
Xuejun Hao and Amitabh Varshney

We propose the idea of using variable-precision geometry transformations and lighting to accelerate 3D graphics rendering. Multiresolution approaches reduce the number of primitives to be rendered; our approach complements the multiresolution techniques as it reduces the precision of each graphics primitive. Our method relates the minimum number of bits of accuracy required in the input data to achieve a desired accuracy in the display output. We achieve speedup by taking advantage of (a) SIMD parallelism for arithmetic operations, now increasingly common on modern processors, and (b) spatial-temporal coherence in frame-to-frame transformations and lighting. We show the results of our method on datasets from several application domains including laser-scanned, procedural, and mechanical CAD datasets.

As the complexity of visualization datasets has increased beyond the interactive rendering capabilities of the graphics hardware, research in graphics acceleration has engendered several novel techniques that reconcile the conflicting goals of scene realism and interactivity. These techniques can be broadly classified into two lines of research. The first line of research includes techniques such as multiresolution rendering and visibility-based culling. Such techniques operate by reducing the number of graphics primitives to be rendered based on viewing and illumination parameters, such that there are minimal visually discernible differences between viewing higher complexity and lower complexity scenes. Orthogonal to these advances, we have been witnessing another line of research whose goal is to reduce the precision of each graphics primitive being rendered. We have merged these two lines of research for variable-precision, view-dependent rendering.
