15 Exception handling and floating point pipelines
Dr A. P. Shanthi
The objectives of this module are to discuss about exceptions and look at how the MIPS architecture handles them. We shall also discuss other issues that complicate the pipeline.
Exceptions or interrupts are unexpected events that require change in flow of control. Different ISAs use the terms differently. Exceptions generally refer to events that arise within the CPU, for example, undefined opcode, overflow, system call, etc. Interrupts point to requests coming from an external I/O controller or device to the processor. Dealing with these events without sacrificing performance is hard. For the rest of the discussion, we will not distinguish between the two. We shall refer to them collectively as exceptions. Some examples of such exceptions are listed below:
• I/O device request
• Invoking an OS service from a user program
• Tracing instruction execution
• Breakpoint
• Integer arithmetic overflow
• FP arithmetic anomaly
• Page fault
• Misaligned memory access
• Memory protection violation
• Using an undefined or unimplemented instruction
• Hardware malfunctions
• Power failure
There are different characteristics for exceptions. They are as follows:
• Synchronous vs Asynchronous
• Some exceptions may be synchronous, whereas others may be asynchronous. If the same exception occurs in the same place with the same data and memory allocation, then it is a synchronous exception.
They are more difficult to handle.
• Devices external to the CPU and memory cause asynchronous exceptions. They can be handled after the current instruction and hence easier than synchronous exceptions.
• User requested vs Coerced
• Some exceptions may be user requested and not automatic. Such exceptions are predictable and can be handled after the current instruction.
• Coerced exceptions are generally raised by hardware and not under the control of the user program. They are harder to handle.
• User maskable vs unmaskable
• Exceptions can be maskable or unmaskable. They can be masked or unmasked by a user task. This decides whether the hardware responds to the exception or not. You may have instructions that enable or disable exceptions.
• Within vs Between instructions
• Exceptions may have to be handled within the instruction or between instructions. Within exceptions are normally synchronous and are harder since the instruction has to be stopped and restarted. Catastrophic exceptions like hardware malfunction will normally cause termination.
• Exceptions that can be handled between two instructions are easier to handle.
• Resume vs Terminate
• Some exceptions may lead to the program to be continued after the exception and some of them may lead to termination. Things are much more complicated if we have to restart.
• Exceptions that lead to termination are much more easier, since we just have to terminate and need not restore the original status.
Therefore, exceptions that occur within instructions and exceptions that must be restartable are much more difficult to handle.
Exceptions are just another form of control hazard. For example, consider that an overflow occurs on the ADD instruction in the EX stage:
ADD $1, $2, $1
We have to basically prevent $1 from being written into, complete the previous instructions that did not have any problems, flush the ADD and subsequent instructions and handle the exception. This is somewhat similar to a mispredicted branch and we can use much of the same hardware. Normally, once an exception is raised, we force a trap instruction into the pipeline on the next IF and turn off all writes for the faulting instruction and for all instructions that follow in the pipeline, until the trap is taken. This is done by placing zeros in the latches, thus preventing any state changes till the exception is handled. The exception-handling routine saves the PC of the faulting instruction in order to return from the exception later. But if we use delayed branching, it is not possible to re-create the state of the processor with a single PC because the instructions in the pipeline may not be sequentially related. So we need to save and restore as many PCs as the length of the branch delay plus one. This is pictorially depicted in Figure 15.1

Once the exception has been handled, control must be transferred back to the original program in the case of a restartable exception. ISAs support special instructions that return the processor from the exception by reloading the PCs and restarting the instruction stream. For example, MIPS uses the instruction RFE.
If the pipeline can be stopped so that the instructions just before the faulting instruction are completed and those after it can be restarted from scratch, the pipeline is said to have precise exceptions. Generally, the instruction causing a problem is prevented from changing the state. But, for some exceptions, such as floating-point exceptions, the faulting instruction on some processors writes its result before the exception can be handled. In such cases, the hardware must be equipped to retrieve the source operands, even if the destination is identical to one of the source operands. Because floating-point operations may run for many cycles, it is highly likely that some other instruction may have written the source operands. To overcome this, many recent processors have introduced two modes of operation. One mode has precise exceptions and the other (fast or performance mode) does not. The precise exception mode is slower, since it allows less overlap among floating point instructions. In some high-performance CPUs, including Alpha 21064, Power2, and MIPS R8000, the precise mode is often much slower (> 10 times) and thus useful only for debugging of codes.
