|
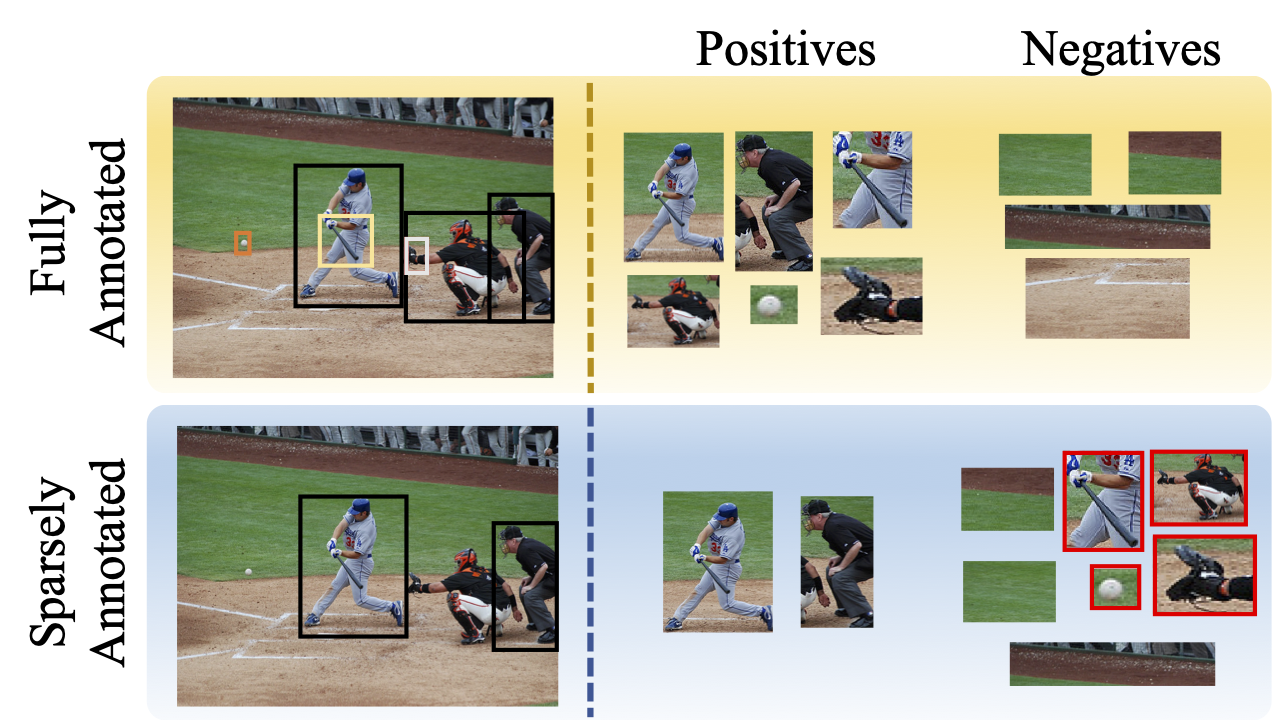
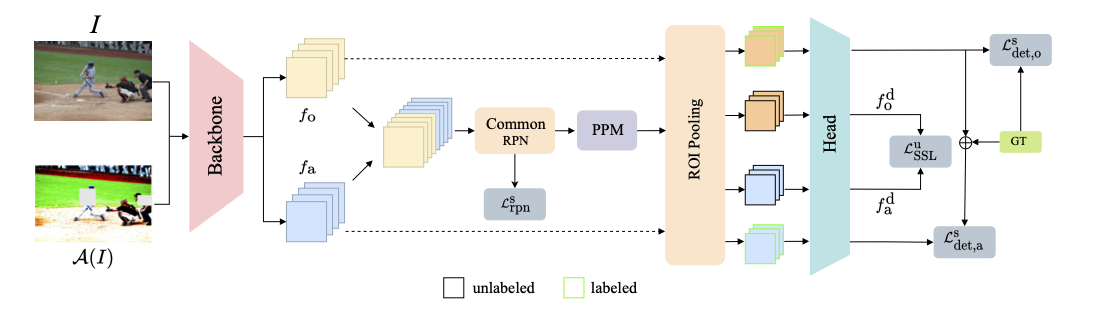
Illustration of SparseDet for sparsely annotated object detection.
SparseDet consists of a backbone network that extracts features from the
original and augmented views of an image. The common
RPN (C-RPN), concatenates the features, to generate a set
of region proposals. A region proposal can belong to one
of three groups, namely 1) labeled regions, 2) unlabeled foreground regions,
or 3) background regions. For a given set of ground-truth annotations, the
first group, i.e. labeled regions can be automatically identified. The problem then becomes to identify and separate
the second group i.e. the unlabeled regions, from the background regions. Given all the region proposals, a pseudo-
positive mining (PPM) step identifies the unlabeled regions
and segregates them from the background regions. The labeled and unlabeled regions are trained using supervised
and self-supervised losses respectively.
|