19 Dynamic scheduling with Speculation
Dr A. P. Shanthi
The objective of this module is to go through the concept of hardware speculation and discuss how dynamic scheduling can be enhanced with speculation. We will look at how the data structures maintain the relevant information and how the hazards are handled.
We will first of all do a recap of dynamic scheduling. Dynamic Scheduling is a technique in which the hardware rearranges the instruction execution to reduce the stalls, while maintaining data flow and exception behavior. The advantages of dynamic scheduling are:
- It handles cases when dependences are unknown at compile time
- – (e.g., because they may involve a memory reference)
- It simplifies the compiler
- It allows code compiled for one pipeline to run efficiently on a different pipeline
- Hardware speculation, a technique with significant performance advantages, builds on dynamic scheduling
In a dynamically scheduled pipeline, all instructions pass through the issue stage in order; however they can be stalled or bypass each other in the second stage and thus enter execution out of order. Instructions will also finish out-of-order.
The dynamic scheduling technique that we discussed in the previous modules did not allow the processor to execute instructions beyond a branch. The dynamic branch prediction facilitates dynamic unrolling of loops. However, instructions after the branch can only be fetched and decoded, they cannot be executed. This is because of the fact that there is no provision to undo the effects of the instruction, if the branch prediction fails. But, that again limits the parallelism that can be exploited. So, if we need to uncover more parallelism, we need to execute instructions even before the branch is resolved. This concept of speculatively executing instructions before the branch is resolved, is called hardware speculation. During every cycle, the processor executes an instruction – even if it may be the wrong instruction. This is yet another way of overcoming control dependence – by speculating on the outcome of branches and executing the program as if our guesses were correct. Obviously, if our guesses go wrong, we should have the provision to undo. We are essentially building a data flow execution model, so as to execute instructions as soon as the operands are available. The details of this speculative execution are discussed in this module.
There are three components to dynamic scheduling with speculation. They are:
- Dynamic branch prediction to choose which instructions to execute
- Speculation to allow the execution of instructions before the control dependence is resolved
- o Support to undo if prediction is wrong
- Dynamic scheduling to deal with the scheduling of different combinations of basic blocks Processors like the PowerPC 603/604/G3/G4, MIPS R10000/R12000, Intel Pentium II/III/4, i3, i5, i7, Alpha 21264, AMD K5/K6/Athlon, etc. use dynamic scheduling with speculation.
Hardware Based Speculation: Earlier, with dynamic scheduling, instructions after the branch were executed only after the branch was resolved. So, during the write back stage, they wrote into registers or memory. Now, with speculation, we execute instructions along predicted execution paths, and the results can only be committed if the prediction was correct. Instruction commit allows an instruction to update the register file or memory only when the instruction is no longer speculative.
This indicates that we need an additional piece of hardware that will buffer the results of the instruction till they commit. This piece of hardware is called the Reorder Buffer, abbreviated as ROB. This helps to prevent any irrevocable action until an instruction commits, i.e. updating state or taking an execution. The reorder buffer holds the result of an instruction from the time it executes to the time it commits. It is also used to pass operands among speculated instructions.
The reorder buffer has the following fields. They are:
- Name or tag field for identification
- Instruction type: branch/store/register
- Destination field : register number
- Value field: output value
- Ready field: completed execution?
The ROB extends the architectural registers just like the reservation stations. With support for speculation, we now identify an instruction using its ROB entry and not the reservation station entry. The reservation station holds the operands from the time an instruction is issued to the time it executes. The ROB buffers the result from the time an instruction executes to the time it commits. However, we are looking at an in-order commit and an ROB entry is assigned when the instruction is issued itself. The mapping is done between the registers, the reservation stations and the ROB. This helps avoiding WAW and WAR hazards. To handle control hazards, the speculated entries in the ROB are cleared if there is a misprediction, Just note that exceptions are not recognized until the instruction causing exception is ready to commit. We shall discuss more about this later on.
The overall architecture of a dynamic scheduler with speculation is given in Figure 19.1. It is the same as the architecture that we discussed in the earlier modules, with the addition of an ROB.
