|
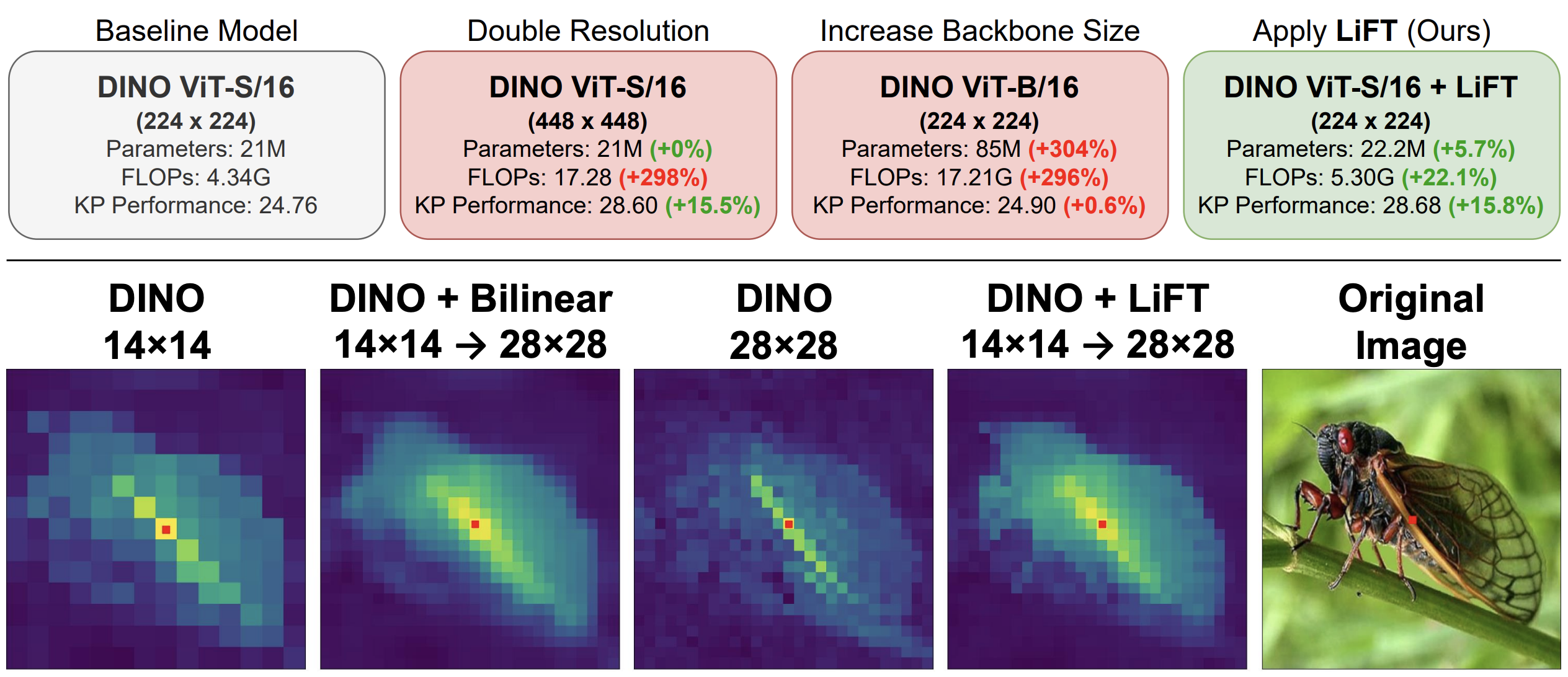
We present a simple self-supervised method to enhance the performance of ViT features for dense downstream tasks.
