
Bahar Asgari
Office: Iribe 5148
Email: bahar at umd dot edu
Research Group: CASL
I am an Assistant Professor in the Department of CS at the University of Maryland, College Park, with a joint appointment in UMIACS and affiliations with the Artificial Intelligence Interdisciplinary Institute at Maryland (AIM) and the Department of ECE.
Prior to joining UMD, I spent one year at Google. I received my Ph.D. from Georgia Tech in 2021, where I was selected as a Rising Star in EECS in 2019. I am honored that my research was recognized with a DoE Early Career Award in 2023, and that I received the Teaching Excellence Award for the 2023–2024 academic year. My research focuses on designing efficient, reconfigurable systems for AI, often by leveraging AI itself. A theme in my work has always been sparsity, both as a challenge and as an opportunity!


-
2026
-
Procyon: Promoting Fine-Grained Multi-Tenancy to Optimize Sparse Streaming Accelerators
Ubaid Bakhtiar, Jeremy Sha, Helya Hosseini, and Bahar Asgari
DAC, Long Beach, CA (2026)
Procyon is the eighth-brightest star in the night sky and the brightest star in the constellation Canis Minor. -
Situla: Studying the Interplay of Sparse Formats and CPU/GPU Libraries
Amirmahdi Namjoo, Sanjali Yadav, Helya Hosseini, and Bahar Asgari
ISPASS, Seoul, South Korea (2026)
Situla (/ˈsɪtjuːlə/) is a binary star in the equatorial constellation Aquarius. -
2025
-
Mustafar: Promoting Unstructured Sparsity for KV Cache Pruning in LLM Inference
Donghyeon Joo, Helya Hosseini, Ramyad Hadidi, and Bahar Asgari
NeurIPS, San Diego, CA (2025)
Mustafar is a volcanic planet in the Star Wars univers. -
Belenos: Bottleneck Evaluation to Link Biomechanics to Novel Computing Optimizations
Hana Chitsaz, Johnson Umeike, Amirmahdi Namjoo, Babak N. Safa, and Bahar Asgari
IISWC, Irvine, CA (2025)
Belenos is a single star in the equatorial constellation of Pisces. -
Boötes: Boosting the Efficiency of Sparse Accelerators Using Spectral Clustering
Sanjali Yadav, Amirmahdi Namjoo, and Bahar Asgari
MICRO, Seoul, South Korea (2025)
Boötes (/boʊˈoʊtiːz/) is a constellation in the northern sky. -
Chasoň: Supporting Cross-HBM Channel Data Migration to Enable Efficient Sparse Algebraic Acceleration
Ubaid Bakhtiar, Amirmahdi Namjoo, and Bahar Asgari
MICRO, Seoul, South Korea (2025)
Chasoň is a star in the constellation Lyra. -
Coruscant: Co-Designing GPU Kernel and Sparse Tensor Core to Advocate Unstructured Sparsity in Efficient LLM Inference
Donghyeon Joo, Helia Hosseini, Ramyad Hadidi and Bahar Asgari
MICRO, Seoul, South Korea (2025)
Coruscant is a fictional planet in the Star Wars universe. -
Misam: Machine Learning–Assisted Dataflow Selection in Accelerators for Sparse Matrix Multiplication
Sanjali Yadav, Amirmahdi Namjoo, and Bahar Asgari
MICRO, Seoul, South Korea (2025)
Misam (/ˈmaɪzəm/) is a triple star system in the northern constellation of Perseus. -
DynaFlow: An ML Framework for Dynamic Dataflow Selection in SpGEMM accelerators
Sanjali Yadav and Bahar Asgari
IEEE CAL (2025)
-
Segin: Synergistically Enabling Fine-Grained Multi-Tenant and Resource Optimized SpMV
Helia Hosseini, Ubaid Bakhtiar, Donghyeon Joo, and Bahar Asgari
IEEE CAL (2025)
Segin is a single star in the northern constellation of Cassiopeia. -
La Superba: Leveraging a Self-Comparison Method to Understand the Performance Benefits of Sparse Accelerator Optimizations
Nebil Ozer, Gregory Kollmer, Ramyad Hadidi, and Bahar Asgari
ISPASS, Ghent, Belgium (2025)
La Superba is a strikingly red giant star in the constellation Canes Venatici. -
Pipirima: Predicting Patterns in Sparsity to Accelerate Matrix Algebra
Ubaid Bakhtiar, Donghyeon Joo, and Bahar Asgari
