30 Cache Coherence II
Dr A. P. Shanthi
The objectives of this module are to discuss about the performance of symmetric shared memory multiprocessors in terms of true sharing and false sharing misses and elaborate on the Directory based cache coherency protocol.
In the previous module, we discussed the cache coherence problem and pointed out that there are basically two types of cache coherence protocols. As a recap, the two types are given below:
1. Directory based: The sharing status of a block of physical memory is kept in just one location, called the directory. The directory can also be distributed to improve scalability. Communication is established using point-to-point requests through the interconnection network.
2. Snoop based: Every cache that has a copy of the data from a block of physical memory also has a copy of the sharing status of the block, but no centralized state is kept. The caches are all accessible via some broadcast medium (a bus or switch), and all cache controllers monitor or snoop on the medium to determine whether or not they have a copy of a block that is requested on a bus or switch access. Requires broadcast, since caching information is at processors Useful for small scale machines (most of the market)
The previous module discussed in detail about the snoop based protocol. We will focus on the performance of symmetric shared memory multiprocessors and then elaborate on the directory based approach in this module.
Performance of symmetric shared memory multiprocessors: In a multiprocessor system, several factors affect the performance. We have already looked at the three Cs that contribute to the misses in a uni-processor system – capacity, conflict and compulsory. In addition to these, in a multiprocessor system, we have a fourth miss called the coherence misses. These are the misses that are caused due to inter-processor communication, in order to maintain coherence. We will elaborate on them now.
The coherence misses can be broken into two separate sources. The first source is true sharing misses that arise from the communication of data through the cache coherence mechanism. In an invalidation based protocol, the first write by a processor to a shared cache block causes an invalidation to establish ownership of that block. Additionally, when another processor attempts to read a modified word in that cache block, a miss occurs and the resultant block is transferred. Both these misses are classified as true sharing misses since they directly arise from the sharing of data among processors. The second effect, called false sharing, arises from the use of an invalidation based coherence algorithm with a single valid bit per cache block. False sharing occurs when a block is invalidated (and a subsequent reference causes a miss) because some word in the block, other than the one being read, is written into. If the word written into is actually used by the processor that received the invalidate, then the reference was a true sharing reference and would have caused a miss independent of the block size. If, however, the word being written and the word read are different and the invalidation does not cause a new value to be communicated, but only causes an extra cache miss, then it is a false sharing miss. In a false sharing miss, the block is shared, but no word in the cache is actually shared, and the miss would not occur if the block size were a single word. The following example in Figure 34.1 makes the sharing patterns clear. Let us assume that both X1 and X2 are in the same cache block and processors P1 and P2 have read X1 and X2 before. We shall see what happens for the sequence of operations shown below and classify them each of them as a true sharing miss or a false sharing miss.
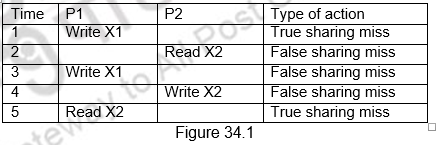
In the first instance, Processor P1 modifies X1. This event is a true sharing miss, since X1 was read by P2 and needs to be invalidated from P2. In the second instance, P2 reads X2, which was earlier invalidated by P1. This event is a false sharing miss, since X2 was invalidated by the write of X1 in P1, but that value of X1 is not used in P2. In the third instance, this event is again a false sharing miss, since the block containing X1 is marked shared due to the read in P2, but P2 did not read X1. The cache block containing X1 will be in the shared state after the read by P2 and a write miss is required to obtain exclusive access to the block. In some protocols this will be handled as an upgrade request, which generates a bus invalidate, but does not transfer the cache block. The fourth event is a false sharing miss for the same reason as step 3. The last event is a true sharing miss, since the value being read was written by P2.
Thus we see that coherence misses have a significant role to play in multiprocessor systems and the effect is more pronounced in the case of tightly coupled systems where a lot of data has be communicated between the processors.
Distributed Shared Memory and the Directory Based Coherence Protocol: We have already discussed the drawbacks of the snoopy protocol. As the number of processors increases, the memory and the communication bandwidths become too demanding and the system is not scalable beyond a certain point. This problem can be overcome by distributing the memory to the various processors. This separates the local memory traffic and the remote memory traffic and the memory demands are greatly reduced. However, in such a case, we also have to eliminate the need for the coherence protocol to broadcast on the bus for every cache miss.
