| Keith Slutskin
Kasima Tharpipitchai |
This page is devoted to helping other students understand Single Instruction Multiple Data processors, using AltiVec and MMX as examples. This page aims to explore their development, their differences, and the impact that they've had on technology and the current industry. We also provide an area for students to test what they have learned. We hope that the reader will take away a better understanding of SIMD from this document. These comparisons between AltiVec and MMX can show what kinds of design choices must be made to move from theory to real world implementation. This might provide some insight into multiprocessing theory and technology.
What Is SIMD
What Is MMX
What Is MMX2
What Is AltiVec
Design Differences
Impact
Questions
Answers to Questions
Terminology
Single Instruction, Multiple Data (SIMD) processors are also known as short vector processors. They enable a single instruction to process multiple pieces of data simultaneously. They work by allowing multiple pieces of data to be packed into one data word and enabling the instruction to act on each piece of data. This is useful in processing cases where the same operation has to performed on large amounts of data. For example, take image processing. A common operation found in programs such as Photoshop would be to reduce the amount of red in an image by half. Assuming a 32-bit traditional processor that is Single Instruction, Single Data (SISD) and a 24 bit image, the information for one pixel would be put into one 32-bit word for processing. Each pixel would have to be processed individually. In a 128-bit SIMD processor, four 32-bit pixels could be packed into one 128-bit word and all four pixels could be processed simultaneously. Theoretically, this translates to a four fold improvement in processing time.
There are some things to note about SIMD processing. Depending on the implementation, there is some overhead in loading data into the vectors. Programmers must also program specifically for SIMD processing. There are additional instructions that take advantage of SIMD processing.
The applications of SIMD include image processing, 3D rendering, video and sound applications, speech recognition, networking, and DSP functions. Since there are very specific conditions where SIMD processing can be used, it does not have such a significant affect in overall performance in all applications. But with the current mixture of popular applications, SIMD processing can greatly improve the performance of today's computers.
3D Software
SIMD processors have been carefully architected for 3D software. For
the operation of transforming 3D vertices, there is clear parallelism
(i.e., the ability to transform several vertices simultaneously) that the
SIMD-FP instructions can utilize to get better performance. This results
in the ability to transform more vertices per second. For the end-user,
the result is more dramatic realism from smoother (less blocky) and therefore
more realistic surfaces, more objects rendered in a given scene, shadow
effects rendered in real time, reflections, etc.
In addition to improving the rendering of more realistic 3D scenes, SIMD processors also improve realism and interactivity of the animation (movement) of objects and characters within their 3D scenes. SIMD processors will provide the additional computational throughput necessary to support the use of existing techniques such as collision detection and object physics on more complex objects and movements; and on emerging techniques such as forward-kinematics and inverse-kinematics, which improve the motion realism exhibited by both rigid and so embodies in an application. The end result will be a greater degree of realism and interactivity for the end-user -- for example, suspension that actually works on driving simulators, wings that actually flex on flight simulators, fingers that actually touch and grasp in human characters, etc.
A related, emerging developer trend is in the use of deformable "mesh skins". This is a technique of rendering objects that flex and bend as compared to the traditional method of rigid animation -- for example, this would be the difference between the realistic flexing of skin on a human jaw versus a block-jaw that appears marionette-like. These algorithms require additional " per-vertex" real-time computation that will benefit significantly from SIMD processors -- allowing greater use of these techniques on more 3D objects and characters of greater complexity and realism.
Imaging
Imaging software benefits greatly from SIMD processors, due to the
inherent parallelism in the code and data structures.
This added performance for imaging operations will be a key enabler in
maintaining end-user interactivity as the typical image size increases
(with the advent of higher resolution digital cameras) and the sophistication
of image manipulations increases. This will be true for both business and
consumer imaging applications, as well as high-end workstation digital
content creation applications.
Video
The imaging operations described above for video editing applications
are even more demanding on the performance of a system. With video editing,
the imaging operations described above must be done in real-time on the
individual frames of a video stream running at 24-30 frames per second.