DAC, San Francisco, CA (2025)
Pipirima is a star in the zodiac constellation of Scorpius. -
2024
-
Electra: Eliminating the Ineffectual Computations of Bitmap Compressed Matrices
Chaithanya Krishna Vadlamudi and Bahar Asgari
IEEE CAL (2024)
Electra is a blue-white giant star in the constellation of Taurus. -
Acamar: A Dynamically Reconfigurable Scientific Computing Accelerator for Robust Convergence and Minimal Resource Utilization
Ubaid Bakhtiar, Helia Hosseini, and Bahar Asgari
MICRO, Austin, Texas (2024)
Acemar (/ˈækəmɑːr/) is a binary system in the constellation of Eridanus. -
Misam: Using ML in Dataflow Selection of Sparse-Sparse Matrix Multiplication
Sanjali Yadav, Bahar Asgari
MLArchSys, Buenos Aires, Argentina (2024)
Misam (/ˈmaɪzəm/) is a triple star system in the northern constellation of Perseus. -
GUST: Graph Edge-Coloring Utilization for Accelerating Sparse Matrix Vector Multiplication
Armin Gerami, Bahar Asgari
ASPLOS, Rotterdam, Netherlands (2024)
-
2023
-
Memory-based computing for energy-efficient AI: Grand challenges
Foroozan Karimzadeh, Mohsen Imani, Bahar Asgari, Ningyuan Cao, Yingyen Lin, and Yan Fang
VLSI-SoC, Dubai, UAE (2023)
-
LCP: A Low-Communication Parallelization Method for Fast Neural Network Inference in Image Recognition
Ramyad Hadidi, Bahar Asgari, Jiashen Cao, Younmin Bae, Da Eun Shim, Hyojong Kim, Sung-Kyu Lim, Michael S. Ryoo, Hyesoon Kim
CSCE, Las Vegas, NV (2023)
-
Spica: Exploring FPGA Optimizations to Enable an Efficient SpMV Implementation for Computations at Edge
Dheeraj Ramchandani, Bahar Asgari, and Hyesoon Kim
IEEE EDGE, Chicago, IL (2023)
Spica is the brightest star in the zodiacal constellation of Virgo. -
Creating Robust Deep Neural Networks With Coded Distributed Computing for IoT
Ramyad Hadidi, Jiashen Cao, Bahar Asgari, and Hyesoon Kim
IEEE EDGE, Chicago, IL (2023)
-
Context-Aware Task Handling in Resource-Constrained Robots with Virtualization
Ramyad Hadidi, Nima Shoghi, Bahar Asgari, and Hyesoon Kim
IEEE EDGE, Chicago, IL (2023)
-
2022
-
MAIA: Matrix Inversion Acceleration Near Memory [paper]
Bahar Asgari, Dheeraj Ramchandani, Amaan Marfatia, and Hyesoon Kim
FPL, Belfast, United Kingdom (2022)
Maia is a star in the constellation of Taurus. -
2021
-
COPERNICUS: Characterizing the Performance Implications of Compression Formats Used in Sparse Workloads
Best Paper Nominee!
Bahar Asgari, Ramyad Hadidi, Joshua Dierberger, Charlotte Steinichen, Amaan Marfatia, Hyesoon Kim
IISWC 2021
Copernicus (/koʊˈpɜːrnɪkəs/) is a binary star system including five planets. -
FAFNIR: Accelerating Sparse Gathering by Using Efficient Near-Memory Intelligent Reduction [paper][slides][short video][long video]
Bahar Asgari, Ramyad Hadidi, Jiashen Cao, Da Eun Shim, Sung-Kyu Lim, Hyesoon Kim
HPCA 2021
Fafnir (/faːvnər/) is a star in the constellation of Draco. -
Quantifying the Design-Space Tradeoffs in Autonomous Drones
Ramyad Hadidi, Bahar Asgari, Sam Jijina, Adriana Amyette, Nima Shoghi, Hyesoon Kim [paper]
ASPLOS 2021
-
Context-Aware Task Handling in Resource-Constrained Robots with Virtualized Execution
Ramyad Hadidi, Bahar Asgari, Nima Shoghi, Hyesoon Kim
DAC 2021
-
2020
-
ALRESCHA: A Light-Weight Reconfigurable Sparse-Computation Accelerator [paper] [slides]
Bahar Asgari, Ramyad Hadidi, Tushar Krishna, Hyesoon Kim, Sudhakar Yalamanchili
HPCA, San Diego, CA (2020)
Alrescha (/ælˈriːʃə/) is a binary star system in the equatorial constellation of Pisces. -
PISCES: Power-Aware Implementation of SLAM by Customizing Efficient Sparse Algebra [paper][slides][video]
Bahar Asgari, Ramyad Hadidi, Nima Shoghi, Hyesoon Kim
DAC, San Francisco, California (2020)
Pisces (/ˈpaɪsiːz/) is a constellation including eighteen main stars. -