Having looked at the general issues related to exceptions, let us now look at the
MIPS architecture in particular. The exceptions that can occur in a MIPS pipeline are:
• IF – Page fault, misaligned memory access, memory protection violation
• ID – Undefined or illegal opcode
• EX – Arithmetic exception
• MEM – Page fault on data, misaligned memory access, memory protection violation
• WB – None
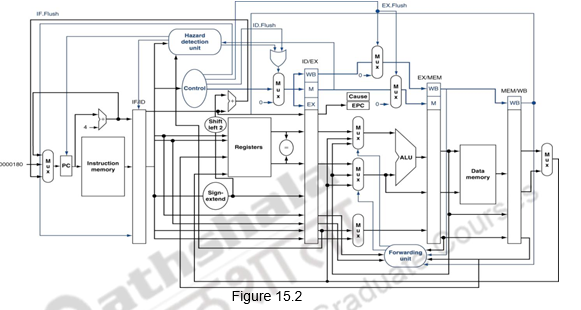
In MIPS, exceptions are managed by a System Control Coprocessor (CP0). It saves the PC of the offending or interrupted instruction. A register called the Exception Program Counter (EPC) is used for this purpose. We should also know the cause of the exception. This gives an indication of the problem. MIPS uses a register called the Cause Register to record the cause of the exception. Let us assume two different types of exceptions alone, identified by one bit – undefined instruction = 0 and arithmetic overflow = 1. In order to handle these two registers, we will need to add two control signals EPCWrite and CauseWrite. Additionally, we will need a 1-bit control signal to set the low-order bit of the Cause register appropriately, say, signal IntCause. In the MIPS architecture, the exception handler address is 8000 0180.
The other way to handle exceptions is by Vectored Interrupts, where the handler address is determined by the cause. In a vectored interrupt, the address to which control is transferred is determined by the cause of the exception. For example, if we consider two different types of exceptions, we can define the two exception vector addresses as Undefined opcode: C0000000, Overflow: C0000020. The operating system knows the reason for the exception by the address at which it is initiated. To summarize, the instructions either deal with the interrupt, or jump to the real handler. This handler reads the cause and transfers control to the relevant handler which determines the action required. If it is a restartable exception, corrective action is taken and the EPC is used to return to the program. Otherwise, the program is terminated and error is reported. Figure 15.2 shows the MIPS pipeline with the EPC and Cause registers added and the exception handler address added to the multiplexor feeding the PC.
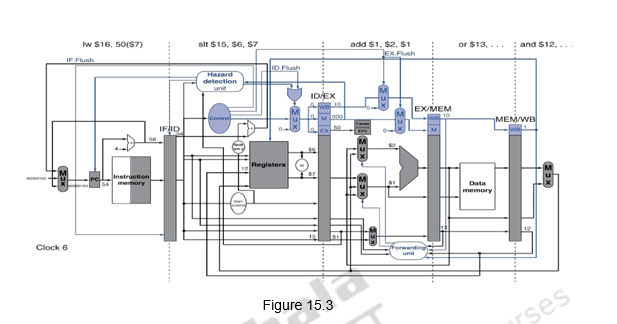
Let us look at an example scenario and discuss what happens in the MIPS pipeline when an exception occurs. Consider the following code snippet and assume that the add instruction raises an exception in the execution stage. This is illustrated in Figure 15.3. During the 6th clock cycle, the add instruction is in the execution stage, the slt instruction is in the decode stage and the lw instruction is in the fetch stage.
40 sub $11, $2, $4
44 and $12, $2, $5
48 or $13, $2, $6
4C add $1, $2, $1
50 slt $15, $6, $7
54 lw $16, 50($7)
Once the exception in the execution stage is raised, bubbles are inserted in the pipeline starting from the instruction causing a problem, i.e. add in this case. The earlier instructions are allowed to proceed normally. During the next clock cycle, i.e. the 7th clock cycle, a sw $25, 1000($0) instruction is let into the pipeline to handle the exception. This is indicated in Figure 15.4.

Another complication that we need to consider is the fact that multiple exceptions may occur simultaneously, say in the IF and MEM stage and also exceptions may happen out of order. The instruction in the earlier stage, say, IF may raise an exception and then an instruction in the EX stage may raise an exception. Since pipelining overlaps multiple instructions, we could have multiple exceptions at once and also out of order. However, exceptions will have to be handled in order. Normally, the hardware maintains a status vector and posts all exceptions caused by a given instruction in a status vector associated with that instruction. This exception status vector is carried along as the instruction moves down the pipeline. Once an exception indication is set in the exception status vector, any control signal that may cause a data value to be written is turned off (this includes both register writes and memory writes). Because a store can cause an exception during MEM, the hardware must be prepared to prevent the store from completing if it raises an exception. When an instruction enters the WB stage, the exception status vector is checked. If there are any exceptions posted, they are handled in the order in which they would occur in time on an unpipelined processor. Thus, The hardware always deals with the exception from the earliest instruction and if it is a terminating exception, flushes the subsequent instructions. This is how precise exceptions are maintained.
However, in complex pipelines where multiple instructions are issued per cycle, or those that lead to Out-of-order completion because of long latency instructions, maintaining precise exceptions is difficult. In such cases, the pipeline can just be stopped and the status including the cause of the exception is saved. Once the control is transferred to the handler, the handler will determine which instruction(s) had exceptions and whether each instruction is to be completed or flushed. This may require manual completion. This simplifies the hardware, but the handler software becomes more complex.
