Why are GANs hard to train?
Adversarial neural networks solve many important problems in data science, but are notoriously difficult to train. These difficulties come from the fact that optimal weights for adversarial nets correspond to saddle points, and not minimizers, of the loss function. The alternating stochastic gradient methods typically used for such problems do not reliably converge to saddle points, and when convergence does happen it is often highly sensitive to learning rates.
Standard Neural Net
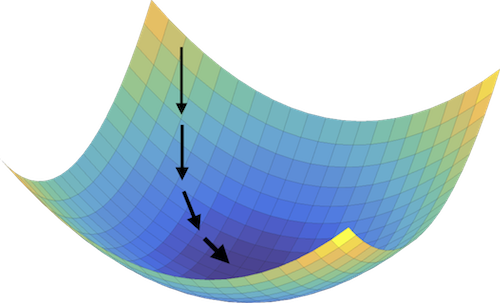
Adversarial Net
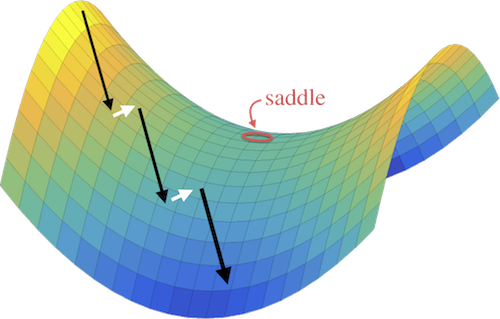
(left) Standard neural nets are stable because the training path gets "stuck" in a minimizer of the loss function. (right) Adversarial training methods alternate between minimization and maximization steps to converge to a saddle point of the loss function. This is potentially unstable because the iterates will "slide off" the side of the saddle if the minimization overpowers the maximization (or vise-vera).
Our contributions
We propose a simple modification of stochastic gradient descent that stabilizes adversarial networks. We show, both in theory and practice, that the proposed method reliably converges to saddle points, and is stable with a wider range of training parameters than a non-prediction method. This makes adversarial networks less likely to “collapse,” and enables faster training with larger learning rates.
Our method is described in detail in our recent paper:
Example
Using prediction methods, we can train a variety of GANs using a wider range of SGD hyper-parameters than without prediction. In the case of DC-GAN, we’re able to train with a learning rate 10X higher than in the standard implementation. We find that the stabilizing effect of prediction is particularly strong for high resolution images (64x64 or higher), and mild for lower resolution examples.
Prediction

Standard DC-GAN

Unrolled GAN
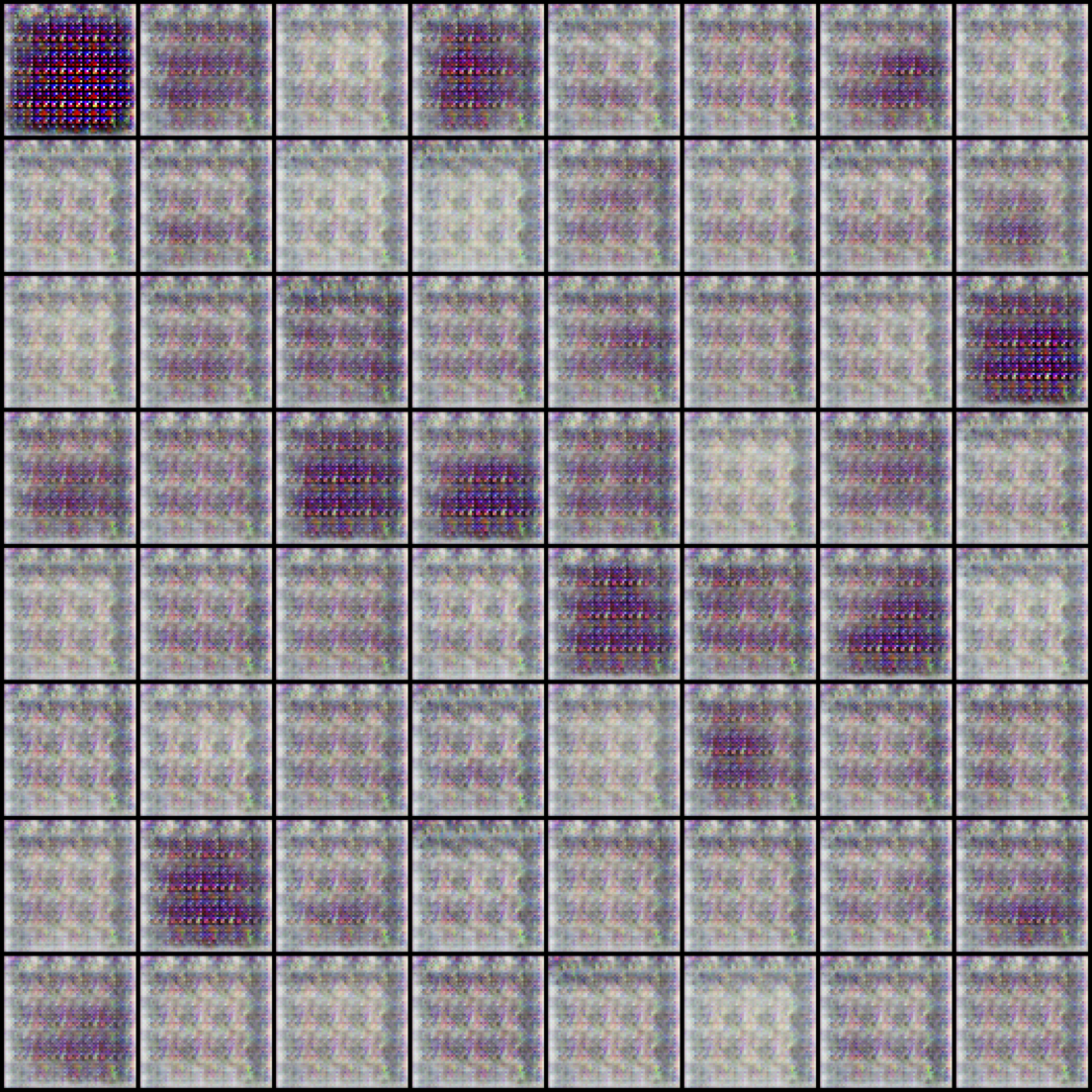
DC-GAN results using a large learning rate. The GAN collapses when using a standard implementation or an unrolled training algorithm. Using the prediction method, we're able to train stably with a wider range of hyper-parameters.
Acknowledgements
![]() This work was made possible by the generous support of the Office of Naval research, and was done is collaboration with the United Stated Naval Academy.
This work was made possible by the generous support of the Office of Naval research, and was done is collaboration with the United Stated Naval Academy.