MEISSA: Multiplying Matrices Efficiently in a Scalable Systolic Architecture [paper][video]
Bahar Asgari, Ramyad Hadidi, Hyesoon Kim
ICCD, Hartford, Massachusetts (2020)
Meissa (/ˈmaɪsə/) is a multiple star in the constellation of Orion. -
ASCELLA: Accelerating Sparse Problems by Enabling Stream Accesses to Memory [paper] [slides][video]
Bahar Asgari, Ramyad Hadidi, Hyesoon Kim
DATE, Grenoble, France (2020)
Ascella (/əˈsɛlə/) is a triple star system and the third-brightest star in the constellation of Sagittarius -
MAHASIM: Machine-Learning Hardware Acceleration Using a Software-Defined Intelligent Memory System
Bahar Asgari, Saibal Mukhopadhyay, and Sudhakar Yalamanchili
Springer Journal of Signal Processing Systems, Special Issue on Embedded Machine Learning (2020)
Mahasim is a binary star in the constellation of Auriga -
Proposing a Fast and Scalable Systolic Array for Matrix Multiplication [slides][video]
Bahar Asgari, Ramyad Hadidi, Hyesoon Kim
FCCM, Fayetteville, Arkansas (2020)
-
2019
-
Characterizing the Deployment of Deep Neural Networks on Commercial Edge Devices [paper]
Best Paper Nominee!
Ramyad Hadidi, Jiashen Cao, Yilun Xie, Bahar Asgari, Tushar Krishna, Hyesoon Kim
IISWC, Orlando, Florida (2019)
-
ERIDANUS: Efficiently Running Inference of DNNs Using Systolic Arrays [paper]
Bahar Asgari, Ramyad Hadidi, Hyesoon Kim, Sudhakar Yalamanchili
IEEE Micro, Special Issue on Machine Learning Acceleration (2019)
Eridanus (/ɪˈrɪdənəs/) is a constellation in the southern hemisphere -
LODESTAR: Creating Locally-Dense CNNs for Efficient Inference on Systolic Arrays
Bahar Asgari, Ramyad Hadidi, Hyesoon Kim, Sudhakar Yalamanchili
DAC, Las Vegas, Nevada (2019)
Lodestar (/ˈlōdˌstär/> is the brightest star in the constellation of Ursa Minor -
SuDoku: Tolerating High-Rate of Transient Failures for Enabling Scalable STTRAM [paper]
Prashant Nair, Bahar Asgari, Moinuddin Qureshi
DSN, Portland, Oregon (2019)
-
Vortex RISC-V GPGPU system: Extending the ISA, Synthesizing the Microarchitecture, and Modeling the Software Stack [paper]
Fares Elsabbagh, Bahar Asgari, Hyesoon Kim and Sudhakar Yalamanchili
CARRV, Phoenix, AZ (2019)
-
CAPELLA: Customizing Perception for Edge Devices by Efficiently Allocating FPGAs to DNNs [paper]
Younmin Bae, Ramyad Hadidi, Bahar Asgari, Jiashen Cao, Hyesoon Kim
FPL, Barcelona, Spain (2019)
Capella (/kəˈpɛlə/) is the brightest star in the constellation of Auriga -
2018
-
Performance Implications of NoCs on 3D-Stacked Memories: Insights from the Hybrid Memory Cube [paper]
Ramyad Hadidi, Bahar Asgari, Jeffrey Young, Burhan Ahmad Mudassar, Kartikay Garg, Tushar Krishna, Hyesoon Kim
ISPASS, Belfast, Northern Ireland, United Kingdom (2018)
-
2017
-
Demystifying the Characteristics of 3D-Stacked Memories: A Case Study for Hybrid Memory Cube [paper]
Ramyad Hadidi, Bahar Asgari, Burhan Ahmad Mudassar, Saibal Mukhopadhyay, Sudhakar Yalamanchili, and Hyesoon Kim
IISWC, Seattle, Washington (2017)
-
2016
-
A Micro-Architectural Approach to Efficient Employment of STTRAM Cells in Microprocessors Register File
Bahar Asgari, Mahdi Fazeli, Ahmad Patooghy, and Seyed Vahid Azhari
IET Computers and Digital Techniques (2016)
-
Single Event Multiple Upset-Tolerant SRAM Cell Designs for Nano-scale CMOS Technology
Ramin Rajaei, Bahar Asgari, Mahmoud Tabandeh, Mahdi Fazeli
Turkish Journal of Electrical Engineering & Computer Sciences (2016)
-
2015
-
Design of Robust SRAM Cells Against Single-Event Multiple Effects for Nanometer Technologies
Ramin Rajaei, Bahar Asgari, Mahmoud Tabandeh, and Mahdi Fazeli
IEEE Transactions on Device and Materials Reliability (2015)
-

Together We Are Visible
Size: 36x36”
Material: Oil on canvas.