Apart from the complications caused by exceptions, there are also issues that the ISA can bring in. In the case of the MIPS architecture, all instructions do a write to the register file (except store) and that happens in the last stage only. But is some ISAs, things may be more complicated. For example, when there is support for autoincrement addressing mode, a register write happens in the middle of the instruction. Now, if the instruction is aborted because of an exception, it will leave the processor state altered. Although we know which instruction caused the exception, without additional hardware support the exception will be imprecise because the instruction will be half finished. Restarting the instruction stream after such an imprecise exception is difficult. A similar problem arises from instructions that update memory state during execution, such as the string copy operations on the VAX or IBM 360. If these instructions don’t run to completion and are interrupted in the middle, they leave the state of some of the memory locations altered. To make it possible to interrupt and restart these instructions, these instructions are defined to use the general-purpose registers as working registers. Thus, the state of the partially completed instruction is always in the registers, which are saved on an exception and restored after the exception, allowing the instruction to continue. In the VAX an additional bit of state records when an instruction has started updating the memory state, so that when the pipeline is restarted, the CPU knows whether to restart the instruction from the beginning or from the middle of the instruction. The IA-32 string instructions also use the registers as working storage, so that saving and restoring the registers saves and restores the state of such instructions.
Yet another problem arises because of condition codes. Many processors set the condition codes implicitly as part of the instruction. This approach has advantages, since condition codes decouple the evaluation of the condition from the actual branch.
However, implicitly set condition codes can cause difficulties in scheduling any pipeline delays between setting the condition code and the branch, since most instructions set the condition code and cannot be used in the delay slots between the condition evaluation and the branch. Additionally, in processors with condition codes, the processor must decide when the branch condition is fixed. This involves finding out when the condition code has been set for the last time before the branch. In most processors with implicitly set condition codes, this is done by delaying the branch condition evaluation until all previous instructions have had a chance to set the condition code. In effect, the condition code must be treated as an operand that requires hazard detection for RAW hazards with branches, just as MIPS must do on the registers.
Last of all, we shall look at how the MIPS pipeline can be extended to handle floating point operations. A typical floating point pipeline is shown in Figure 15.5. There are multiple execution units, like FP adder, FP multiply, etc. and they have different latencies. These functional units may or may not be pipelined. We normally define two terms with respect to floating point pipelines. The latency is the number of intervening cycles between an instruction that produces a result and an instruction that uses the result. The initiation or repeat interval is the number of cycles that must elapse between issuing two operations of a given type. The structure of the floating point pipeline requires the introduction of the additional pipeline registers (e.g., A1/A2, A2/A3, A3/A4) and the modification of the connections to those registers. The ID/EX register must be expanded to connect ID to EX, DIV, M1, and A1.
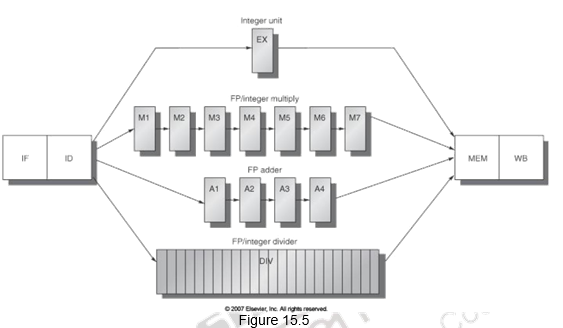
The long latency floating point instructions lead to a more complex pipeline. Since there is more number of instructions in the pipeline, there are frequent RAW hazards. Also, since these floating point instructions have varying latencies, multiple instructions might finish at the same time and there will be potentially multiple writes to the register file in a cycle. This might lead to structural hazards as well as WAW hazards. To handle the multiple writes to the register file, we need to increase the number of ports, or stall one of the writes during ID, or stall one of the writes during WB (the stall will propagate). WAW hazards will have to be detected during ID and the later instruction will have to be stalled. WAR hazards of course, are not possible since all reads happen earlier. The variable latency instructions and hence out-of-order completion will also lead to imprecise exceptions. You either have to buffer the results if they complete early or save more pipeline state so that you can return to exactly the same state that you left at.
To summarize we have discussed the different types of exceptions that might occur in a pipeline and how they can cause problems in the pipeline. We have discussed how the MIPS architecture handles them. Multiple exceptions and out of order exceptions complicate things even more. Certain features of the instruction sets may also complicate the pipeline. Additionally, floating point pipelines have additional complexities to handle.
Web Links / Supporting Materials
- Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th.Edition, Morgan Kaufmann, Elsevier, 2009.
- Computer Organization, Carl Hamacher, Zvonko Vranesic and Safwat Zaky, 5th.Edition, McGraw- Hill Higher Education, 2011.