2.4.2. The Conflict Resolution (CR) Toolkit
The purpose of the conflict resolution toolkit is to assist the mediator author in dealing with semantic conflicts that might arise during semantic integration. A menu of commonly used strategies is available to the mediator author. For each predicate defined in the mediator, the mediator author has the option of choosing to apply one of these conflict resolution strategies. Each strategy selected will cause the CR Toolkit to generate a set rules that becomes a part of the mediator. On the other hand, the mediator author may define a new strategy by writing a set of rules. The learning module (cf. Section 2.4.4) will then attempt to determine whether the rules embodies a strategy that should be developed further for future use. Below, we specify some existing conflict resolution strategies currently implemented in the toolkit, and describe how these facilities are incorporated into the mediator compiler.
We assume a background set of integrity constraints that expresses invariant semantical relationships between different data sources. The syntactic forms of these constraints are not important for our discussion.
Latest Data Preference Strategy: Very simply, this strategy says that preference is given to temporally more recent data. To accommodate this, the mediator accesses a special domain implemented in HERMES called HTIME (for HERMES time). HTIME contains a domain operation called timefind that takes a relation name, say r, and a tuple t as input. It first checks if the relation r has associated time-stamp information. Recall that during domain integration, this information may either be explicitly included by the domain integrator, or implicitly generated by the mediator compiler and stored in the data() declaration. If a time-stamp exists, a temporal conversion function supplied by the domain integrator is invoked with r as input. The value returned is the time, normalized to a global clock maintained internally by HERMES. If relation r has no associated time-stamp information, then timefind examines the appropriate data declarations in the mediator to determine the time at which relation r was introduced into the mediator system. This time is used as the time at which the data was created. Using the results returned by timefind, the most recent data is selected whenever conflicting data arises.
Predicate Preference Strategy: Many databases may define concepts that are essentially the same. Consider a PARADOX relation called part1 and a DBASE relation called part2. Suppose part1 has a field color, and part2 has a field col. Though part1.color and part2.col are syntactically distinct, they in fact refer to the same semantic concept, viz. color. The CR-Toolkit allows a mediator author to express that in the Paradox domain, if PARADOX:part1.name=DBASE:part2.name, then part1 and part2 are the same, and hence their colors should be identical, i.e. PARADOX:part1.color=DBASE:part2.col. The system, upon recognizing this integrity constraint, will generate all possible violations. For each violation, it asks the mediator author to indicate a preference between the two relations. Hence the mediator author may say, for instance, that the PARADOX database's information is to be preferred with respect to color, but that the DBASEs value is to be preferred with respect to price. Once the indications are made, rules are generated by the CR-toolkit to reflect these preferences.
Object Preference Strategy: The idea here is similar to predicate preference except that preference is indicated over individual objects. Hence it relies on the assumption that certain databases have more reliable knowledge of the attributes of certain objects than other databases. For example, a mediator author may note that what is called ``dog'' in one database is identical to what is called ``chien'' in another. Furthermore, a preference may be expressed that values of all attributes associated with ``dog'' in a database override values stored for the same attributes in other databases. The CR-Toolkit allows the mediator author to interactively express such preferences, and automatically generates the appropriate rules that will be placed in the mediator.
Value-Based Preference Strategy: Value-based conflict resolution may be appropriate for certain business applications. In this strategy, the user can specify that when two numeric fields disagree, either the higher or the lower value ought to be picked. Hence for instance, the integrity constraint
PARADOX:part1.name=DBASE:part2.name => PARADOX:part1.price=DBASE:part2.cost.
says (assuming identical currencies) that two parts should have the same price in both PARADOX and DBASE databases. However, should this constraint fail, the mediator-author who is writing the mediator on behalf of the company that produces these products may choose to quote the higher price. This is an example of a value-based preference strategy. The CR-Toolkit allows the user to interactively express such preferences. Again, appropriate rules will be generated by the toolkit and placed in the mediator.
Criticality Number Strategy: Recall that when creating the mediator, the mediator author includes various declarations such as the data declarations described earlier. Similarly, we have a special declaration called a criticality declaration of the form
criticality(filename):Crit,
where Crit is a real number. The higher it is, the more ``reliable'' is the data in that domain. The Criticality Number Strategy allows the user to use the rather coarse indication that all data in a domain of a specified criticality c1 is ``more reliable'' than all data in a domain of criticality c2<c1 broad, sweeping strategy may be used as the default in cases where, for example, the mediator author does not truly believe that conflicts will arise.
Information pooling is a complicated matter. It is further
complicated when the sources from which the information is pooled
differ vastly from one another, both in structure, and in content. To
facilitate this process, the IP-Toolkit consists of a number of
subtoolkits that allow integration both within a given domain, as well
as integration across different but similar domains, as well as
integration across multiple and dissimilar domains. For example,
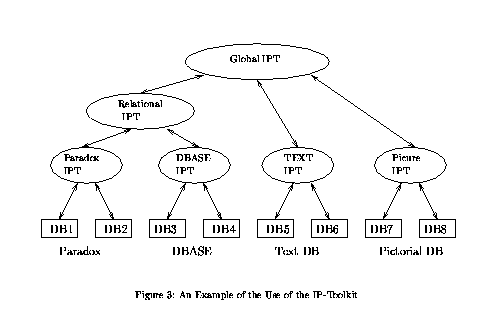
suppose integration is to be performed over eight databases (call them
DB1,...,DB8). Suppose moreover that DB1 and
DB2 are PARADOX
databases, DB3 and DB4 are DBASE databases,
DB5 and DB6 are
text databases, and DB7 and DB8 are pictorial databases.
