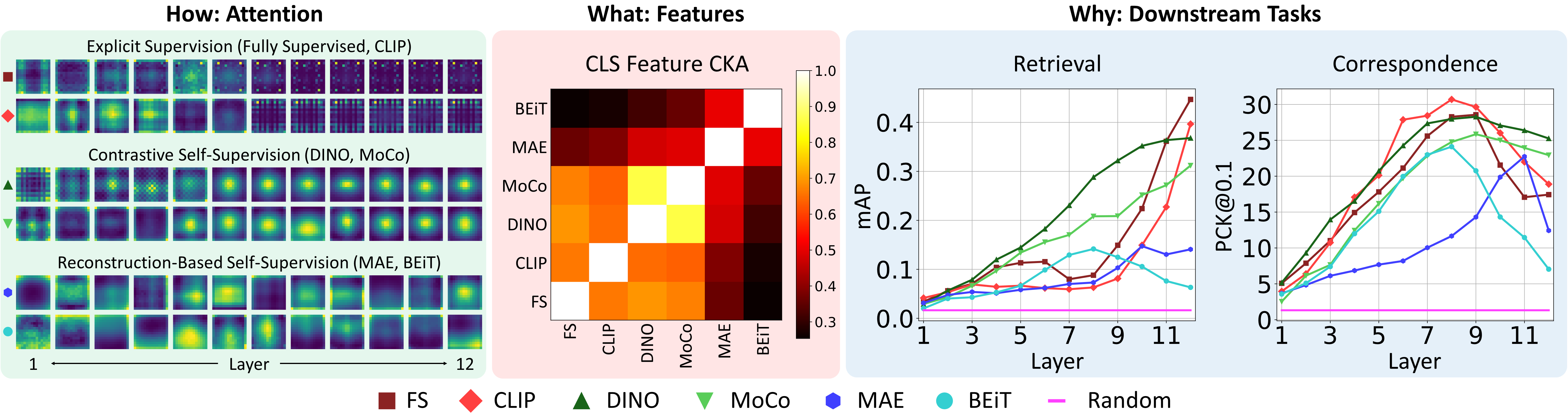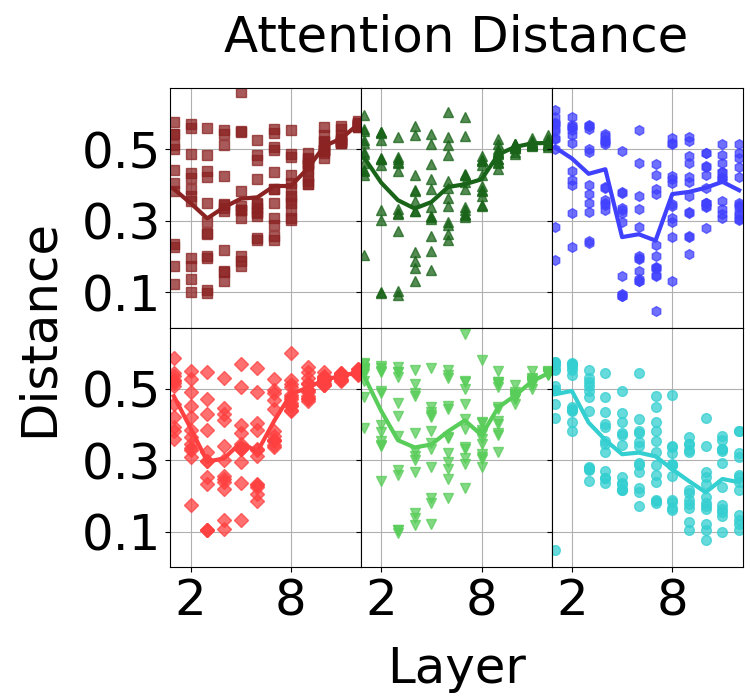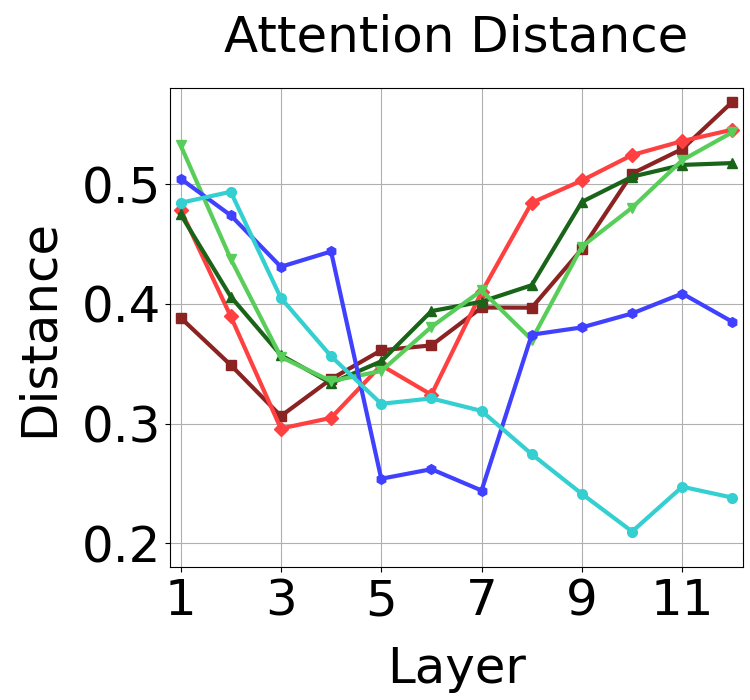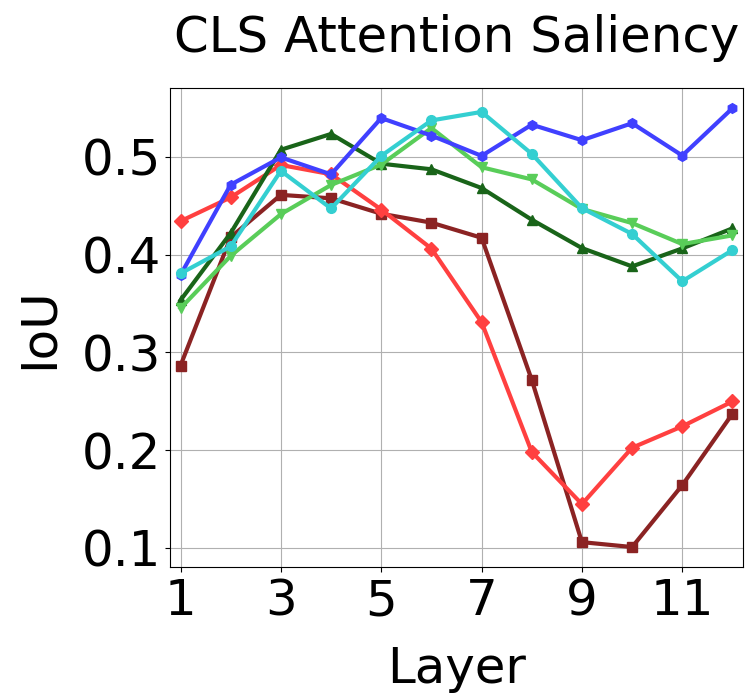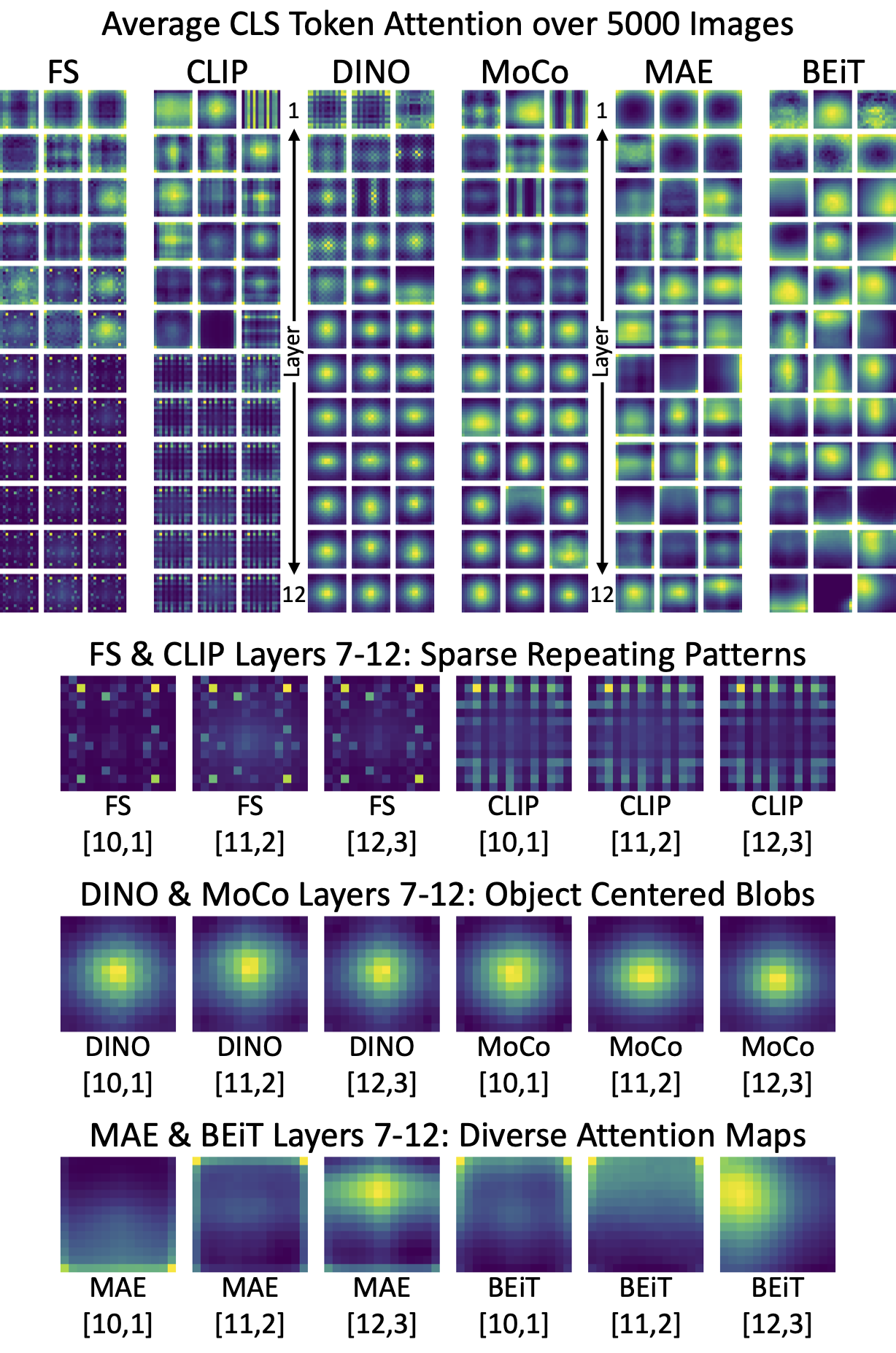
Clear differences in attention emerge in the mid-to-late layers under different supervision methods. These plots
show the attention maps of CLS tokens averaged over 5000 ImageNet images. Rows indicate layers and columns indicate heads.
For brevity, we show only three heads per layer. The bracketed numbers in the lower half denote the layer and head.
