|
Current Image-to-Image translation (I2I) frameworks rely heavily on reconstruction losses,
where the output needs to match a given ground truth image. An adversarial loss is commonly utilized as a secondary loss term,
mainly to add more realism to the output. Compared to unconditional GANs, I2I translation frameworks have more supervisory signals,
but still their output shows more artifacts and does not reach the same level of realism achieved by unconditional GANs.
We study the performance gap, in terms of photo-realism, between I2I translation and unconditional GAN frameworks.
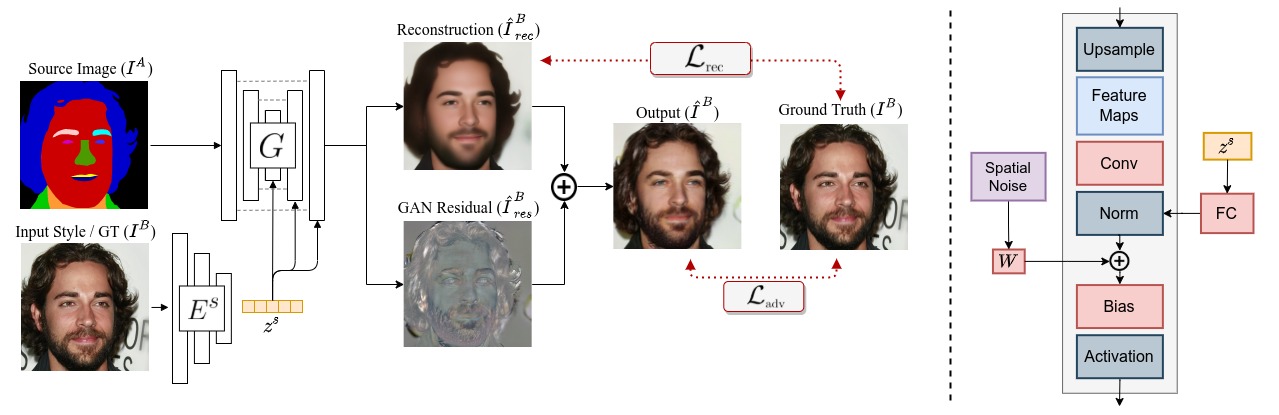
Based on our observations, we propose a modified architecture and training objective to address this realism gap.
Our proposal relaxes the role of reconstruction losses, to act as regularizers instead of doing all the heavy lifting which is
common in current I2I frameworks. Furthermore, our proposed formulation decouples the optimization of reconstruction and adversarial
objectives and removes pixel-wise constraints on the final output. This allows for a set of stochastic but realistic variations of any target output image.
|