As a result, we have an alternative to the snoopy protocol in the directory based protocol. As the name directory suggests, it is a directory which keeps information about the status of all the blocks in all the caches. Unlike a snoopy protocol where the information was distributed, here the information is available only in the directory and everybody accesses it to obtain details of any block.
To prevent the directory from becoming the bottleneck, the directory is distributed along with the memory, so that different directory accesses can go to different directories, just as different memory requests go to different memories. A distributed directory retains the characteristic that the sharing status of a block is always in a single known location. This property is what allows the coherence protocol to avoid broadcast. Figure 34.2 shows how a distributed-memory multiprocessor looks with the directories added to each node.
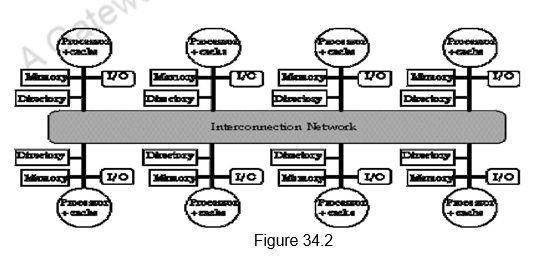
The directory has an entry for each memory block. The amount of information is proportional to the product of the number of memory blocks and the number of processors. We need to track which processors have copies of the block and the status of those blocks in every processor. This is needed for invalidation during a write. The simplest way to do this is to keep a bit vector for each memory block. When the block is shared, each bit of the vector indicates whether the corresponding processor has a copy of that block. We can also use the bit vector to keep track of the owner of the block when the block is in the exclusive state. For efficiency reasons, we also track the state of each cache block at the individual caches.
This overhead is not a problem for multiprocessors with less than about 200 processors because the directory overhead with a reasonable block size will be tolerable. For larger multiprocessors, we need methods to allow the directory structure to be efficiently scaled. The methods that have been used either try to keep information for fewer blocks (e.g., only those in caches rather than all memory blocks) or try to keep fewer bits per entry by using individual bits to stand for a small collection of processors.
Directory Based Cache Coherence Protocol: Just as with a snooping protocol, there are two primary operations that a directory protocol must implement: handling a read miss and handling a write to a shared, clean cache block. (Handling a write miss to a block that is currently shared is a simple combination of these two.) To implement these operations, a directory must track the state of each cache block. In a simple protocol, these states could be the following:
1. Shared – One or more processors have the block cached, and the value in memory is up to date (as well as in all the caches).
2. Uncached – No processor has a copy of the cache block.
3. Modified – Exactly one processor has a copy of the cache block, and it has written the block, so the memory copy is out of date. The processor is called the owner of the block.
Though the states and transitions are the same as that of the snoopy protocol, the actions taken for a transaction are different. Unlike a broadcast that was done in the snoopy protocol, here communication has to be sent from the requesting node to the directory or from the directory to the other nodes. We, therefore, define different types of nodes, depending on their role. They are:
- The local node is the node where a request originates
- The home node is the node where the memory location and the directory entry of an address reside. The physical address space is statically distributed, so the node that contains the memory and directory for a given physical address is known. For example, the high-order bits may provide the node number, while the low-order bits provide the offset within the memory on that node. The local node may also be the home node. The directory must be accessed when the home node is the local node, since copies may exist in yet a third node, called a remote node.
- A remote node is the node that has a copy of a cache block, whether exclusive (in which case it is the only copy) or shared. A remote node may be the same as either the local node or the home node. In such cases, the basic protocol does not change, but inter-processor messages may be replaced with intra-processor messages.
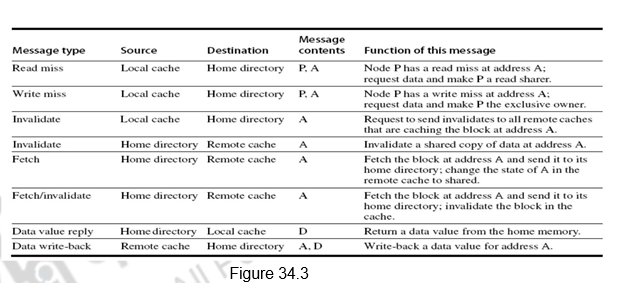
Figure 34.3 shows the messages sent between the processors and the directories for handling misses and also maintaining coherence. The basic operations are the same as that of the snoopy protocol. The interpretation of the messages is given below.
1. The first one is a read miss which is sent from the local cache to the home directory. The format of the message is the processor name P, and the address A. The directory gets the read miss, requests data and includes the processor P in the list of shared nodes.