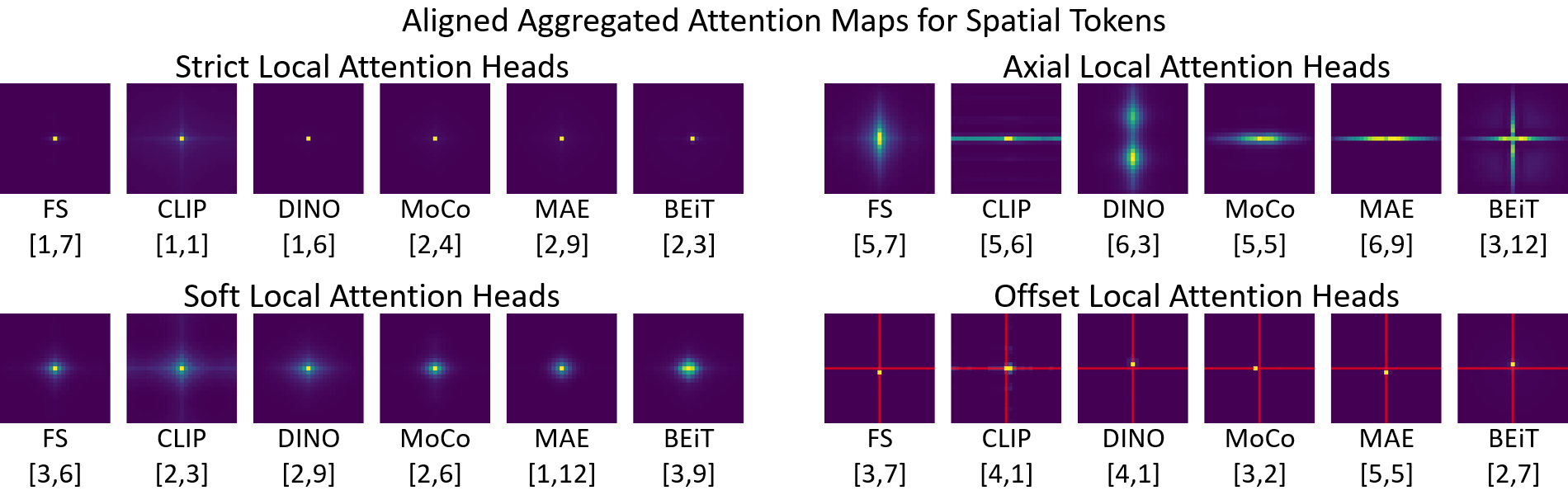
Multiple distinct forms of local attention exist. We visualize spatial token attention using Aligned Aggregated Attention Maps, and highlight different types of local attention heads,
including Strict, Soft, Axial, and Offset Local Attention Heads. In the bottom right, the