Assignment 4: Let there be Variables, Characters
Due: Thursday, Oct 8th at 11:59PM EST
The goal of this assignment is to extend a compiler with binding forms and a character data type.
You are given a repository with a starter compiler similar to the Fraud language we studied in class. You are tasked with:
incorporating the Con+ features you added in Assignment 3,
extending the language to include a character data type,
extending the let-binding form of the language to bind any number of variables, and
updating the parser to work for Fraud+.
From Con+ to Fraud+
Implement the abs and unary - operations and the cond form from Con+. You can start from your previous code, but you will need to update it to work for Fraud+.
In particular, functions should signal an error when applied to the wrong type of argument and your cond form should work with arbitrary question expressions. In other words, cond should work like if in Dupe.
The formal semantics of cond are defined as:
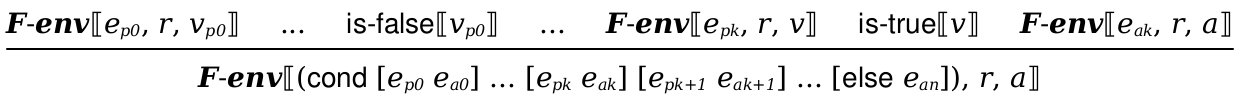
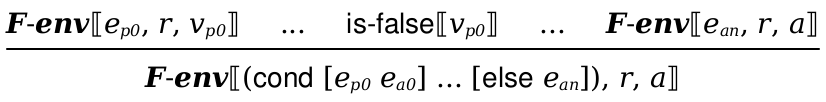
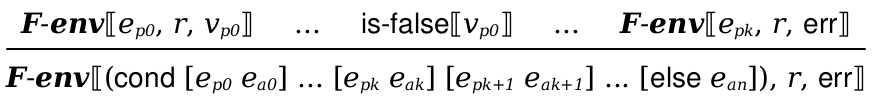
ast.rkt
syntax.rkt
interp.rkt
You will need to modify compile.rkt to correctly implement these features.
Adding a Bit of Character
Racket has a Character data type for representing single letters. A Racket character can represent any of the 1,114,112 Unicode code points.
The way a character is most often written is an octothorp, followed by a backslash, followed by the character itself. So for example the character a is written #\a. The character λ is written #\λ. The character 文 is written #\文.
A character can be converted to an integer and vice versa:
Examples
> (char->integer #\a) 97
> (char->integer #\λ) 955
> (char->integer #\文) 25991
> (integer->char 97) #\a
> (integer->char 955) #\λ
> (integer->char 25991) #\文
However, integers in the range of valid code points are acceptable to integer->char and using any other integer will produce an error:
Examples
> (integer->char -1) integer->char: contract violation
expected: (and/c (integer-in 0 #x10FFFF) (not/c
(integer-in #xD800 #xDFFF)))
given: -1
> (integer->char 55296) integer->char: contract violation
expected: (and/c (integer-in 0 #x10FFFF) (not/c
(integer-in #xD800 #xDFFF)))
given: 55296
There are a few other ways to write characters (see the Racket Reference for the details), but you don’t have to worry much about this since the lexer takes care of reading characters in all their different forms and the run-time system given to you takes care of printing them.
Your job is extend the compiler to handle the compilation of characters and implement the operations integer->char, char->integer, and char?. The operations should work as in Racket and should signal an error (i.e. 'err) whenever Racket produces an error. While you’re at it, implement the predicates integer? and boolean?, too.
The following files have already been updated for you:
ast.rkt
syntax.rkt
interp.rkt
main.c
You will need to modify compile.rkt to correctly implement these features. Note that you must use the same representation of characters as used in the run-time system and should not change main.c.
Generalizing Let
The Fraud language has a let form that binds a single variable in the scope of some expression. This is a restriction of the more general form of let that binds any number of expressions. So for example,
(let ((x 1) (y 2) (z 3)) e)
simultaneously binds x, y, and z in the scope of e.
The syntax of a let expression allows any number of binders to occur, so (let () e) is valid syntax and is equivalent to e.
The binding of each variable is only in scope in the body, not in the right-hand-sides of any of the let.
(let ((x 1) (y x)) 0)
Update syntax.rkt to define two functions:
expr? ; Any -> Boolean, which consumes anything and determines if it is a well-formed expression, i.e. it must be an instance of an Expr and each let expression must bind a distinct set of variables.
closed? ; Expr -> Boolean, which consumes an Expr and determines if it is closed, i.e. every variable occurrence is bound.