SIMD's provide the ability to do more useful video manipulations in real-time
for consumer video creativity applications and professional video production
applications. Besides imaging operations, the other performance sensitive
operations of video applications are the core video compression/decompression
algorithms. These algorithms benefited greatly from SIMD processors. The
result manifests as higher resolution video images at faster frame rates
in areas such as video conferencing and in applications that use DVD/MPEG,
Indeo®, and other video technologies.
Speech Recognition
SIMD's will enhance the performance of speech recognition applications,
which continue to grow in use and popularity. This can be accomplished
by speeding up the front-end audio processing, and depending on the exact
code used by the speech software developers, this could increase the throughput
of the search algorithms involved in pattern matching. For continuous speech
recognition, the end result will be a reduced error rate and/or a shortened
response time. This will be an exciting, enhanced capability as speech
recognition is integrated in a growing number of business and consumer
applications.
Audio
While audio input and output samples are typically 16-bits at most,
much of the intermediate audio processing requires the higher dynamic range
that floating point representation provides. Since this processing involves
Fast Fourier Transforms, Finite Impulse Response, Infinite Impulse Response
(FFT, FIR, and IIR respectively), and other signal processing filters that
have large inherent parallelism, they will benefit
greatly from the SIMD-FP instructions that are part of Katmai New Instructions.
This will allow developers to more easily utilize software technologies
and features such as compressed audio (e.g., Dolby® Digital* ), HRTF-based
3D audio with more sound sources, more programmatically-modified sound
effects, more real-time sound effects (e.g,. natural reverbs, harmonizers,
equalization), and higher quality synthesized music/soundtracks (using
advanced methods like physical modeling). For consumer applications, this
translates into a more immersive, dynamic, and interactive sound.
MMX is a Pentium microprocessor from Intel that is designed to run faster when playing multimedia applications. According to Intel, a PC with an MMX microprocessor runs a multimedia application up to 60% faster than one with a microprocessor having the same clock speed but without MMX. In addition, an MMX microprocessor runs other applications about 10% faster. MMX technology evolved from earlier work in the i860ô architecture [3]. The i860 architecture was the industry's first general purpose processor to provide support for graphics rendering. The i860 processor provided instructions that operated on multiple adjacent data operands in parallel, for example, four adjacent pixels of an image.
After the introduction of the i860 processor, Intel explored extending the i860 architecture in order to deliver high performance for other media applications, for example, image processing, texture mapping, and audio and video decompression. Several of these algorithms naturally lent themselves to SIMD processing.
The MMX technology consists of three improvements over the non-MMX Pentium microprocessor:
1) 57 new microprocessor instructions
have been added that are designed to handle video, audio, and graphical
data more efficiently.
2) A new process, Single Instruction Multiple Data (SIMD), makes it
possible for one instruction to perform the same operation on multiple
data items.
3) The memory cache on the
microprocessor
has increased to 32 thousand bytes, meaning fewer accesses to memory that
is off the microprocessor.
Processor performance improvements are typically made by boosting clock frequencies and using microarchitecture techniques such as branch prediction, superscalar execution, and superpipelining. In addition to these traditional means, Intel added 57 powerful new instructions to its architecture to speed up certain compute-intensive loops in multimedia and communications applications. While the loops typically occupy 10 percent or less of the overall application code, they can account for up to 90 percent of the execution time.
MMX instructions work with floating point registers. It has 64 bits to operate with at once. So, it can run with 8 bytes at one time, or 4 words -- there are also a very few cases where MMX can work with 2 long words or 16 nibbles (4 bits) at the same time. So instead of a 32 bit processor acting like an 8 bit processor (when operating with 8 bit data), it works as 8 x 8 bit processors simultaneously. It also has a few instructions that perform specialized math, instead of taking extra time to build those functions out of simpler ones.
MMX shares its registers with the Floating Point Unit (FPU) and so all the registers must completely unload and reload whenever a programmer switches from MMX mode to floating point mode (the same applies to the reverse). This results in some real performance issues with MMX. However, if you don't want to mix MMX and FP, then things work perfect. In most cases, the programmer is not really in control of this, the operating system itself will often flip in an out of MMX and FP mode on its own schedule. Also, programmers do want to mix them in some cases.