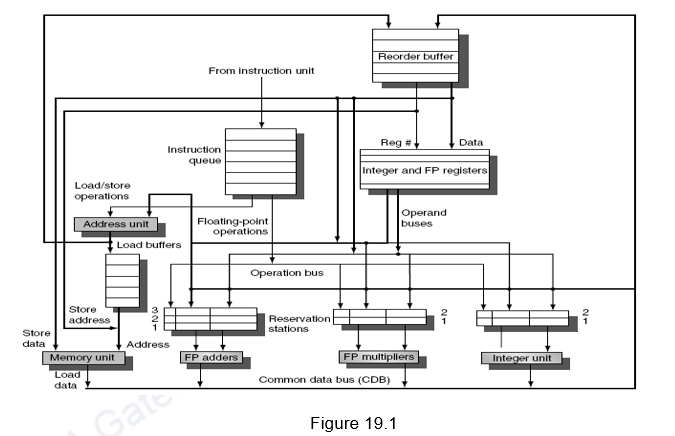
Instructions are taken from the prefetched instruction queue and decoded. The decode stage or the issue stage decodes the instructions and checks for structural hazards. The unavailability of a reservation station or an ROB entry leads to a structural hazard. A reservation station entry is allocated depending on the type of instruction, whereas an ROB entry is allocated sequentially (in-order issue and in-order commit). Since we are looking at an in-order issue, if an instruction stalls at the issue stage, the subsequent instructions cannot be issued. After that, the instructions will wait until there are no data hazards, and then read operands. This will enable us to do an in order issue, out of order execution and out of order completion. After the results are computed, the results are written only into the appropriate ROB entry and the reservation stations waiting for this data. Note that the CDB writes only into the ROB and the reservation stations, and not the register file. Another change is that we do not have separate store buffers. The ROB entries themselves act as store buffer entries. They buffer the store address and the data to be stored till the store instructions’ turn for commit arrives. The register result status indicates which register is to be written by which ROB tag. During the commit stage, data is either transferred from the ROB to registers or memory. If the committed instruction is a branch, the prediction is checked and if the prediction was correct, the branch is removed from the ROB queue and the subsequent instructions are committed in-order. Otherwise, the branch is removed and the ROB is flushed.
The entire book keeping is done in hardware. The hardware considers a set of instructions called the instruction window and tries to reschedule the execution of these instructions according to the availability of operands. The hardware maintains the status of each instruction and decides when each of the instructions will move from one stage to another. Register renaming is done in hardware with the help of the reservation stations and the ROB. This eliminates WAW and WAR hazards.
Apart from the three steps in the dynamic scheduler, an additional step of commit is introduced when there is support for speculation. The four steps in a dynamic scheduler with speculation are listed below:
- Issue
- Get next instruction from FIFO queue
- If available RS entry and ROB entry, issue the instruction
- If a RS or ROB entry is not available, it becomes a structural hazard and the instruction stalls
- If an earlier instruction is not issued, then subsequent instructions cannot be issued
- If operands are available read them and store them in the reservation station
- Operands can be read from the register file (already committed instructions) or from the ROB (executed but not yet committed)
- Operands dependent on an earlier instruction are identified by their corresponding ROB tag in the Q field and such instructions will have to stall till data becomes available
- Execute
- The CDB broadcasts data with an ROB tag and when an operand becomes available, store it in any reservation station waiting for it
- When all operands are ready, issue the instruction for execution
- Free the reservation station entry once the instruction moves into execution
- Loads and store are maintained in program order through the effective address
- Even with pending branches, instructions are speculatively executed
- Write result
- Write result on CDB into reservation stations and ROB
- Commit
- An instruction is committed when it reaches the head of the ROB and its result is present in the buffer
- If it is an ALU or Load instruction, update the register with the result and remove the instruction from the ROB
- Committing a store is similar except that memory is updated rather than a result register
- If a branch with incorrect prediction reaches the head of the ROB, it indicates that the speculation was wrong
- ROB is flushed and execution is restarted at the correct successor of the branch
- If the branch was correctly predicted, the branch is removed from ROB
- Once an instruction commits, its entry in the ROB is reclaimed.
- If the ROB fills, we simply stop issuing instructions until an entry is made free.
The dynamic scheduler with speculation maintains four data structures – the reservation station, ROB, a register result data structure that keeps track of the ROB entry that will modify a register and an instruction status data structure. The last one is more for understanding purposes.
Having looked at the basics of a dynamic scheduler with speculation, we shall now discuss how the scheduling happens for a sequence of instructions. Let us consider the sequence of instructions that we discussed earlier for dynamic scheduling. Assume the latencies for the Add, Mul and Div instructions to be 2, 6 and 12 respectively.