The Together We Are Visible shows four women and men dancing together in a field of sweet irises. The dancers reflect each other and share their positive feelings to get stronger and visible..

Pretend
Size: 36x36”
Material: Oil on canvas.

Union Harmony
Size: 36x36”
Material: Oil on canvas.
The Union Harmony shows the beauty of world, made up of elements such as a goldfish, a symbol of life, eyes, the gateways into the soul, lotus, the symbol of purity of the body and mind. All of them are connected through music, a shared language of human regardless their races.

Inseperable
Size: 24x36”
Material: Acrylic on canvas.
This painting is another view of the “Naples” drawing.
Time Vertigo
Size: 16x20”
Material: Acrylic on gesso board.
Time Vertigo visualizes space-time simultaneously by mixing colors and geometric shapes. This painting is a deep envision of the “Gravity” drawing. Simplifying the minor details of a scene, happing in a known time and location (i.e., Paris), and bringing the other scenes happing simultaneously to the same location is the key insight of the painting. The six characters in the painting are basically representative of the two main dancers, in three captures of time, past, present, and future, but all happening concurrently.
Some of my Mixed Media Works

The Third Eye
Size: 8x10”
Material: Pine cone.

Mirrors
Frame Size: 18x24”
Opening Size: 12x18”
Material: Mix.

Snowflake
Frame Size: 19x19”
Opening Size: 11x11”
Material: 140lb paper.
Exhibitions
The art exhibitions at Kai Lin galley, Atlanta, GA, Dec. 11, 2018:
Read more about this exhibition in "Like Picasso and Einstein: Lines, Forms and Dimensions" book, by Francesco Fedele and Emily Vickers:
Besides doing research in the field of computer architecture, I do drawing and painting. Mainly, I am interested in abstract painting. I integrate geometrical shapes with both sharp and soft edges, to create objects, which are distinguishable by their borders.
Some of my Abstract Paintings
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Teaching at UMD
-
Fall 2025 | Fall 2024 | Fall 2023 | Spring 2023
- CMSC818J - Domain-Specific Architectures
-
Spring 2026 | Spring 2025 | Spring 2024 | Fall 2022
- CMSC 411 - Computer Systems Architecture
Research
-
My Research Group at UMD
- Computer Architecture and Systems Lab (CASL)
Grants
- Department of Energy Early (DoE) Career Research Program: Developing Techniques to Enable Intelligent Dynamic Reconfigurable Computing for Sparse Scientific Problems
- NSF Principles and Practice of Scalable Systems (PPoSS): Research into the Use and iNtegration of Data Movement Accelerators (RUN-DMX)
Overview of My Research
Accelerating Sparse Problems
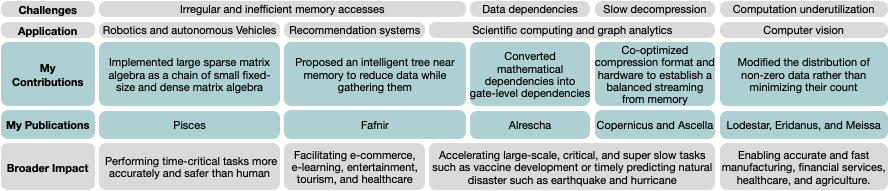
My research interests have revolved around efficiently accelerating the execution of sparse problems – computer programs in which data lacks spatial locality in memory. Sparse problems are the main component in several crucial domains such as robotics, recommendation systems, machine learning and computer vision, graph analytics, and scientific computing that remarkably impact human life. For instance, modeling/simulating a vaccine or predicting an earthquake are examples of sparse scientific computing that can save lives if done accurately and in a timely manner. Several supercomputers from Google Could, Amazon Web Service, Microsoft Azure, and IBM that are now running on over 136 thousand nodes containing five million processor cores and more than 50 thousand GPUs [1] for vaccine development is compelling evidence of the importance of sparse scientific computations. However, modern high-performance computers equipped with CPUs and/or GPUs are poorly suited to these sparse problems, utilizing a tiny fraction of their peak performance (e.g., 0.5% - 3% [2]). Such conventional architectures are mainly optimized to handle complex computation rather than the complex memory accesses that are essential for sparse problems. The contradiction between the abilities of the hardware and the nature of the problem causes sparse problems to waste extra hardware budget (high power and dollar cost) for higher performance. The goal of our research is to propose effective solutions that utilize the maximum potential of a given hardware budget to accelerate sparse problems. To be impactful in achieving the goal, our research suggests that software and hardware must be co-optimized. To date, several software- and hardware-level optimizations have been proposed to accelerate sparse problems; however, since they optimize either the software or the hardware in isolation, they have not fully resolved the challenges of sparse problems. Table above summarizes the common challenges of sparse problems, examples of sparse applications that suffer from these challenges, as well as my contributions and publications to resolve these challenges along with the broader impact that my research would have.