mid-lines are shown in red for reference.
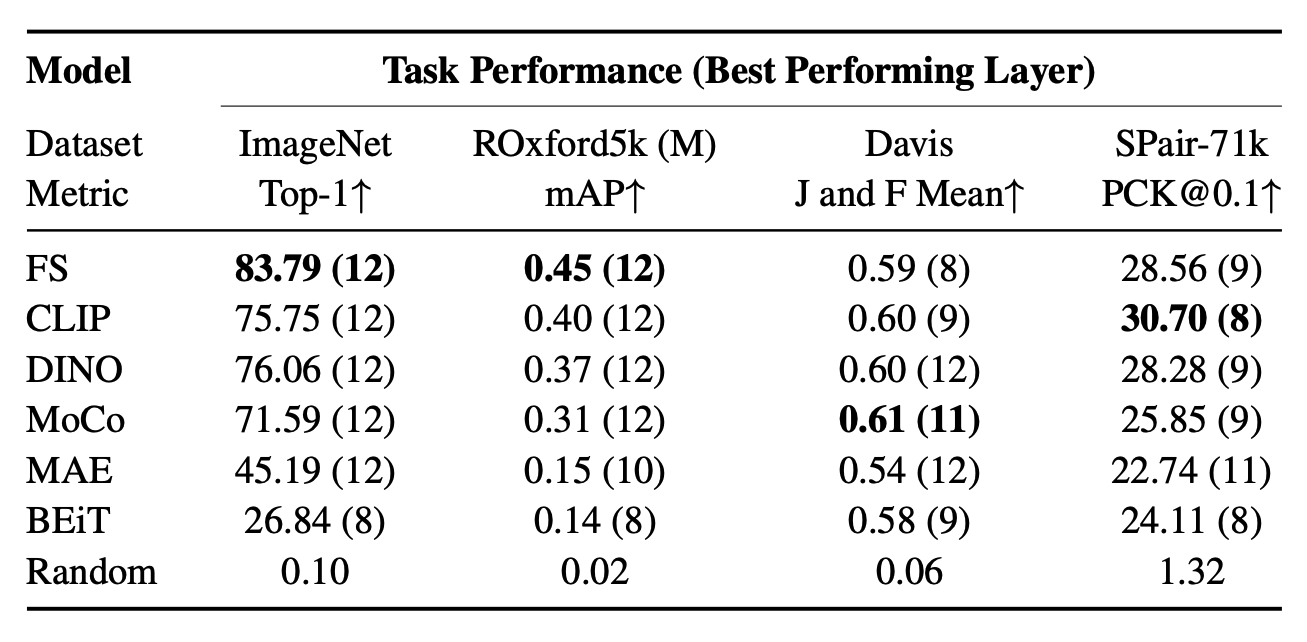
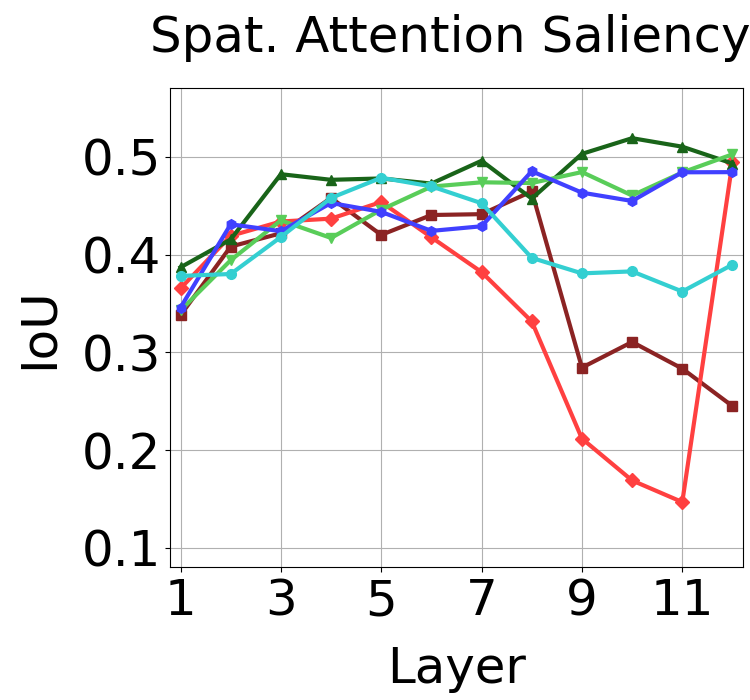
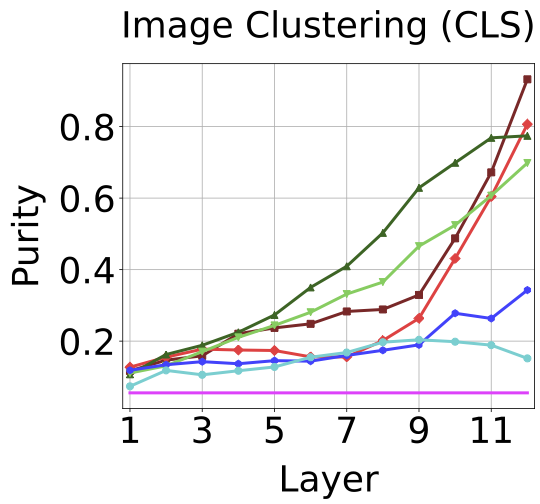
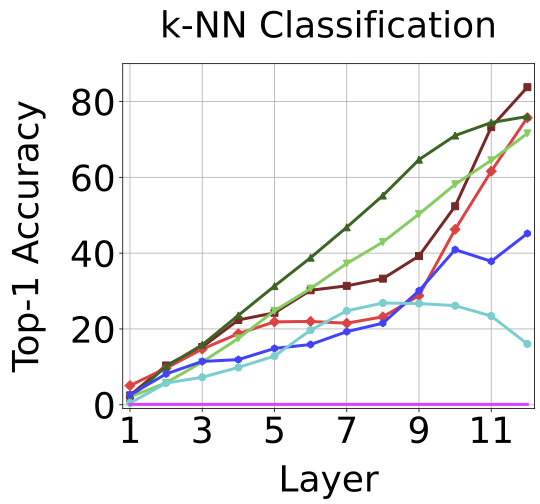
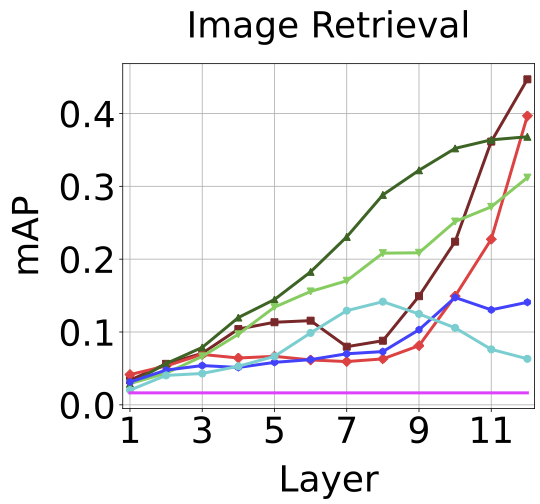
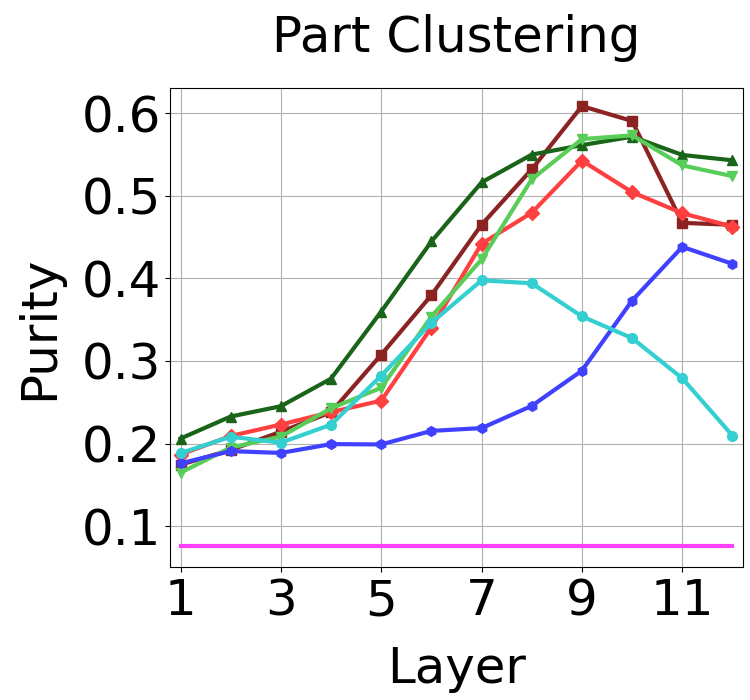