Most transformations and lighting for graphics primitives are currently carried out at full floating-point precision only to be later converted to fixed-point representation during the rasterization phase. An argument can be made that such high accuracy during geometry transformation and lighting stage sometimes exceeds even the display accuracy and thus causes several bits worth of unnecessary precision computation.

In this research we lay down the mathematical groundwork for performing variable-precision geometry transformations and lighting for 3D graphics. In particular, we explore the relationship between the distance of a given sample from the viewpoint, its location in the view-frustum, to the required accuracy with which it needs to be transformed and lighted to yield a given screen-space error bound. The main contributions of this research are:
- We show how variable-precision transformations and lighting (at arbitrary precisions, not just 32 and 16 bits) can speed up general 3D transformations, parallel and perspective, and result in more efficient lighting.
- We present a careful error analysis to relate the number of bits of input precision required for a given display accuracy.
- We study how variable-precision operations can be used with spatial and temporal coherences.
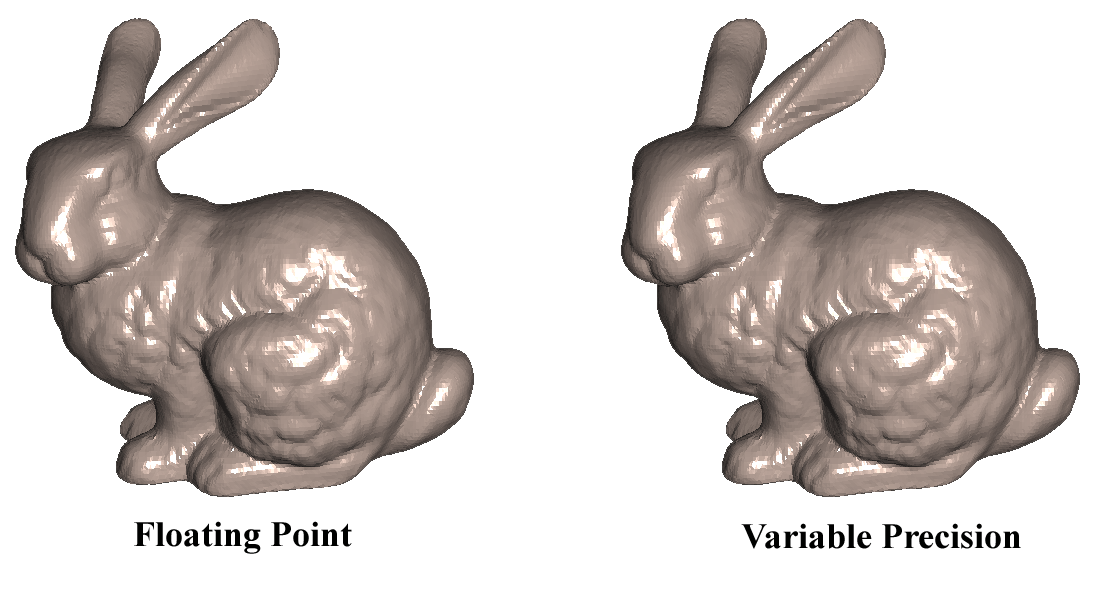
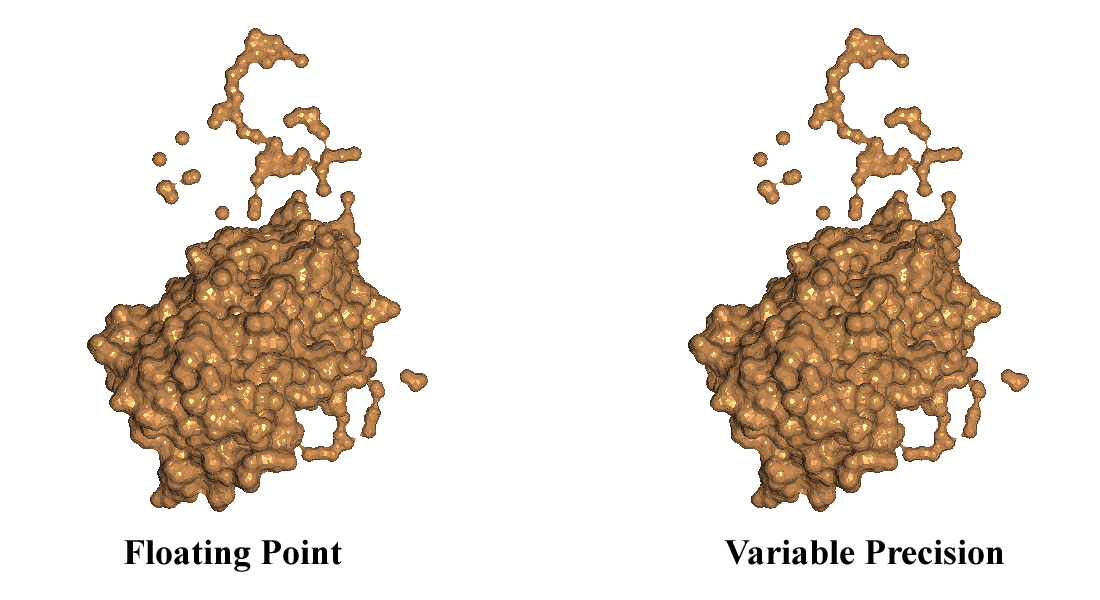
Our variable-precision technique provides bounds on the bits of accuracy per primitive that are required for high-fidelity rendering. We have tested our approach on polygonal datasets from several application domains including laser-scanned, mechanical CAD, and molecular CAD datasets. We have seen a factor of three or more speedup in all the datasets tested. One aspect of our algorithm is that it scales well. The speedup factor goes up with the increase of scene complexity (which means more data will be rendered in less precision) and the number of light sources.
