Parallel Understanding Systems Group
Computer Science Department,
University of Maryland at College Park
Knowledge representation systems, however, have strengths unavailable to normal database systems. They allow a complex structural representation of the data (knowledge) that allows inferencing and complex query evaluation to be performed. In addition, relations between data can be recorded as ``abstract'' relations, allowing knowledge about functional relationships, relations between groups of entities, and other such higher-level connections between the ``raw'' data elements. The PARKA-DB project is an effort to maintain and exploit these strengths of KR's, while recovering the advantages of of DBMS's, in particular the efficient storage and retrieval of massive amounts of data.
PARKA-DB is a project designed to develop a high performance knowledge representation system that deviates from the norm by using a database-management system to provide run-time storage advantages. As a KR system, PARKA-DB supports the same representational functionality as its memory-based predecessor. However, PARKA-DB goes one step further. It supports larger knowledge bases while consuming less internal memory. In fact, PARKA-DB can support knowledge bases that are as large as the available external storage. Further, since PARKA-DB claims less internal memory, it is a cost effective alternative to its predecessor since it primarily relies on the cheaper disk memory, via a DBMS, while consuming less of the more expensive internal memory. PARKA-DB is projected to be a useful KR technology for computer systems limited by main memory, running on todays smaller personal computers and individual workstations. (As a contrast, the fastest versions of Parka run on supercomputers, and take advantage of the massive amounts of memory available on these large parallel machines - see PARKA publications).
As a functional knowledge representation system, PARKA-DB is designed to support several applications including CaPER, a memory-intensive case-based reasoning system, ForMAT, a case-based logistics planning system developed by Mitre Corporation, and a set of medical informatics programs being developed at the University of Maryland (by Merwyn Taylor). One particular application class which we are now exploring is the merging of information from scientific and medical databases with associated domain knowledge, what we call a hybrid KB/DB.
Through the use of a hybrid KB/DB, the user can issue various complex and interesting queries against a database in a manner much simpler than that required to issue queries of the same meaning using a stand-alone DBMS. In particular, the complex inferencing capabilities of PARKA-DB can be utilized to formulate interesting and potentially useful conjunctive queries. In addition, data mining, the search for knowledge in databases, is another application that PARKA-DB is quite suitable for. Since data mining requires the verification of hypotheses against the data, PARKA-DB query facilities can be used to verify the strengths of hypotheses. Furthermore, by merging a data- and knowledge-based technologies, the data-mining system can find relevant relationships in the DB using taxonomical and other semantic knowledge present in the KB.
We are currently working on porting PARKA-DB to parallel architectures. The parallel implementations will provide suprerior performance while maintaining the ability to manage nearly arbitrarily large knowledge bases. Parallel implementations are planned for the SP2, T3D, Paragon, CM5, and for a distributed processing system currently being developed at the Hebrew University in Jerusalem.
To test the system loading time we compared it with the previous version of PARKA (we expected PARKA-DB to be faster, since (i) a large portion of the KB stays in secondary storage and (ii) the in-memory version requires the building of a number of data-structures which are now explicitely created by the DBMS and stored efficiently). We tested the system on three case bases used to test the CaPER memory-intensive case-based planning system. (See the PARKA KB page)
| KB | Loading Time | Frames | Structural Links | Assertions |
|---|---|---|---|---|
| 20 | .241 | 11103 | 26404 | 131817 |
| 100 | 1.288 | 56516 | 130526 | 872743 |
| 200 | 2.714 | 226297 | 266100 | 1768832 |
The table above shows the sizes and load times for the three case bases. The structural links cover all ``isa'', ``instance'', ``instanceOf'', and ``subCat'' assertions (i.e. the class ontology). The assertions column counts all other types of assertions. Times to load these knowledge bases were about 300 times as fast as in the in-memory version.