Figure 3
shows how the IP Toolkit in HERMES would accomplish the desired
integration. As can be seen from Figure 3, the IP-toolkit contains
many ``sub-toolkits'' that need to be independently developed. Each
of these subtoolkits allows the generation of some rules (but not all)
within the mediator. Using the subtoolkits leads to a stepwise
procedure. For instance, in Figure 3, the mediator author could
define certain rules in the mediator by using the PARADOX
IP Toolkit;
similarly, he may define certain rules in the mediator by using the
DBASE IP toolkit; he may then define new mediator rules based on
these intermediate definitions, perhaps in conjunction with the
relational IP toolkit.
Intra-Domain Sub-Toolkits:
Often, there may be relatively efficient ways of integrating
information within a given domain. For example, if a number of
different databases are all developed using PARADOX, then as they are
all structurally similar, it would be easier perform integration over
these databases first whenever possible, before doing integration
with data sources implemented in other database management systems.
As an example, consider the integration of the two PARADOX
databases DB1 and DB2 in Figure 3.
These databases may have
relations called emp_comp1
and emp_comp2, respectively,
showing the employee records of two companies.
It may turn out that a particular employee obtains money from both;
in such cases, the mediator author may wish to write a rule of the form:
Note that the name (resp. salary) fields of the
emp_comp1 relation in DB1 are identical to
the nom (resp. sal) fields in DB2.
In this example, the PARADOX Intra-Domain Sub-Toolkit
would present, for
each database in the PARADOX domain, relation-attribute pairs of the
form R.A and ask the mediator author for assistance in
grouping together
semantically ``equivalent'' R.A pairs. In the preceding example, this
involves grouping together
the pairs (db1.emp_comp1).salary and
(db2.emp_comp2).sal in one group, and
(db1.emp_comp1).name and
(db1.emp_comp1).nom in another.
Within any given domain, the mediator author must specify the
structures
of interest with respect to grouping. Once this specification is
written, the mediator author would need to implement code that
accomplishes this grouping.
Note, however, that this code needs to be implemented only the first time a new
domain is integrated -- for example, if we merely wish to add a new
PARADOX database, say DB9, then there is no need to re-implement
this grouping code.
Sub-Toolkits for Integrating ``Similar'' Domains:
Formally, DBASE and PARADOX
are two different domains; however,
these two domains share several characteristics. For example, as
they are both relational database management systems, hence the
operations of select, project and
join are common to both of them. So are many other aggregate
operations including SUM, MIN,
MAX, and COUNT.
Therefore, it may be advantageous to create a sub-toolkit that accesses
the predicates that have been defined in the mediator using the
PARADOX and
DBASE IP subtoolkits, and then
using them to define other parts of the mediator.
This is the purpose of the sub-toolkits for integrating
similar domains -- the mediator author, though,
is left to decide which domains are similar.
Just as in the case of the Intra-domain subtoolkits, the
subtoolkits for integrating similar domains are used to group
structures together. For example, in the case of say
PARADOX and
DBASE this involves grouping together pairs (R1.A1) from
the PARADOX domain with pairs (R2.A2) from the
DBASE domain.
Thus, for instance, the mediator author may specify that
(db2.emp_comp2).sal in the PARADOX domain is the same as
(db3.employee).income in the DBASE domain.
Sub-Toolkits for Integrating Diverse Domains:
At this point in our system, this integration must be done by the
mediator author. The GUI for the MPE merely serves as a tool
for expressing the mediation rules.
Though small, an important aspect of the HERMES mediator programming
environment is a facility for learning.
When a mediator author develops a mediator, strategies other
than the ones available in the CR-Toolkit may be necessary. Thus the
mediator author needs to specify such a strategy through a set of
mediator rules. This set, appropriately generalized, may be useful
across a sufficiently large number of mediation tasks, that storing it as
a new strategy in the CR-Toolkit for later use is worthwhile.
The decision on whether the new strategy will be useful in the future
lies with the mediator author, while the appropriate generalization to
the set of rules may often be generated automatically. In
certain cases the mediator author may need to manually adjust the
strategy thus generated.
A similar learning component may be developed for the Information
Pooling Toolkit.
[ Top ]
[ Previous Section ]
[ Next Section ]
2.4.3. The Information Pooling (IP) Toolkit
in(Sal2,PARADOX:project(select=('db2.emp_comp2',"nom",X)"sal")) &
Sal = Sal1 + Sal2.
2.4.4. Learning in HERMES
![]() Click here to go back to the Hermes homepage .
Click here to go back to the Hermes homepage .