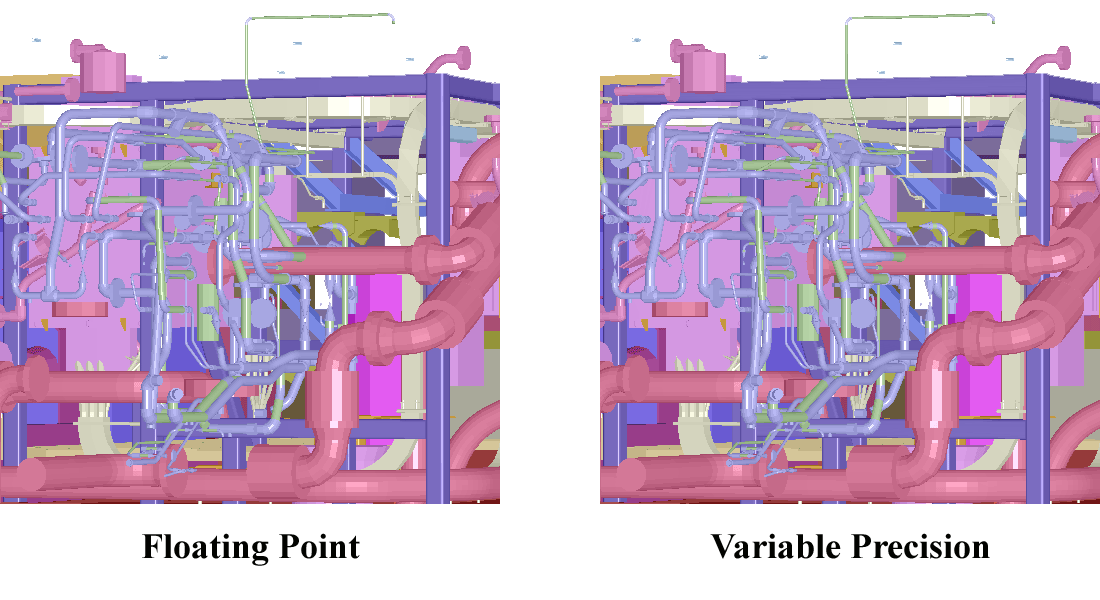
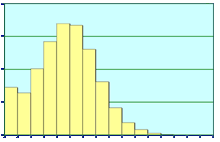
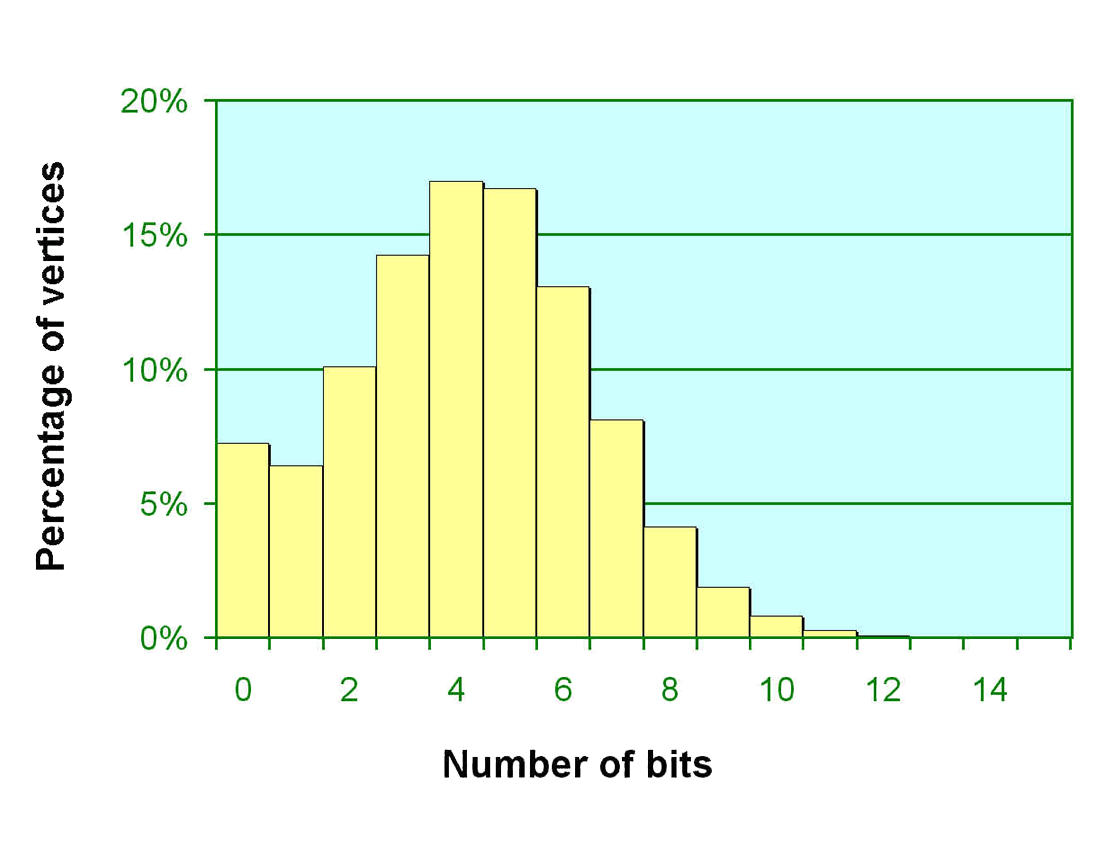
Figure on the left shows the histogram of percentage of vertices transformed in different number of bits for the Auxiliary Machine Room dataset of a notional submarine from Electric Boat Corporation of General Dynamics. We can see that on an average only 4.18 bits/vertex coordinate is needed for variable-precision transformation, instead of 32 bits/vertex coordinate as in the single-precision floating point case.
