
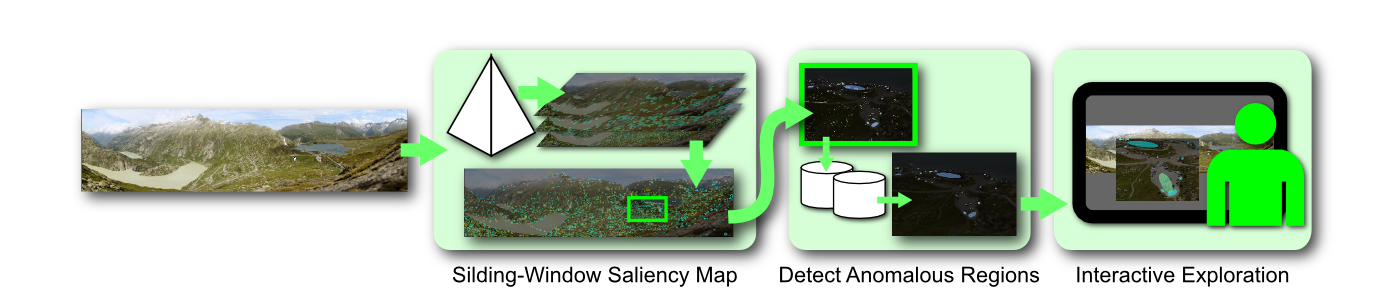
This work presents the first steps towards navigation of very large images, particularly landscape images, from an interactive visualization perspective. The grand challenge in navigation of very large images is identifying regions of potential interest. In this work we outline a three-step approach. The figure here shows an overview of our approach. In the first step we use multi-scale saliency to narrow down the potential areas of interest. In the second step we outline a method based on statistical signatures to further cull out regions of high conformity. In the final step we allow a user to interactively identify the exceptional regions of high interest that merit further attention. We show that our approach of progressive elicitation is fast and allows rapid identification of regions of interest.

We are seeing a significant growth in the interest and relevance of very large images. One of the reasons behind this trend is the development of systems that can automatically capture and stitch photographs to create images of unprecedented detail ranging from a few gigapixels to even a few terapixels. Recent advances in consumer-grade robotic image acquisition from companies such as Gigapan have further energized social network communities that are interested in building, sharing, and collectively exploring such large images.
The successive zooms give an indication of the level of detail in such images. When viewing such images, users typically pan at the coarse level and occasionally zoom in to see the fine details. Panning at the finest level of detail is too tedious and panning at the coarsest level of detail does not have enough information for the user to know where to zoom in. Just to convey the magnitude of the problem, let us consider some numbers. Imagine a user is visualizing a 4 Gigapixel image on a 2 Megapixel monitor. This would suggest that every monitor pixel is representing 2000 image pixels and the observable image on the monitor is a mere 0.05% of the total dataset. Further, if it takes a user just a couple of seconds to scan the monitor, it will take more than an hour to scan through the entire image.