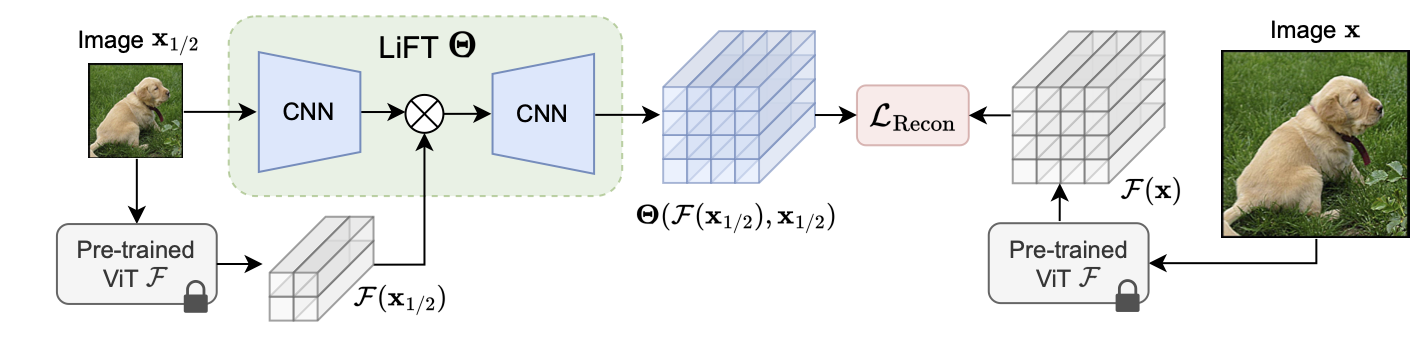
Our Lightweight Feature Transform (LiFT) is a straightforward and compact postprocessing network that can be applied
to enhance the features of any pre-trained ViT backbone. LiFT is fast and easy to train with a self-supervised
objective, and it boosts the density of ViT features for minimal extra inference cost. Furthermore, we
demonstrate that LiFT can be applied with approaches that use additional task-specific downstream modules, as we
integrate LiFT with ViTDet for COCO detection and segmentation. Despite the simplicity of LiFT, we find that it is
