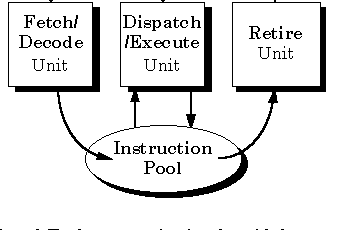
FIG 1. The P6 is implemented as three independent engines that communicate
using an instruction pool.
If you want to change the background color
click one of the buttons
This page will make more sense if you read Chapter 4 of HENNESSY & PATTERSON before hand.
PIPELINE VARIETY
(There are a vast amount of resources regarding Pentium Pro Processors and pipelining, we have a special link to some of these pages. LINK.)
THE AIM
The aim of
Pentium Pro Processor was to utilize the CPU to full extent. While CPU
speeds have increased 10-fold over the past 10 years, the speed of main
memory devices has only increased by 60 percent (1). This increasing
memory latency, relative to the CPU core speed, is a fundamental problem
that the Pentium Pro processor set out to solve. There are various
ways to speed up the CPU, and some of the methods are discussed on Chapter
4-5 of H&H. One approach would be to place the burden of this problem
onto the chipset
but a high-performance CPU that
needs very high speed, specialized, support components is not a good solution
for a volume production system (1). One way to achieve this goal
would be to increase the size of
the L2 cache to reduce the miss
ratio. While effective, this is a very expensive solution in
terms of cost and
space. So how did the Pentium
Pro Processor solve this problem ?
The Pentium Solution.
As discussed in the Introduction,
the Pentium Pro Processor designers achieved this goal by implementing
Dynamic Execution into the Pentium Pro.
FIG 1. The P6 is implemented as three independent engines that communicate
using an instruction pool.
The old Pentium processor's superscalar
microarchitecture (EXPECT THIS ON FINAL), with its ability to
to execute two instructions
per clock, would be difficult to exceed without a new approach. The new
approach used by the Pentium Pro processor removes the constraint of linear
instruction sequencing (kind of like DLX) between the traditional "fetch"
and "execute" phases, and opens up a wide instruction window using an instruction
pool, hence Dynamic Execution. Look at page 354 of H&P (Historical
Perspective and References) to see major advances in compiler technology,
advanced pipelining, multiple-issue processors.
The following steps describe the Pentium Pro processor pipeline.
FETCH/DECODE UNIT: An
IN-ORDER
unit that takes as input the user program instruction stream
from the instruction pool (look
figure above) and decodes them into a series of micro-operations (uops)
that represent the dataflow. This is the stage where speculation is used
to determine if whether to execute the next instruction or not.
DISPATCH/EXECUTE UNIT: An OUT-OF-ORDER unit that accepts the dataflow stream, schedules execution of the uops subject to data dependencies and resource availability and temporarily stores the results of these speculative executions.
THE RETIRE UNIT: An in-order unit that know how and when to store ("retire") the temporary, speculative results to permanent architectural state.
THE BUS INTERFACE UNIT: A partially ordered unit responsible for connecting the three internal units to the real world. The bus interface unit communicates directly with the L2 cache.
SOME USEFULL
LINKS.
Dynamic
Execution.
EXTENSIVE CPU STUFF.
CPU
BENCHMARK.
CPU FAQ.
Pentium(R)
Pro Processor Technical Glossary
Pentium
Pro FAQ.
More
Pentium Pro Stuff.
SuperPipelining