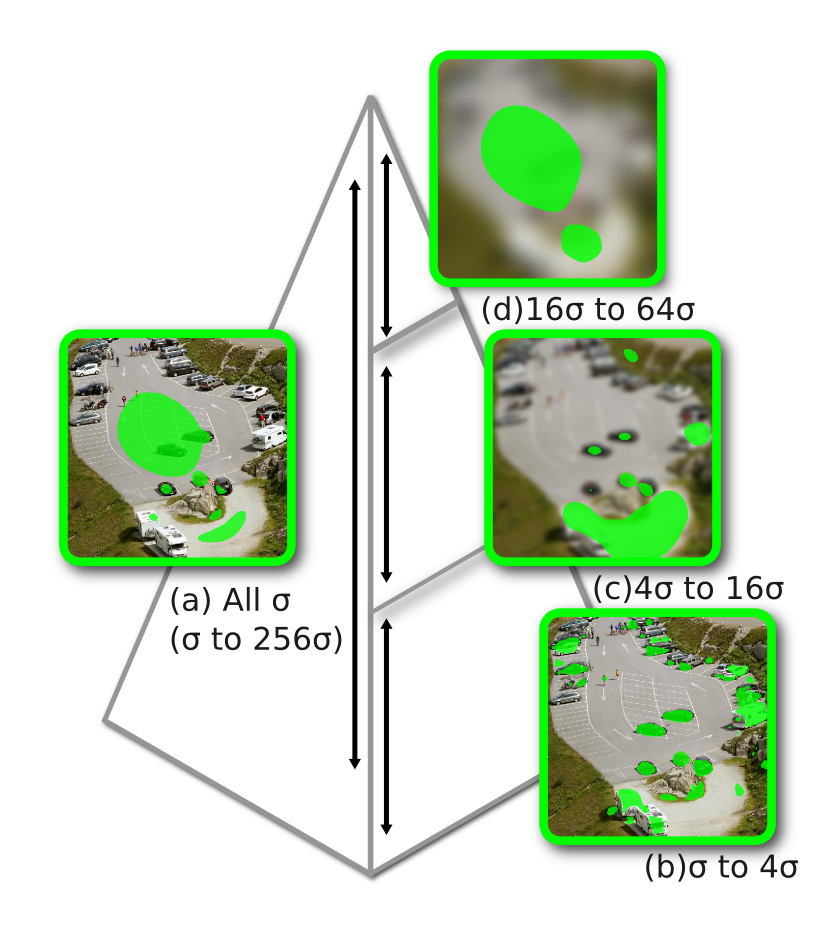
- We extend classical computational image saliency to very large images. Users often navigate across three or more orders of magnitude scale differences from the overview to the finest-scale > views while viewing a very large image. Classical algorithms for multi-scale image saliency break down at handling such a large span of visual scales. We discuss the issues involved and present sliding-window saliency to address this problem.
- It is important to identify the regions of interest in very large images that characterize areas of high information value to users. The question of how to effectively characterize visual information content is still far from settled. We present here a fairly general information discovery algorithm, that can serve as a framework for further research with different measures of information content.
- Interactive visual exploration of very large images requires a careful balancing of computational analysis and user preferences. Too much reliance on automatic intelligence-extraction algorithms is currently not feasible since it is often very difficult to codify semantics of what a user is looking for. At the same time a purely interactive visual exploration without any computational assistance proves to be tedious and overwhelming due to the sheer scope of the data that is being visualized. We present an interactive visual exploration and information discovery system.
- Data scalability is an important issue when dealing with very large images and we present advances in this area.
- We present and compare our results with those from a social community of gigapixel image enthusiasts.
We evaluate our approach on multi-gigapixel images. We report the regions identified by our system and compare them against web community tags. We also report timings of our experiments.
We show a sample of the detected regions using ellipses. We tag the locations with numbers and show the detected region in the corresponding thumbnails. Our system identifies a variety of regions at multiple scales. It locates humans, vehicles, buildings and even features of the landscape such as a glacier. This shows the generality of our approach.
Internet users tag and comment on these very large images on Gigapan's website. We compare the tags with our results. Our system is able to detect 78% - 90% of all non-semantic Gigapan community tags. Our parallel kD tree based k-nearest neighbor anomaly detection reduces thousands of salient regions to a few hundreds while it also enables the interactive refinement process. The interactive select-slide-delete refinement process (searching, and redrawing) takes only tens of milliseconds.


We use visualization and computation to assist the exploration of very high-resolution large-scale landscape images by detecting interesting details that match the Gigapan community user tags well. We address the visual scale challenge by introducing the sliding-window computational saliency model. Anomaly detection automatically discovers information while visualization allows the users to explore the image interactively. Our system implementation scales to large datasets by using out-of-core methods.
- Saliency-Assisted Navigation of Very Large Landscape Images
C.Y. Ip and A. Varshney, IEEE Transactions on Visualization and Computer Graphics (IEEE Visualization 2011), 2011
This work has been supported in part by the NSF grants: CCF 05-41120, CMMI 08-35572, CNS 09-59979 and the NVIDIA CUDA Center of Excellence. Any opinions, findings, conclusions, or recommendations expressed in this article are those of the authors and do not necessarily reflect the views of the research sponsors.

Web Accessibility