MMX instructions will also scale with succeeding generations of Intel Architecture processors. Once developers integrate the new extensions into their applications, PCs based on multiple Intel processor generations will benefit. Programmers need only modify a small portion of their code to reap performance benefits. They simply include their own enhanced subroutines or call MMX technology enabled drivers and library routines through existing application programming interfaces (APIs).
In some ways MMX is faster, in others it can slow things down (mode switches). Intel is trying to improve MMX with the PentiumII's and later, because the first versions had this weakness. Even so, they can only do so much with their design without breaking programs already written for MMX.
MMX2, otherwise known as Katmai's New Instructions (KNI) enhances the Pentium II's MMX instruction set and speeds up floating-point operations. This technology, which was first announced in January of 1998, will be introduced in a family of Intel microprocessors in 1999. The first product to include Katmai New Instructions will be the Katmai processor, expected to be available in the first half of 1999.
MMX2 not only adds several new SIMD Integer instructions to bolster the original MMX instruction set, it more importantly adds a set of SIMD Floating Point instructions which operate on a new set of eight 128 bit (16 byte) XMM registers. This wealth of registers offers an extremely large opportunity for parallelism where several Integer and Floating Point operations can be executed at once. By comparison, MMX technology consists of fifty-seven instructions, and provides SIMD instructions for integer data types.
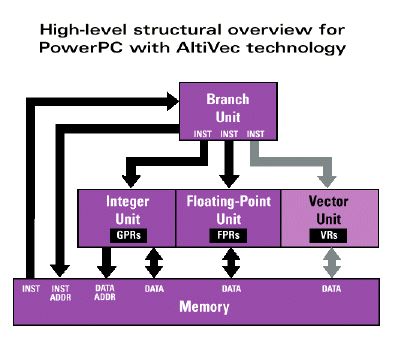
AltiVec is Motorola's implementation of an SIMD processor implementation in a mainstream processor. The first implementation of AltiVec will be in the PowerPC G4 chip due out next year. The AltiVec is implemented in a separate unit allowing concurrent operation with the existing integer and floating point units in the PowerPC architecture.
The Vector Execution unit 32 128-bit wide registers allowing it to process 128 bits at a time. 4, 8, or 16 pieces of data can be packed into each 128-bit word. This allows for up to 16 pieces of data to be processed simultaneously. Since the PowerPC architecture is a (0, 4) instruction set architecture, the 32 registers are both source and destinations registers. AltiVec offers support for:
Motorola added 162 new instructions to the PowerPC architecture to take advantage of the new features. The instructions are separated into four categories:16 way parallelism for 8-bit signed and unsigned integers and characters 8 way parallelism for 16-bit signed and unsigned integers 4 way parallelism for 32-bit signed and unsigned integers and IEE floating point numbers

Number of Registers
MMX: 8 64-bit registers (shared with Floating Point Unit)
MMX2: 8 128-bit registers
AltiVec: 32 128-bit registers
There are absolutely no disadvantages to having more registers. More is always better in this case. Since there is some overhead in using SIMD processing in the loading and unloading of the vectors, having to do it more often in various algorithm is a performance hit. Also, loads and stores may increase the chances of cache stalls. Many algorithms require more than 8 registers and implementation of those algorithms on MMX will require many loads and stores.
The MMX2 instructions are formatted the same as x86 instructions with 2 source registers and 1 destination register. But, the destination must be one of the source vectors, meaning one of the source operands is overwritten. If that source is needed again, it either has to be reloaded or copied before use. The limited number of registers and the limited instruction format of MMX2 come together to cause even more difficulty. AltiVec's instruction format allows 2 source registers, 1 filter/modifier register, and 1 destination register. All 4 registers can be distinct. This is a more versatile instruction format.
With more registers and a better instruction format, AltiVec is more versatile and can facilitate more complex algorithms quicker than MMX2.
Instruction Set Implementation
The efficiency of the instruction set also plays a role in the performance
of an SIMD implementation. Motorola has designed AltiVec with signal
processing in mind, which is a major application of SIMD processing.
