As you already know, a user process in GeekOS is a Kernel_Thread with an attached User_Context. Each Kernel_Thread has a field alive that indicates whether it has terminated (i.e., Exit() has been called). A Kernel_Thread also has a refCount field that indicates the number of kernel threads interested in this thread. When a thread is alive, its refCount is always at least 1 because the thread has a reference to itself. If a thread for a process is started via Start_User_Thread with a detached argument of "false", then the refCount will be 2: one self reference plus one reference from the owner. When detached is false, the owner field in the new Kernel_Thread object is initialized to point to the Kernel_Thread spawning it (aka the parent). Typically the parent of a new user process is the shell process that spawned it.
The parent-child relationship is useful when the parent wants to retrieve the returned result of its child using the Wait() system call. (We say "Wait() system call" as short for the C wrapper function to the wait system call.) For example, in the shell (src/user/shell.c), if Spawn_Program is successful, the shell calls Wait() to wait for the newly-launched child process to terminate. Wait() returns the child process's exit code. The Wait system call is implemented by using thread queues, which we explain below.
When a process terminates by calling Exit, it decrements its refCount (removing its self-reference). Moreover, when its parent calls Wait on the process, it decrements the refCount (removing the parent's reference), bringing the process's refCount to 0. When this is the case, the Reaper process is able to destroy the process, discarding its Kernel_Thread object and its associated memory.
A process that has terminated but whose refCount is non-zero is called a zombie. This means that its parent has not yet decremented refCount (bug or otherwise).
In the first two cases, the process eventually switches from the waiting state to the ready state (assuming the IO device or subprocess does not become stuck). It is removed from the queue in which it was waiting and put back in the run queue. The process continues this cycle until it terminates, at which time it is not present on any queue.
$ null.exe &
[10]
$
It could be that once a process starts to run, it may behave badly, or the work it is performing may become irrelevant. Therefore, we would like to have some way for one process to kill another process. To do this, do the following:
This is different from a thread calling Exit(). Note that when a thread is executing it is not in any queue and is only referenced in g_currentThread. Therefore when doing the cleanup of a thread that called Exit by itself it makes sense to not consider any queues. But an asynchronous kill of a process can happen at any time. Particular example scenarios are for instance when the process is waiting for its child process to die and so is in the wait queue for that process. Or when it is in the runQueue of the system. Therefore when doing this asynchronous kill you will need to ensure that you properly remove the process from every queue it is in.
Also consider what should happen when a process that a child process is terminated (which happens only if the parent is asynchronously killed). One issue concerns the parent pointer in the child process. In the current code, this pointer becomes invalid. This needs to be fixed because your modified code will be using the parent pointer to print the process table. The same thing should be done for Exit. Another issue is whether the child process's refCount should be decremented. If this is not done, the child will remain a zombie after it exits. So decrement the counter. Any other issues?
Don't kill kernel processes.
A process may kill itself. (Dumb. But handle it.)
Now that we can run many processes from the shell at once, we might like to get a snapshot of the system, to see what's going on. Therefore, you will implement a program and a system call that prints the status of the threads and processes in the system:
struct Process_Info {
char name[128];
int pid;
int parent_pid;
int priority;
int status;
};
Here, pid and parent_pid should be self-explanatory.
Kkernel processes have a parent_pid of 0.
The "name" part is the program argument to Spawn() (not the command argument);
for kernel processes this should be "{kernel}".
The "status" field should be 0 for runnable threads
(i.e., threads that are in the runQueue or actually running),
1 for blocked (i.e., threads that are waiting in some I/O queue
or child process queue),
and 2 for zombie.
The proper #defines for these, and the above struct,
are in include/geekos/user.h, which is included by include/libc/process.h.
Finally, priority is the scheduling priority number of the process.
You can get this information from the Kernel_Thread and User_Context structs,
though you may need to augment them.
When printing out the status of the process, treat it as a zombie if it is dead (i.e., in category 1 (in sec "More about process lifetimes: Zombies").
PID PPID PRIO STAT COMMANDThe PS system call stub in user space has been defined for you; its prototype appears in include/libc/process.h. Your process table must have space for at least 50 entries. Please use "%3d %4d %4d %4c %s" as the format string to achieve the formatting in the table as shown. Failure to use the format string may cause tests to fail.
