Generating future frames given a few context (or past) frames is a challenging task. It requires modeling the temporal coherence of videos as well as multi-modality in terms of diversity in the potential future states. Current variational approaches for video generation tend to marginalize over multi-modal future outcomes. Instead, we propose to explicitly model the multi-modality in the future outcomes and leverage it to sample diverse futures. Our approach, Diverse Video Generator, uses a GP to learn priors on future states given the past and maintains a probability distribution over possible futures given a particular sample. We leverage the changes in this distribution over time to control the sampling of diverse future states by estimating the end of on-going sequences. In particular, we use the variance of GP over the output function space to trigger a change in the action sequence. We achieve state-of-the-art results on diverse future frame generation in terms of reconstruction quality and diversity of the generated sequences.


Every GP trigger tries to sample a diverse trajectory:
- The person changes the course of direction at an angle
- In this the person turns around at the trigger
- The person tries to follow the ground truth
- The person turns around on first trigger and on second trigger changes the action from walking to running

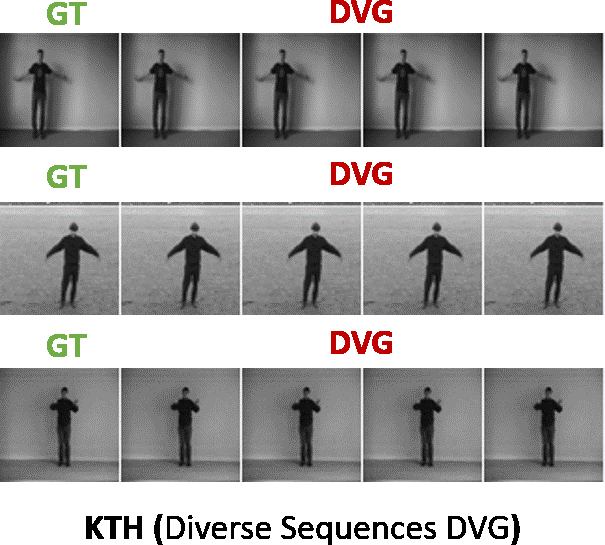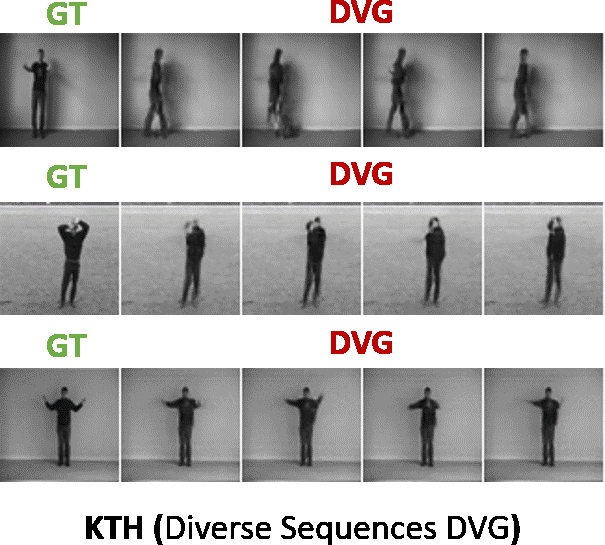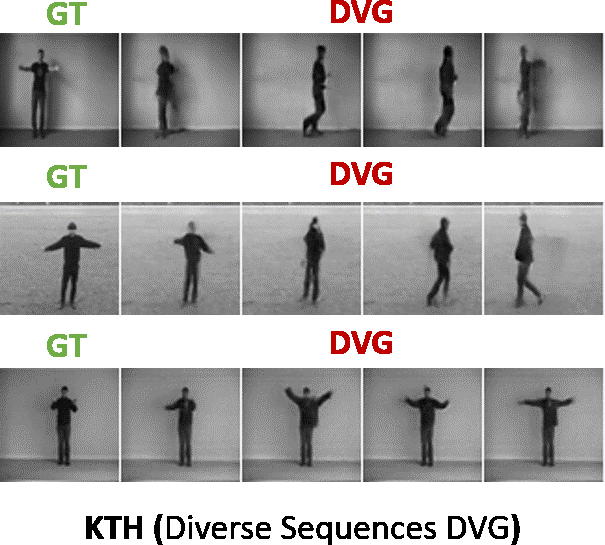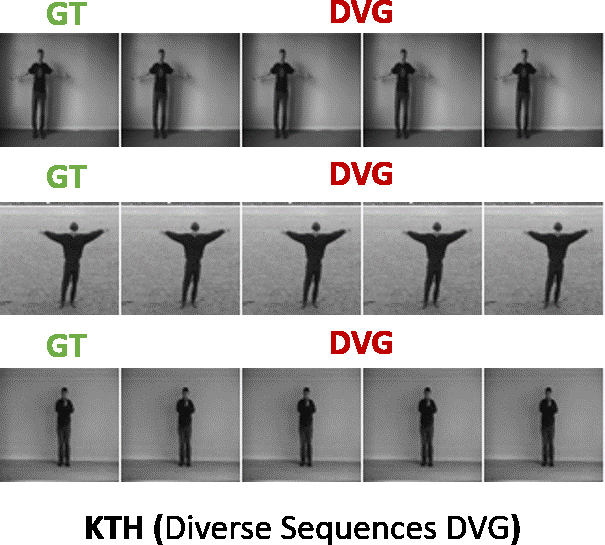
Here the generated sequence is evaluated with reference to the ground truth sequence i.e. how closely the generated sequence matches the ground truth sequence. We compared our model against the state-of-the-art baselines (SAVP, VRNN, SVG, GPLSTM) on standard datasets like KTH, BAIR, HUMAN3.6M. Our method is abbreviated as DVG










@inproceedings{
shrivastava2021diverse,
title={Diverse Video Generation using a Gaussian Process Trigger},
author={Gaurav Shrivastava and Abhinav Shrivastava},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=Qm7R_SdqTpT}
}