In doing so, Motorola has provided clean and efficient implementations
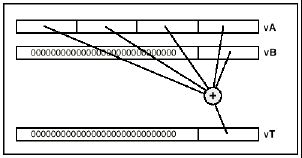
of it's instructions. For instance, MMX2 cannot multiply or add 4
data items in a register at once, it can only do 2 vectors at a time.
AltiVec, however, has instructions that are more orthogonal. There
are less "special conditions" that must be considered.
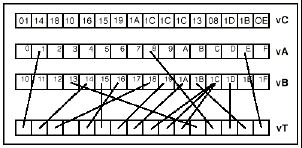
The AltiVec permute operation is also a powerful instruction that can be used in filtering or table lookups and in more common computing tasks. Many agree that the permute operation is a significant contribution to the PowerPC architecture. MMX2 does offer instructions to rearrange data but they are not as versatile as permute.
Other Irregularities or Trade-offs
MMX was originally designed as an addition to the x86 architecture.
To make MMX compatible with existing x86 processors without MMX, Intel
could not add any additional registers. Instead, the floating point
registers are shared with MMX. Unfortunately, there has to be a mode
change to use MMX and the Floating Point Unit. This mode change involves
saving the current states of the modes which is a large performance hit.
This mode change limitation basically made MMX incompatible with floating
point numbers.
Since MMX2 is an addition to MMX, the new instructions do not replace the old, more limited instructions of MMX. The new instructions allow the use of the addition 8 registers but they are now another "special condition" that programmers must be aware of. For instance, MMX originally dealt with integer operations in a 64-bit register. Although MMX2 has 128-bit registers, it still handles integer operations 64-bits at a time. The clean design of AltiVec allows for orthogonal instructions and very few conditions that must be considered by a programmer.
MMX was the first implementation of SIMD processing in a mainstream processor. Intel backed MMX with an aggressive marketing campaign that brought the term MMX into the home. Initially, applications optimized for MMX were highly specialized niche programs. Most of what Intel demonstrated at the launch of MMX were games and other entertainment software. Eventually, mainstreams programs such as Photoshop became optimized for MMX.
Unfortunately, Intel's limited implementation of SIMD in MMX drew much criticism from the computing community before the first Pentium with MMX was even sold. 3D rendering and video decoding, two of SIMD's strongest applications, fell short on MMX enabled Pentiums. According to Intel, "3D rendering does not benefit dramatically from MMX." Also, with the difficult MMX programming API, Intel was concerned that developer would not write code for MMX properly. Nonetheless, with Intel's market power and resources, MMX is widely supported.
With the launch of MMX, Intel was already working on fixing the limitations of MMX with MMX2. Many agree that MMX2 is what MMX should have been in the first place. Then impact of MMX2 will probably be what Intel had intended for MMX. All of the applications that MMX was originally intended for will probably actually function well on MMX2.
AltiVec is Motorola's first implementation of SIMD in it's mainstream
processor, the PowerPC. Already, many in the development community
agree that AltiVec is a clean implementation that is more powerful than
MMX2. Motorola is not only targeting desktop computers but also embedded
systems where the chips could be used in devices such as network routers.
Unfortunately, the only consumer platform that uses PowerPC chips is the
Macintosh computers from Apple Computers. This limits the consumer
audience that may garner advantages from AltiVec. But Apple computer
did play a role in developing AltiVec and plans on using it extensively
as soon as the chips become available. Also, Adobe already has made
plans on developing an AltiVec enabled version of Photoshop for the MacOS.
Due to the fact that the PowerPC has a much smaller market base than the
Intel processors, the impact of AltiVec may not have a large consumer impact.
I. True and False
1. SIMD's enable a single instruction to process multiple pieces of
data simultaneously.
2. One improvement that MMX has over non-MMX pentium processors is that
157 new microprocessor instructions have been added that are designed to
handle video, audio, and graphical data more efficiently.
3. The PowerPC architecture is a (0, 2) instruction set architecture.
4. Inter-Element Arithmetic Operations perform summations of elements
in a source register with a separate accumulation register.
5. AltiVec is Motorola's first implementation of SIMD in it's mainstream
processor, the PowerPC.