2. For a write miss, the request goes from the local cache to the home directory. The data is again sent and the processor is made the exclusive owner of the block.
3. The invalidate message is sent from the local cache to the home directory, when the local cache wants to do a write operation.
4. The home directory, in turn, sends invalidates to all remote caches that have cached this address.
5. When a request for a data comes from the local node, the home directory fetches the data from the remote cache and sends it to the local cache. It also includes the local cache in the list of sharers.
6. This happens in response to a write request. The data is fetched by the home directory from the remote cache and the remote cache’s copy is also invalidated.
7. Data value reply is the sending of the data from the home directory to the local cache requesting it.
8. Data write back is the remote cache writing back the data to the home directory. Data value write backs occur for two reasons: when a block is replaced in a cache and must be written back to its home memory, and also in reply to fetch or fetch/invalidate messages from the home. Writing back the data value whenever the block becomes shared simplifies the number of states in the protocol, since any dirty block must be exclusive and any shared block is always available in the home memory.
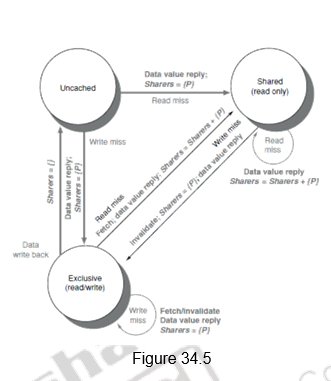
Example Directory Protocol: The operations to be done are the same and the sequence of actions is also the same. The only difference is that, instead of broadcasting the requests on the bus, the requests go to the home directory, which then takes appropriate action. The memory block can be available in an uncached state, i.e., not cached in any cache, shared state, where it is read in one or more caches, or an exclusive state, where it is modified and available in only one block. The details are provided below.
• For uncached block:
– Read miss
• Requesting node puts in a request to the home directory, the directory sends the requested data and is made the only sharing node, and the block is now shared.
– Write miss
• Requesting node puts in a request to the home directory, the requesting node is sent the requested data and becomes the sharing node, block is now exclusive.
• For shared block:
– Read miss
• Requesting node puts in a request to the home directory, the requesting node is sent the requested data from memory, and the node is added to the sharing set.
– Write miss
• Requesting node puts in a request to the home directory, the requesting node is sent the value, all nodes in the sharing set are sent invalidate messages, sharing set only contains requesting node, block is now exclusive.
• For exclusive block:
– Read miss
• Requesting node sends a request to the home directory, the owner is sent a data fetch message, block becomes shared, owner sends data to the directory, data written back to memory, sharers set contains old owner and also the requestor.
– Data write back
• Block becomes uncached, sharer set is empty.
– Write miss
• Message is sent to old owner to invalidate and send the value to the directory, requestor becomes new owner, block remains exclusive.
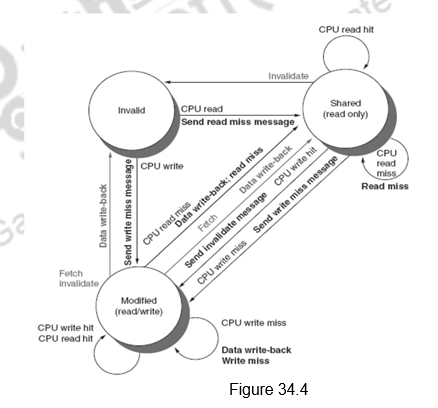
Figure 34.4 shows the state transition diagram for the individual cache blocks in a directory based protocol. Figure 34.5 shows the state transition diagram for the directory. The states and the transitions are the same as discussed earlier.
Just as in the case of snoopy protocols, here also we need to deal with non-atomic memory transactions. The finite buffer sizes will also lead to problems and will have to be handled. The directory protocols used in real multiprocessors contain additional optimizations. In particular, in this protocol when a read or write miss occurs for a block that is exclusive, the block is first sent to the directory at the home node. From there it is stored into the home memory and also sent to the original requesting node. Many of the protocols in use in commercial multiprocessors forward the data from the owner node to the requesting node directly (as well as performing the write back to the home). Such optimizations often add complexity by increasing the possibility of deadlock and by increasing the types of messages that must be handled.
To summarize, we have looked at the performance of symmetric shared memory processors. The true and false sharing misses have been identified. We have looked at the directory based cache coherence protocol that is used in distributed shared memory architectures in detail.
Web Links / Supporting Materials
- Computer Architecture – A Quantitative Approach , John L. Hennessy and David A.Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011.