SH-4 RISC Processor
SH-4 RISC Processor is a family of new RISC chips which are been developed by HITACHI simiconductor company.
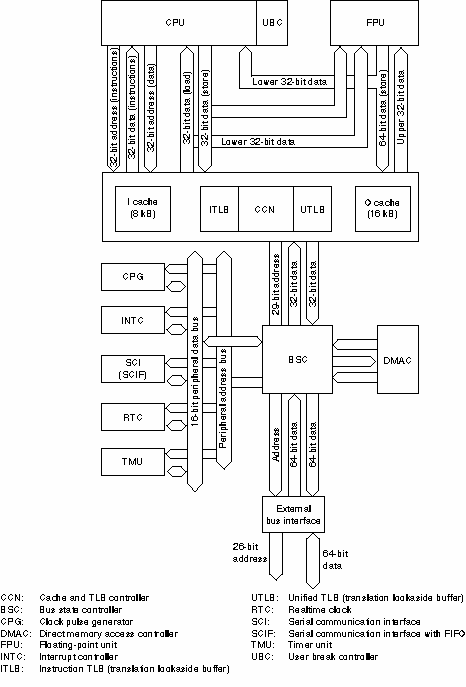
The diagram below is the block diagram of one of the SH-4 RISC processor family member, SH7750.
Specification of the SH7750:
The SH7750 is a 2-ILP (instruction-level-parallelism) superscalar pipelining microprocessor. Instruction execution is pipelined, and two instructions can be executed in parallel. The execution cycles depend on the implementation of a processor.
The SH7750 is a 32-bit RISC (reduced instruction set computer) microprocessor, featuring object code upward-compatibility with SH-1, SH-2, SH-3, and SH-3E microcomputers (earlier versions). It includes an 8-kbyte instruction cache, a 16-kbyte operand cache with a choice of copy-back or write-through mode, and an MMU (memory management unit) with a 64-entry fully-associative unified TLB (translation lookaside buffer).
The SH7750 has an on-chip bus state controller (BSC) that allows direct connection to DRAM and synchronous DRAM without external circuitry. Its 16-bit fixed-length instruction set enables program code size to be reduced by almost 50% compared with 32-bit instructions.
Although there are many parts to the processor, pipelining sections are discussed in details due to the importance of understanding pipelining in RISC architecture. In addition this whole process takes place at CPU (well, at least around CPU), so rest of the diagram is for the information.
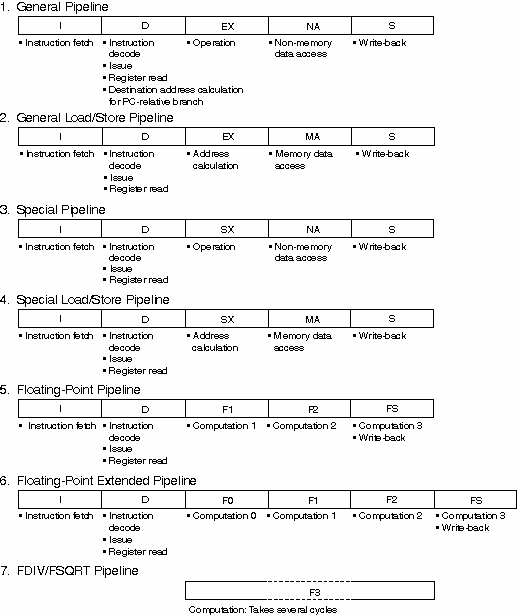
The basic pipeline structure has five stages: Instruction, Decoding, Execution, Memory or Data Access, and Write Back. In the RISC architecture these instructions are trying to be executed as many as possible without causing hazards and with minimum stalls.
Hazards happens when dealing with the pipeline architecture because two instructions or more are being executed at once. For example, when one data is depended upon the result of another data, it might result in a hazard if the said data was read before the result is done (this particular hazard is called read after write hazard). Simple solution here is by stalling the instruction such that the data is read only when the result is done (there are other ways but will not be discussed here).
Click here to see the diagram of the basic pipelines.
Note that most of the pipelines have about the same number of stages (5), and also the name of each stages are slightly different, it is basically a same. The name differences are due to what instructions are being used: for example, integer addtions and floating point additions are handled differently in the pipeline architecture.
{kind=link}