II. Matching
| 1. SIMD
2. MMX 3. Katmai's New Instruction 4. AltiVec 5. Operating System |
a. Intel's SIMD processor that will be released in early 1999
b. Flips in and out of MMX and FP mode c. Another name for short vector processor d. 162 new instructions to the PowerPC architecture to work with it. e. 8 bytes at one time. |
III. Short Answer
1. What are five areas in computing that SIMD's improve performance?
2. List three different kinds of parallelism that Motorola will support with AltiVec.
3. Name a microarchitecture techniques that helps improve processor performance.
A cache (pronounced CASH) is a place to store something more or less temporarily. Web pages you request are stored in your browser's cache directory on your hard disk. That way, when you return to a page you've recently looked at, the browser can get it from the cache rather than the original server, saving you time and the network the burden of some additional traffic. You can usually vary the size of your cache, depending on your particular browser.
A floating point unit (FPU), also known as a numeric coprocessor, is a microprocessor or special circuitry in a more general microprocessor that manipulates numbers more quickly than the basic microprocessor your computer uses. It does so by having a special set of instructions that focus entirely on large mathematical operations. A floating point unit is often built into today's personal computers, but it is needed only for special applications such as graphic image processing or display. Personal computers that don't have floating point units can sometimes handle software that requires them by installing a floating point emulator.
Memory is the electronic holding place for instructions and data that your computer's microprocessor can reach quickly. When your computer is in normal operation, its memory usually contains the main parts of the operating system and some or all of the application programs and related data that are being used. Memory is often used as a shorter synonym for random access memory (RAM). This kind of memory is located on one or more microchips that are physically close to the microprocessor in your computer. Most desktop and notebook computers sold today include at least 16 megabytes of RAM, and are upgradable to include more. The more RAM you have, the less frequently the computer has to access instructions and data from the more slowly accessed hard disk form of storage.
A microprocessor is a computer processor on a microchip. It's sometimes called a logic chip. It is the hardware that goes into motion when you turn your computer on. A microprocessor is designed to perform arithmetic and logic operations that make use of small number-holding areas called registers. Typical microprocessor operations include adding, subtracting, comparing two numbers, and fetching numbers from one area to another. These operations are the result of a set of instructions that are part of the microprocessor design. When the computer is turned on, the microprocessor is designed to get the first instruction from the Basic Input/Output System (BIOS) that comes with the computer as part of its memory. After that, either the BIOS, the operating system that BIOS loads in, or an application program is in charge and the microprocessor performs the instructions it is given.
An operating system (sometimes abbreviated as "OS") is the program that, after being initially loaded into the computer by a bootstrap program, manages all the other programs in a computer. The other programs are called applications. The applications make use of the operating system by making requests for services through a defined application program interface (API). In addition, users can interact directly with the operating system through an interface such as a command language.
Parallel processing is the processing
of program instructions by dividing them among multiple processors with
the objective of running a program in less time. In the earliest computers,
only one program ran at a time. A computation-intensive program that took
one hour to run and a tape copying program that took one hour to run would
take a total of two hours to run. An early form of parallel processing
allowed the interleaved execution of both programs together. The computer
would start an I/O operation, and while it was waiting for the operation
to complete, it would execute the processor-intensive program. The total
execution time for the two jobs would be a little over one hour.
A register is a temporary-memory device
used to receive, hold, and transfer data (usually a computer word) to be
operated upon by a processing unit. Computers typically contain a variety
of registers. General purpose registers (GPR) may perform many functions,
such as holding constants or accumulating arithmetic results. Special purpose
registers perform special functions, such as holding the instruction being
executed, the address
of a storage location, or data being retrieved from or sent to storage.
Sources:
Katmai outgunned
by Motorola's Altivec - The Register
Motorola
AltiVec Technology: Home Page
Wolfe's
Den: Cracking Katmai - EE Times
MMX
software trickles out - c|net
MMX:
Fact vs. fiction - c|net
MMX
software trickles out - c|net
CNET News.com
- Intel Katmai chips due in 1999
MMX
Application Notes
MMX
Technical Manuals
David Bistry, "Complete Guide to MMX Technology." July 1997. McGraw
Hill.