Latent-INR: A Flexible Framework for Implicit Representations of Videos with Discriminative Semantics
Abstract
Implicit Neural Networks (INRs) have emerged as powerful representations to encode all forms of data, including images, videos, audios, and scenes. With video, many INRs for video have been proposed for the compression task, and recent methods feature significant improvements with respect to encoding time, storage, and reconstruction quality. However, these encoded representations lack semantic meaning, so they cannot be used for any downstream tasks that require such properties, such as retrieval. This can act as a barrier for adoption of video INRs over traditional codecs as they do not offer any significant edge apart from compression. To alleviate this, we propose a flexible framework that decouples the spatial and temporal aspects of the video INR. We accomplish this with a dictionary of per-frame latents that are learned jointly with a set of video specific hypernetworks, such that given a latent, these hypernetworks can predict the INR weights to reconstruct the given frame. This framework not only retains the compression efficiency, but the learned latents can be aligned with features from large vision models, which grants them discriminative properties. We align these latents with CLIP and show good performance for both compression and video retrieval tasks. By aligning with VideoLlama, we are able to perform open-ended chat with our learned latents as the visual inputs. Additionally, the learned latents serve as a proxy for the underlying weights, allowing us perform tasks like video interpolation. These semantic properties and applications, existing simultaneously with ability to perform compression, interpolation, and superresolution properties, are a first in this field of work.
1) Overview
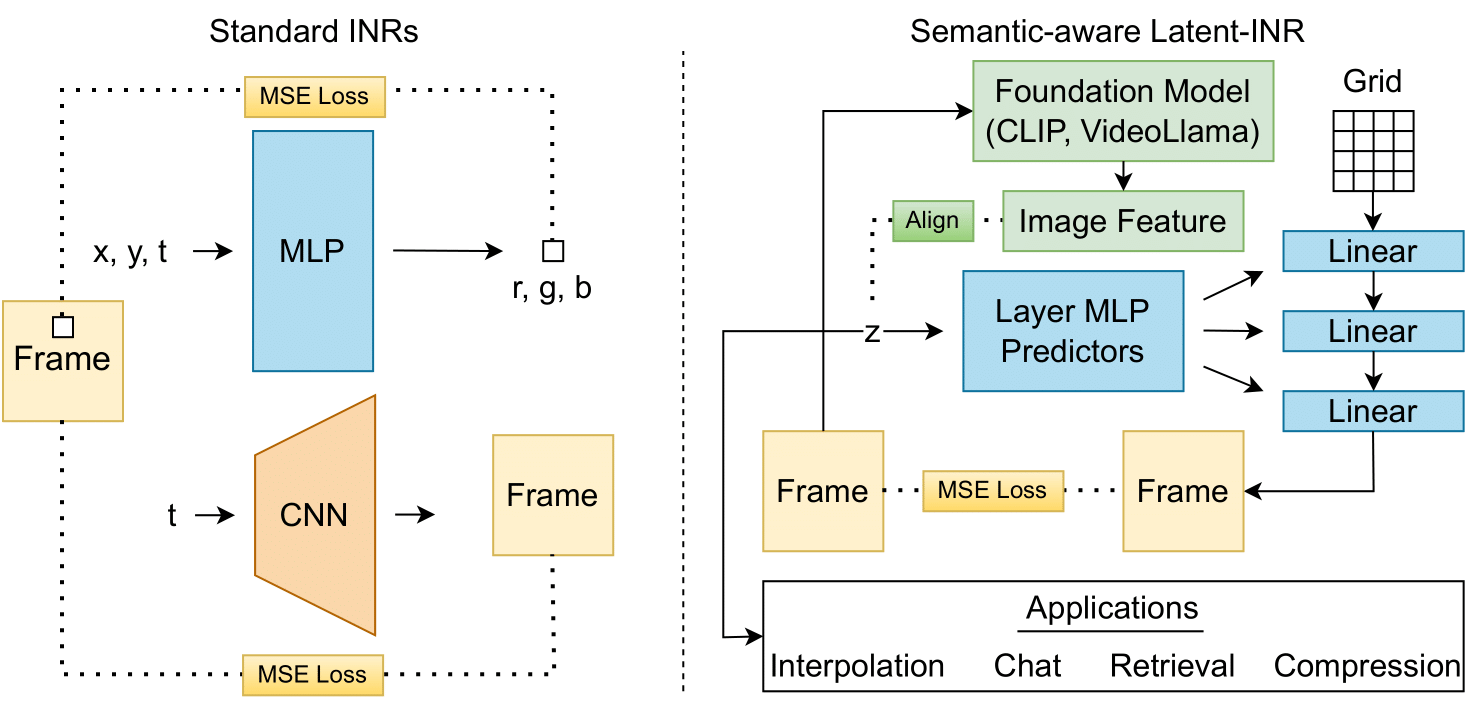
Prior video INR works perform either pixel-wise or frame-wise prediction. We instead perform spatio-temporal patch-wise prediction and fit individual neural networks to groups of frames (clips) which are initialized using networks trained on the previous group. Such an autoregressive patch-wise approach exploits both spatial and temporal redundancies present in videos while promoting scalability and adaptability to varying video content, resolution or duration.
2) Model architecture

The website template was borrowed from Ben Mildenhall.