Intelligent Dynamically Reconfigurable Computing
My research also focuses on developing a novel dynamically reconfigurable computation platform that provides maximum performance for distinct applications with diverse requirements. For several years, general-purpose processors were optimized for the common case and were still able to provide reasonable performance for a wide range of applications. Today, diverse applications with distinct requirements are quickly being developed that cannot reach their maximum performance on a single hardware platform. Therefore, today, we see huge efforts to produce specialized hardware such as those I proposed for sparse problems (see the table above). As applications become more diverse and evolve quickly, designing specialized hardware will no longer be a practical solution for two reasons: (i) The process for such designs is costly, requires expertise across several domains, and is slow and therefore cannot keep up with the fast pace of algorithm development; and (ii) A system of several fixed specialized hardware platforms is not a scalable solution. CASL, my research group at UMD introduces and develops a novel approach for dynamically reconfigurable computation to be substituted with the current general-purpose processors and specialized hardware. Our new computation approach envisions a key characteristic: Hardware and software are treated as a single unified component. To simultaneously execute distinct programs, the hardware is reconfigured. Thus, each program reaches its optimized performance without sacrificing its performance for the common case.
Service
-
Program Committee
Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2026
IEEE Micro Top Picks 2024
International Symposium on Computer Architecture (ISCA) 2022, 2023, 2024, 2025
International Symposium on Microarchitecture (MICRO) 2024, 2025
High-Performance Computer Architecture (HPCA) 2023, 2024, 2025, 2026
Design Automation Conference (DAC) 2023, 2024
SuperComputing (SC) 2024, 2025
International Symposium on Performance Analysis of Systems and Software (ISPASS) 2023, 2024, 2025
Young Architect Workshop (YArch) 2023, 2024, 2025
International Conference on Computer Design (ICCD) 2023
IEEE International Symposium on Workload Characterization (IISWC) 2021, 2024
International Symposium on Memory Management (ISMM) 2025
IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED) 2025
-
Associate Editor
IEEE Micro
-
Organizing Committee
ML for Computer Architecture and Systems Workshop co-located with ISCA (MLArchSys 2024)
Architecture and System Support for Transformer Models Workshop co-located with ISCA (ASSYST 2023)
-
External Review Committee
Architectural Support for Programming Languages and Operating Systems (ASPLOS-2021)
-
Student Travel Chair
IEEE International Symposium on Workload Characterization (IISWC-2024)
-
Submission co-chair
51th International Symposium on Microarchitecture (MICRO-2018)
-
Reviewer
IEEE Computer Architecture Letters (CAL)
ACM Transactions on Architecture and Code Optimization (TACO)
IEEE Transactions on Very Large Scale Integration Systems (TVLSI)
IEEE Journal of Solid State Circuits (JSSC)
IEEE Transactions on Reliability
IEEE Transactions on Aerospace and Electronic Systems
IET Electronics Letters
IET Computers and Digital Techniques
Springer Journal of Signal Processing Systems
-
Judge
President’s Undergraduate Research Awards (PURA)
Undergraduate Research Opportunities Program (UROP)
Honeywell STEM challenge
-
Discussion chair
PeRSonAl tutorial at ISCA 2020
Invited Talks and Panels
-
SIAM Parallel Processing (PP24) minisymposium: “Smart Networks in HPC: For Fun or Profit (or Both)?”
- Dynamic Data Reduction in Motion: A Path to Efficient Sparse AI and Beyond
-
ICCD 2023 Panel
- Technologies, Systems, and Techniques to support Novel Computing Paradigms
-
VLSI-SoC 2023 workshop: Dynamic Data Reduction in Motion: A Path to Efficient Sparse AI and Beyond
- Optimizing Energy Efficiency in Sparse AI: A Near-Data Processing Approach for Recommendation Systems
-
AI-assisted Design for Architecture (AIDArc) co-located with ISCA 21