Update compile.rkt to correctly compile the generalized form of let. The compiler may assume the input is a closed expression.
Extending your Parser
Extend your Con+ parser for the Fraud+ language based on the following grammar:
<expr> ::= integer |
| character |
| boolean |
| variable |
| ( <compound> ) |
| [ <compound> ] |
|
<compound> ::= <prim> <expr> |
| if <expr> <expr> <expr> |
| cond <clause>* <else> |
| let <bindings> <expr> |
|
<prim> ::= add1 | sub1 | abs | - | zero? | integer->char | char->integer |
| char? | integer? | boolean? |
|
<clause> ::= ( <expr> <expr> ) |
| [ <expr> <expr> ] |
|
<else> ::= ( else <expr> ) |
| [ else <expr> ] |
|
<bindings> ::= ( <binding>* ) |
| [ <binding>* ] |
|
<binding> ::= ( variable <expr> ) |
| [ variable <expr> ] |
There is a lexer given to you in lex.rkt, which provides two functions: lex-string and lex-port, which consume a string or an input port, respectively, and produce a list of tokens, which are defined as follows:
Note that the Token type has changed slightly from Assignment 3: Conditional forms and parsing: 'add1 is now '(prim add1), 'cond is now '(keyword cond), etc.
; type Token = ; | Integer ; | Char ; | Boolean ; | ‘(variable ,Variable) ; | ‘(keyword ,Keyword) ; | ‘(prim ,Prim) ; | 'lparen ;; ( ; | 'rparen ;; ) ; | 'lsquare ;; [ ; | 'rsquare ;; ] ; | 'eof ;; end of file ; type Variable = Symbol (other than 'let, 'cond, etc.) ; type Keyword = ; | 'let ; | 'let* ; | 'cond ; | 'else ; | 'if ; type Prim = ; | 'add1 ; | 'sub1 ; | 'zero? ; | 'abs ; | '- ; | 'integer->char ; | 'char->integer ; | 'char? ; | 'boolean? ; | 'integer?
The lexer will take care of reading the #lang racket header and remove any whitespace.
You must complete the code in parse.rkt to implement the parser which constructs an AST representing a valid Fraud+ expression, if possible, from a list of tokens. The parse function should have the following signature and must be provided by the module:
; parse : [Listof Token] -> Expr
As an example, parse should produce (prim-e 'add1 (prim-e 'sub1 (int-e 7))) if given
'(lparen (prim add1) lparen (prim sub1) 7 rparen rparen eof)
You should not need to make any changes to lex.rkt.
The given interp-file.rkt and compile-file.rkt code no longer use read, but instead use the parser. This means you neither will work until the parser is complete.
The code you are given includes two(!) implementations of the Con+ parser. One implementation follows the imperative approach; the other follows the functional approach.
You may extend either, or you may throw out the given code and start from the code you wrote previously.
Testing
You can test your code in several ways:
Using the command line raco test . from the directory containing the repository to test everything.
Using the command line raco test <file> to test only <file>.
- Pushing to github. You can see test reports at:
(You will need to be signed in in order see results for your private repo.)
Note that only a small number of tests are given to you, so you should write additional test cases.
We have removed random.rkt and instead provide a random-exprs.rkt module which provides exprs, a list of 500 closed expressions. It is used in the test/compile-rand.rkt file to randomly test compiler correctness. This should help speed up the testing process since the random generation is slow.
Submitting
Pushing your local repository to github “submits” your work. We will grade the latest submission that occurs before the deadline.
Extra Credit
Similar to let there is also let* that also binds any number of expressions. The difference is that previous bindings are available to subsequent bindings. For example,
(let* ((x 1) (y 2) (z (add1 y))) e)
binds x to 1, y to 2, and z to 3 in the scope of e.
The syntax of a let* expression allows any number of binders to occur, so (let* () e) is valid syntax and is equivalent to e.
(let* ((x 1) (y x)) 0)
No files have already been updated for you. You’re on your own for this one. You’ll need to make new AST nodes, change the lexer and parser, extend every function that traverses the AST, expr?, closed?, etc., the interpreter and the compiler. Do you need to alter main.c? You tell me.
If you choose to do this extra credit it will be worth 15 points. There will be no autograder, so if you want to points you have to schedule time with the instructor to look over your solution. You need to schedule the time before the deadline, but the meeting can happen after the deadline.