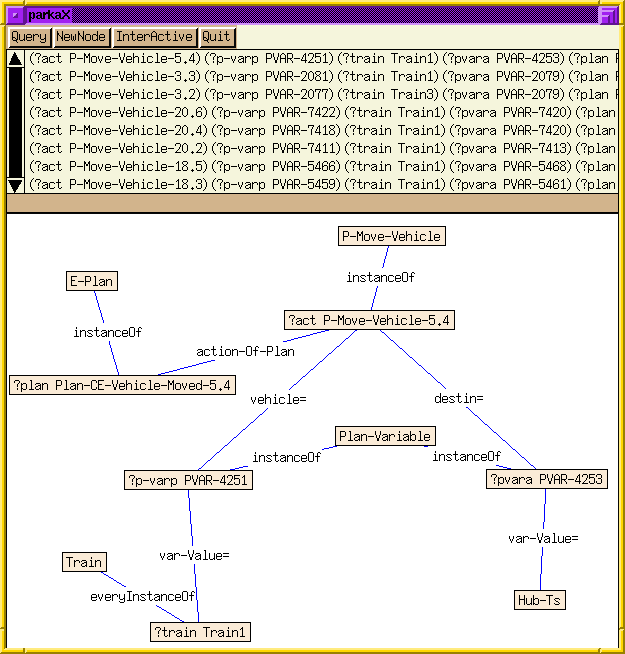
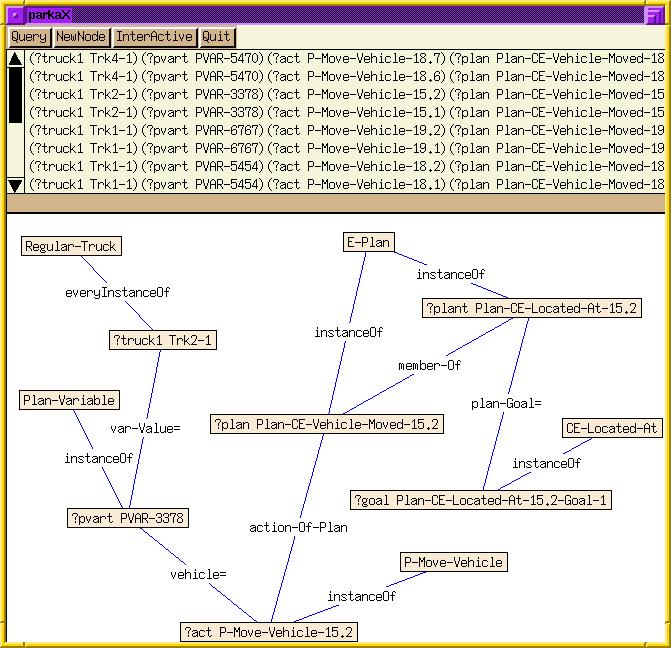
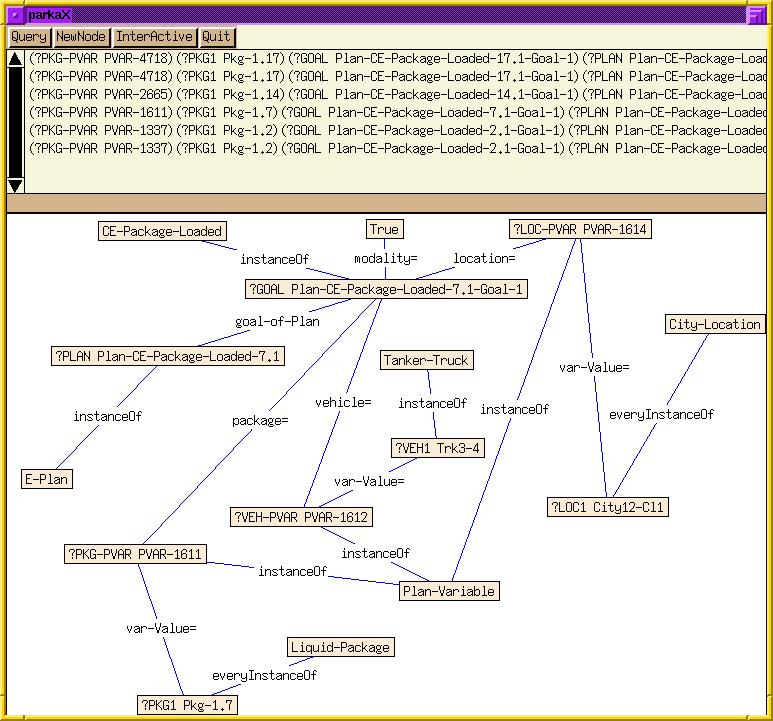
To test the decrement in query times, we evaluated three queries previously created to test CaPER using the UM-TRANSLOG planning domain. The first query, which contains 10 conjuncts concerning 5 variables, corresponds to the query "Show all plans in which a train was used to move a package through Hub-TS", the second query, with 6 variables and 11 conjuncts, asks "Show all the instances of plan steps in which a regular-truck was used as the vehicle to move a package," and the final query, with 8 variables and 15 conjuncts asks to "show all plans in which the package was a liquid package, was moved in a tanker truck, and was taken to a location that is of type 'city-location'." The graphical form of these queries (used as inputs to our system) are shown below.
The following table shows the results of the test. The values in the columns represent the pure CPU time and the CPU + IO time in seconds respectively. While these times are significantly faster than any other system we know of (except our own previous version), we believe they show the need for better optimization in our algorithms.
| Query | 20 Cases | 100 Cases | 200 Cases | |||
|---|---|---|---|---|---|---|
| 1 | .153 | .342 | 3.417 | 4.203 | 12.462 | 14.070 |
| 2 | .082 | .275 | 2.820 | 3.85 | 11.691 | 13.871 |
| 3 | 2.812 | 3.346 | 26.691 | 29.049 | 61.801 | 66.287 |
|
|
|
|
| Query 1 | Query 2 | Query 3 |
|---|