Further details can be found in the paper.

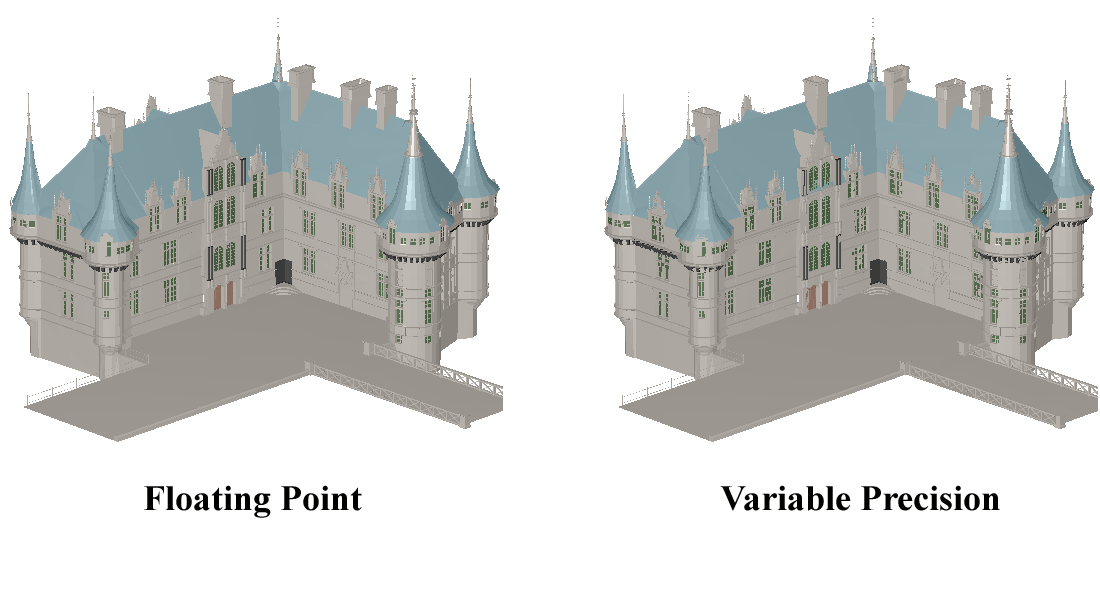
We have presented a novel approach to take advantage of SIMD parallelism in modern processors to speedup the transformation and lighting stages of the graphics pipeline. Our approach can successfully trade-off the precision for speed without significantly affecting the visual quality of the rendered images. In addition, our approach is complementary to the conventional multiresolution approaches that rely on speeding up the rendering by reducing the number of graphics primitives for display. Our work has implications in several areas including (a) transmission of 3D graphics data over low-bandwidth networks, such as wireless, (b) collaborative visualization applications in bioinformatics, engineering CAD, and medicine, and (c) display over a variety of display devices from hand-held PDAs to large-area display walls. We are currently exploring these applications.


Follow the link you can download a demo version of our source code. It is free for non-commercial use. For Commerical purpose, please contact the authors. You will need DirectX 8.0 to run the code in the windows platform with a CPU higher than Pentium II.
We want to acknowledge the following model providers:
- Electric Boat Corporation
- Cyberware Inc
- Stanford Graphics Lab
- Protein Data Bank
This material is based upon work supported by the National Science Foundation under grants ACR-98-12572 and IIS-00-81847.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.

Web Accessibility
