target register for the presence of an exception flag. If present, the check.s makes an unconditional jump to fix-up code, which explicitly loads the correct value from memory. If no exception was detected, the check.s allows execution to continue as normal. This effectively hides the latency inherent in a memory fetch when no exception is thrown. When ld.s causes an exception, the processor must branch to the fix-up code and thus incurs a penalty analogous to that of a cache miss.

Using these two approaches, Intel engineers hope to effectively eliminate control hazards and memory stalls from code optimized for the IA-64.
The key to using the IA-64 architecture to its full potential lies in running code optimized for the processor. This means a good deal of emphasis will be placed on improving compiler technology and matching it to the specifications of IA-64. In the past, Intel has not accentuated the importance of running optimized code on its new processors. When the Pentium Pro debuted, many were disappointed at its inferiority at running common applications such as MS-Windows 9x. This arose because the P6 architecture was designed for fast execution of 32-bit code. Thus, it did not perform as well on older 16-bit code.
The same situation will arise in the Merced, where 64-bit code will probably outperform 32 and 16-bit legacy code from the x86 line. Thus, the compiler will play a pivotal role in this new architecture, and the compiler technology has been significantly enhanced. The IA-64 compiler uses inter procedural compilation that allows the compiler to parallelize code over larger regions than traditional compilers. The use of this new compiler explicitly parallelizes the code and results in improved processor utilization.
Comparisons with Other Processors
The IA-64 will have several basic similarities with other RISC processors discussed in Hennessy and Patterson. ALU instructions will be organized the same as in other RISC systems, with a (0,3) format. Addressing modes will be simple as well, allowing for only those analogous to DLX. The hardware will consist of many functional units and higher bandwidth than in previous processors. At this time, no announcement has been made regarding the memory hierarchy. There will be no dynamic scheduling employed in IA-64 because all parallelism will be generated by the compiler. This simplification will reduce the die size and create more room for the additional functional units.
It is difficult to classify IA-64 as either a VLIW or superscalar machine at this point, as it appears that this architecture will borrow concepts from both schools. It will execute native code in 128-bit instruction bundles while running x86 code in a manner similar to a superscalar design.

1. Show how a compiler would break up the following code in a
traditional architecture and for IA-64:
2. Show how a compiler would break up the following code in a traditional architecture and for IA-64:i = j++;
if ( i > inputval )
i = sqrt(i);
else
i = i++;
j = inputval + i;
Check your answers with ours.cin>>datavalue;
if ( datavalue > defaultvalue )
b[i] = a[datavalue + i];
a[i]--;
The next generation of Intel processors will signify the departure from the classic CISC-based x86 architecture we have all become familiar with (for better or worse). The IA-64 architecture will employ many more RISC design techniques than in many previous Intel processors. It will be a VLIW and superscaler hybrid, which focuses on fast execution of native code while retaining compatibility for legacy code. The two major design methods introduced will be branch predication and control speculation. Branch predication attempts to handle branches by executing both outcomes and throwing away unneeded results. Control speculation capitalizes on the hoisting of instructions to allow memory references to be executed before their results are needed. This effectively hides the inherent memory latency that significantly degrades performance. This new architecture will rely heavily on compatible compilers capable of producing the level of ILP needed to achieve fast execution. Only time will tell whether the compiler link will serve to be IA-64s major drawback.
Copyright 1998.
Pentium, Pentium Pro, Merced Copyrighted by Intel, Inc.
MS-Windows 9x Copyrighted by Microsoft, Corp.
Much props for Dr. Mount for his green squiggly graphic.
Created by Ken Bishop and Matt
House.