“Adversarial training,” in which a network is trained on adversarial examples, is one of the few defenses against adversarial attacks that withstands strong attacks. Unfortunately, the high cost of generating strong adversarial examples makes standard adversarial training impractical on large-scale problems like ImageNet. We present an algorithm that eliminates the overhead cost of generating adversarial examples by recycling the gradient information computed when updating model parameters.
Our “free” adversarial training algorithm is comparable to state-of-the-art methods on CIFAR-10 and CIFAR-100 datasets at negligible additional cost compared to natural training, and can be 7 to 30 times faster than other strong adversarial training methods.
Using a single workstation with 4 P100 GPUs and 2 days of runtime, we can train a robust model for the large-scale ImageNet classification task that maintains 36% accuracy against untargeted PGD attacks.
Keeping with the theme of this project, both our paper and code are totally FREE!
Adversarial Training for Free! @ arXiv
Free ImageNet Training @ GitHub
Free CIFAR-10 & CIFAR-100 Training @ GitHub
Similarity to regular (expensive) adversarial training
Is is known that adversarially trained classifiers have generative behaviors. When an image is perturbed from one class to another, it adopts features that make it “look” like its adopted class.
Free trained models exhibit this same generative behavior, as shown in the figure below. (top row) Clean images. (middle row) Adversarial images for a 7-PGD adversarially trained CIFAR-10 model. (bottom row) adversarial examples for the “free” adversarial trained model. To avoid cherry picking, we display the last 9 images of the validation set.

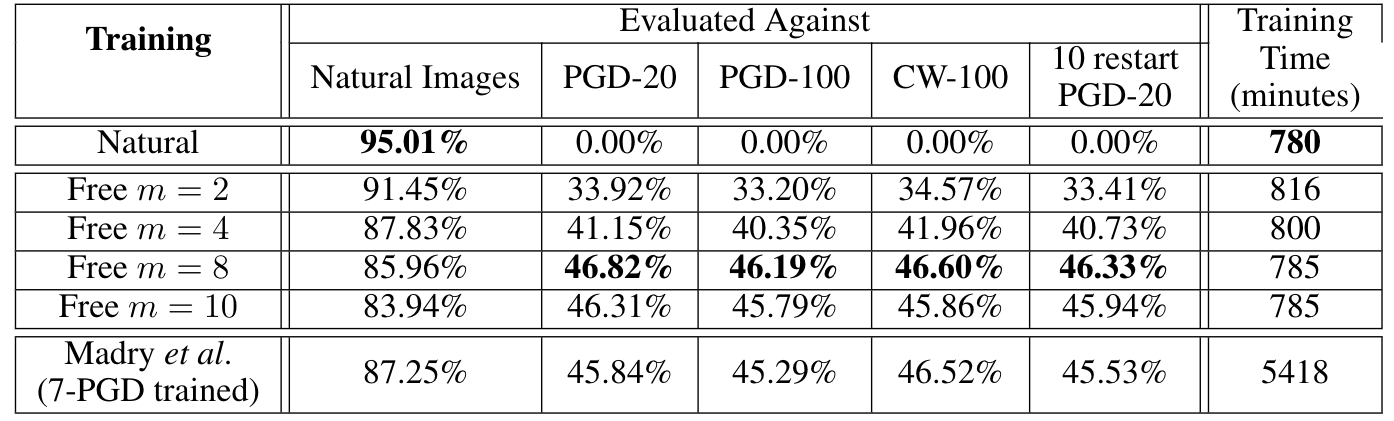
Selected CIFAR Results
Free adversarial training often bear conventional (expensive) adversarial training on CIFAR-10, and beats it by a wide margin on CIFAR-100. Here’s some results showing the robustness of free classifiers on CIFAR-10 with different choices of the “replay” parameter “m” introduced in our paper, in addition to the results of conventional PGD adversarial training.
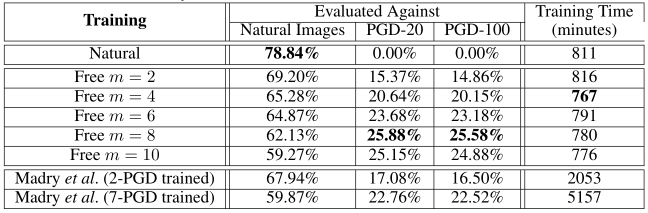
Here’s some results for CIFAR-100. We found that free training was extremely effective for this problem.
Selected ImageNet Results
Here’s some results showing the accuracy of “free” robust networks against a range of untargeted attacks. Note that a clean-trained classifier gets 0% accuracy against all of these attacks.