1 0 1 B {kernel}
2 0 1 R {kernel}
3 0 1 B {kernel}
4 0 1 B {kernel}
5 0 1 B {kernel}
6 1 2 B /c/shell.exe
7 0 1 B /c/forktest.exe
8 7 2 R /c/null.exe
9 7 2 R /c/null.exe
10 7 2 R /c/null.exe
Privilege levels range from 0 to 3. Level 0 processes have the most privileges, level 3 processes have the least. Protection levels are also called rings in 386 documentation. Kernel processes in GeekOS run in ring 0, user processes run in ring 3. Besides limiting access to different memory segments, the privilege level also determines the set of processor operations available to a process. A program's privilege level is determined by the privilege level of its code segment.
If a process attempts to access memory outside of its legal segments, the result should be the all-too-familiar segmentation fault, and the process will be halted.
Another important function of memory segments is that they allow programs to use relative memory references. All memory references are interpreted by the processor to be relative to the base of the current memory segment. Instruction addresses are relative to the base of the code segment, data addresses are relative to the base of the data segment. This means that when the linker creates an executable, it doesn't need to specify where a program will sit in memory, only where the parts of the program will be, relative to the start of the executable image in memory.
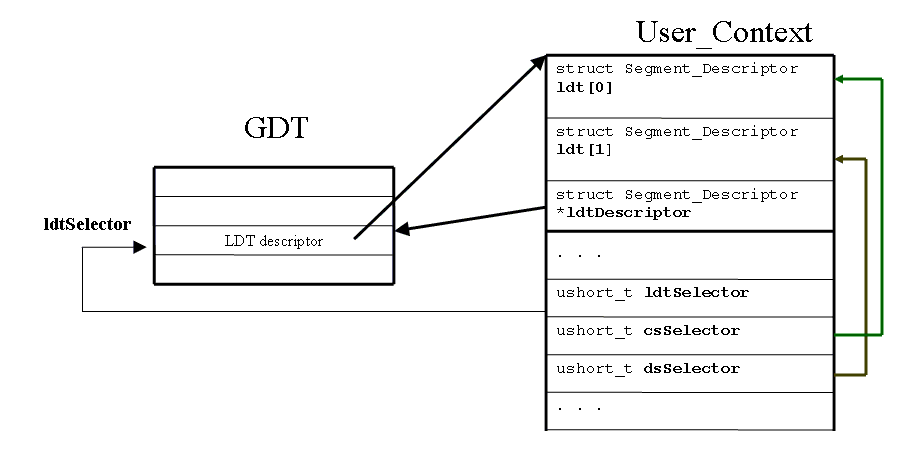
Descriptor Tables. The information describing a segment---which is logically a base address, a limit address, and a privilege level---is stored in a data structure called a segment descriptor. The descriptors are stored in descriptor tables. The descriptor tables are located in regular memory, but the format for them is exactly specified by the processor design. The functions in the processor that manipulate memory segments assume that the appropriate data structures have been created and populated by the operating system. You will see a similar approach used when you work with multi-level page tables in project 4.There are two types of descriptor tables. The Local Descriptor Table (LDT) stores the segment descriptors for each user process. There is one LDT per process. The Global Descriptor Table (GDT) contains information for all of the processes, and there is only one GDT in the system. There is one entry in the GDT for each user process which contains a descriptor for the memory containing the LDT for that process. This descriptor is essentially a pointer to the beginning of the user's LDT and its size.
Since all kernel processes are allowed to access all of memory, they can all share a single set of descriptors, which are stored in the GDT.
The relationship between GDT, LDT and User_Context entries is
explained in the picture below:
These registers do not contain the actual segment descriptors. Instead, they contain Segment Descriptor Selectors, which are essentially the indices of descriptors within the GDT and the current LDT.
The memory segments for a process are activated by loading the
address of the LDT into the LDTR and the segment selectors into the
various segment registers. This happens when the OS switches
between processes. If you like, you can follow the Schedule()
call in src/geekos/kthread.c to see how this is done (this will require
looking at some assembly code---beware!).