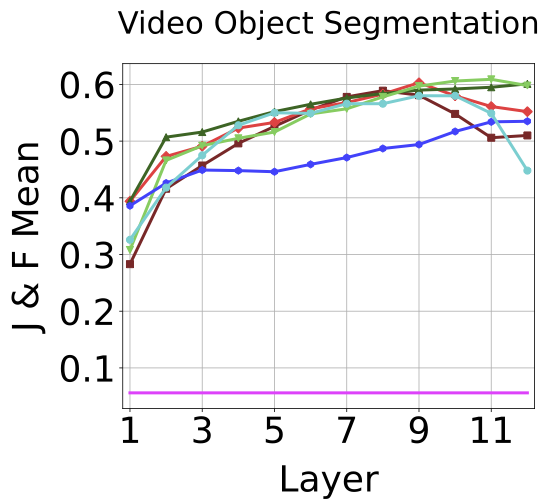
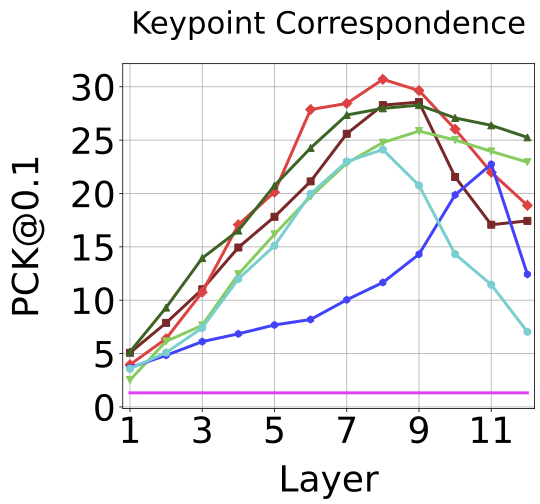
Best performance for each ViT on each downstream task with the corresponding best layer in parenthesis. As shown in the table, no one model performs best at all tasks. Also, which layer is best performing depends on the task and training method.