not simply learning a more complex version of bilinear interpolation. Instead, our LiFT training protocol leads to
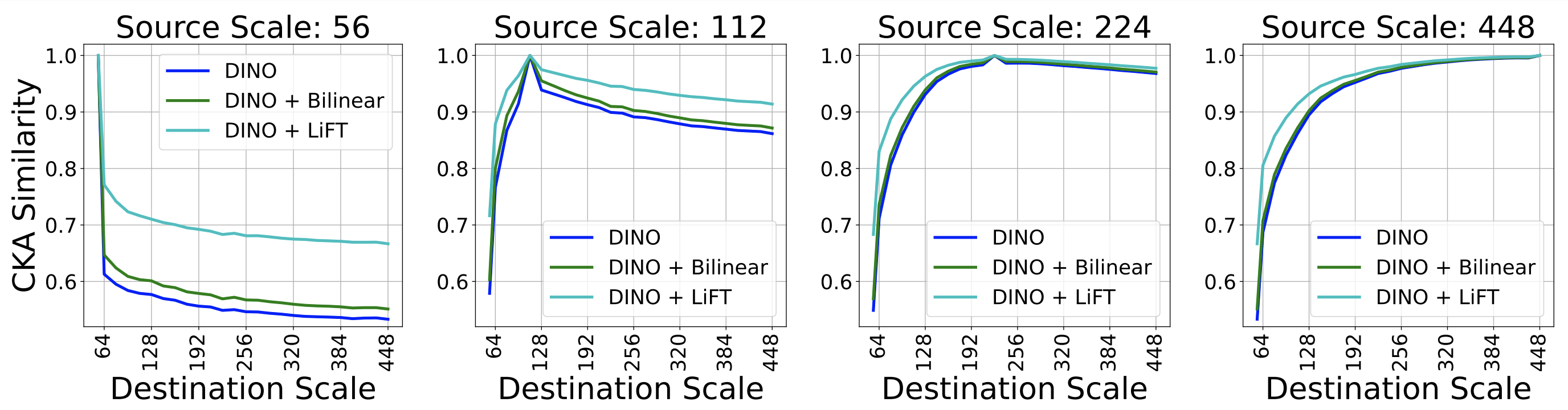
several desirable emergent properties that benefit ViT features in dense downstream tasks. This includes greater scale
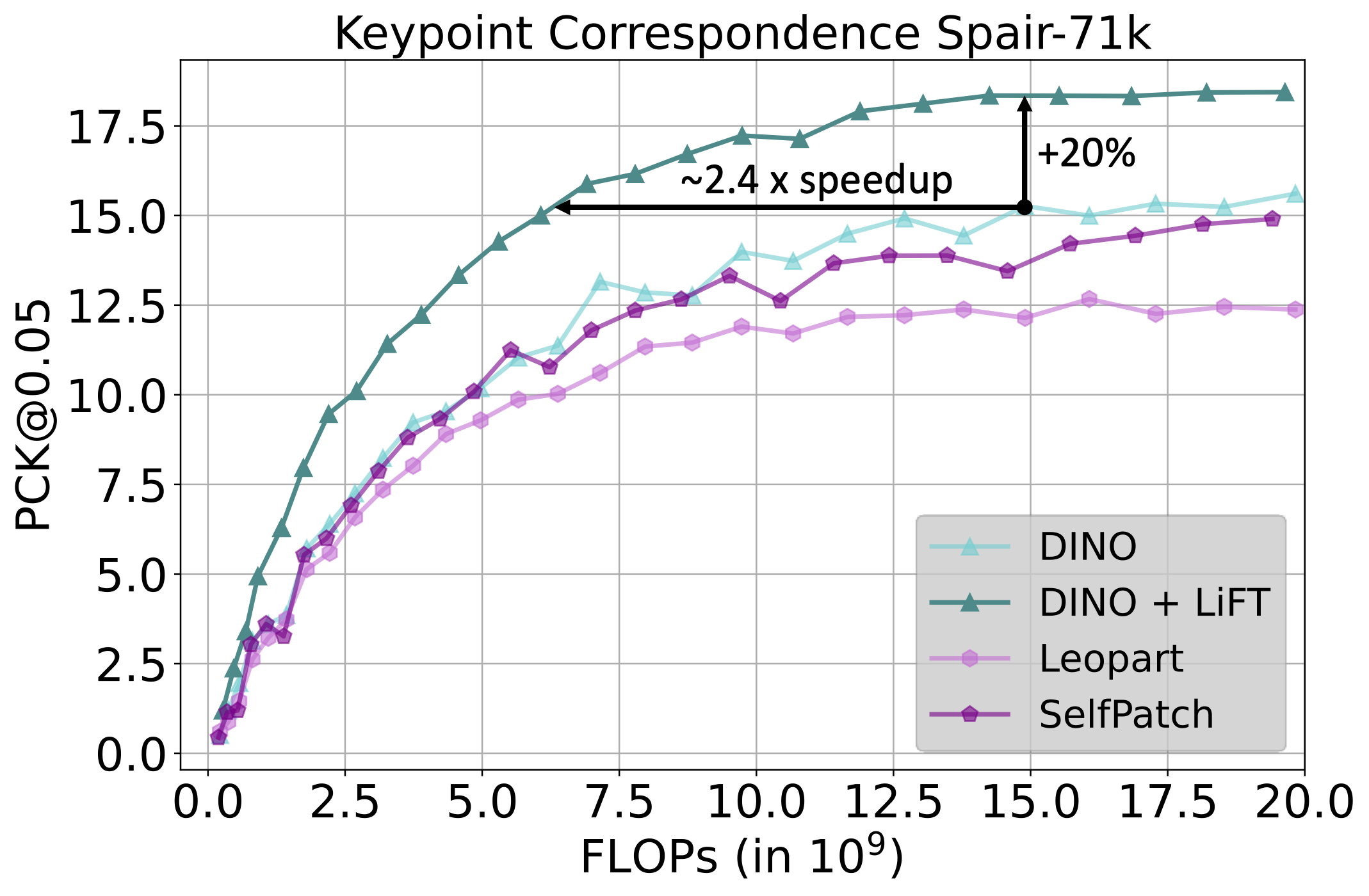
invariance for features, and better object boundary maps. By simply training LiFT for a few epochs, we show improved
performance on keypoint correspondence, detection, segmentation, and object discovery tasks. Overall, LiFT provides
an easy way to unlock the benefits of denser feature arrays for a fraction of the computational cost.
|