2018-06-01
Many imaging tasks require global information about all pixels in an image. For example, the output of an image classifier may depend on many pixels in separate regions of an image. For image segmentation, in which a neural network must produce a high-resolution map of classifications rather than a single output, each pixel’s label may depend on information from far away pixels.
Conventional bottom-up classification networks globalize information by decreasing resolution; features are pooled and downsampled into a single output that “sees” the whole image. But for semantic segmentation, object detection, and other image-to-image regression tasks, a network must preserve and output high-resolution maps, and so pooling alone is not an option. To globalize information while preserving resolution, many researchers propose the inclusion of sophisticated auxiliary blocks, but these come at the cost of a considerable increase in network size, computational cost, and implementation complexity.
Stacked u-nets (SUNets) iteratively combine features from different resolution scales while maintaining resolution. SUNets leverage the information globalization power of u-nets in a deeper network architectures that is capable of handling the complexity of natural images.

The SUNets architectures are loosely based off ResNets, however the residual blocks have been replaces with u-net blocks that communicate information globally across the entire image. This multi-scale communication between pixels enables SUNets to globalize information without pooling layers, and produce rich, high-resolution feature maps using a relatively small number of layers are parameters.
SUNets perform extremely well on semantic segmentation tasks (top 2 on PASCAL VOC challenge) using a small number of parameters and a simple portable architecture. SUNets also train relatively fast and with relatively low memory requirements, making them a practical choice as a component in more complex systems.
Examples
The PASCAL VOC challenge requires a system to label image pixels if they lie in certain identified classes, and leave pixels black if they do not. Here, we show example SUNet segmentations of images containing instances from the person, dog, sheep, and bird classes.
Notice that SUNets perform well at segmenting objects with a range of different scales; in several examples the network is able to identify large foreground objects in addition to small instances of people in the background.





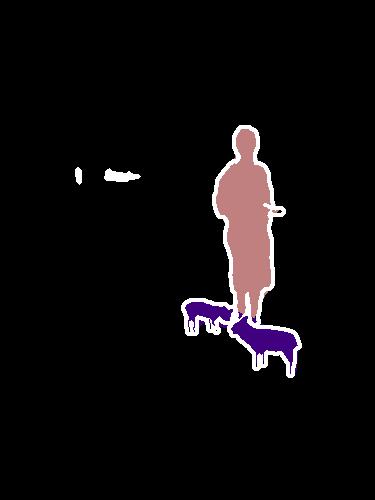
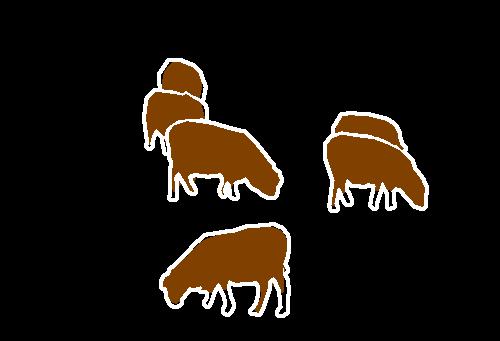



SUNet resources
The paper describing SUNets and an example implementation are available below.