L.D F6,32(R2)
L.D F2,44(R3)
MUL.D F0,F2,F4
SUB.D F8,F6,F2
DIV.D F10,F0,F6
ADD.D F6,F8,F2
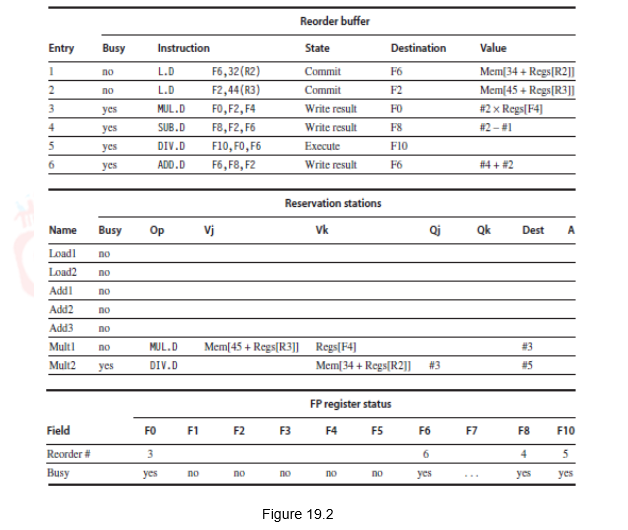
Figure 19.2 shows how the status tables will look like when the MUL.D is ready to go to commit. Observe that though the Sub and Add instructions have written the result, they have not yet committed. This is because the Mul instruction has not yet committed. The Dest field designates the ROB entry that is the destination for the result produced by a particular reservation station entry. The complete schedule is given in Table 19.1.
| Instruction | Issues at | Executes at | Writes result at | Commits at |
| L.D F6,32(R2)
|
1 | 2-3 | 4 | 5 |
| L.DF2,44(R3)
|
2 | 3-4 | 5 | 6 |
| MUL.D F0,F2,F4
|
3 | 6-11 | 12 | 13 |
| SUB.D F8,F6,F2
|
4 | 6-7 | 8 | 14 |
| DIV.D F10,F0,F6
|
5 | 13-24 | 25 | 26 |
| ADD.D F6,F8,F2
|
6 | 9-10 | 11 | 27 |
Table 19.1
Note that the instructions are issued in-order, executed out-of-order, completed out-of-order, but committed in-order.
One implication of speculative execution is that it maintains a precise exception model. For example, if the MUL.D instruction caused an exception, we wait until it reaches the head of the ROB and take the exception, flushing any other pending instructions from the ROB. Because instruction commit happens in order, this yields a precise exception. By contrast, in the example using Tomasulo’s algorithm, the SUB.D and ADD.D instructions could both complete before the MUL.D raised the exception. The result is that the registers F8 and F6 (destinations of the SUB.D and ADD.D instructions) could be overwritten, and the exception would be imprecise. Thus, the use of a ROB with in-order instruction commit provides precise exceptions, in addition to supporting speculative execution.
When we consider sequences with branches, just remember that the loops are dynamically unrolled by the dynamic branch predictor and the instructions after the branch are speculatively executed. However, they are committed in-order, after the branch is resolved.
Observe that there is an in-order issue, out-of-order execution, out-of-order completion and in-order commit. Due to the renaming process, multiple iterations use different physical destinations for the registers (dynamic loop unrolling). This is why the Tomasulo’s approach is able to overlap multiple iterations of the loop. The reservation stations permit instruction issue to advance past the integer control flow operations. They buffer the old values of registers, thus totally avoiding the WAR stall that would have happened otherwise. Thus, we can say that the Tomasulo’s approach with speculation builds the data flow execution graph on the fly. However, the performance improvement depends on the accuracy of the branch prediction. If the branch prediction goes wrong, the instructions fetched, issued and executed from the wrong path will have to be discarded, leading to penalty.
In practice, processors that speculate try to recover as early as possible after a branch is mispredicted. This recovery can be done by clearing the ROB for all entries that appear after the mispredicted branch, allowing those that are before the branch in the ROB to continue, and restarting the fetch at the correct branch successor. In speculative processors, performance is more sensitive to the branch prediction, since the impact of a misprediction will be higher. Thus, all the aspects of handling branches—prediction accuracy, latency of misprediction detection, and misprediction recovery time—increase in importance.
Like the Tomasulo’s algorithm, we must avoid hazards through memory. WAW and WAR hazards through memory are eliminated with speculation because the actual updating of memory occurs in order, when a store is at the head of the ROB, and hence, no earlier loads or stores can still be pending. RAW hazards through memory are maintained by two restrictions:
- not allowing a load to initiate the second step of its execution if any active ROB entry occupied by a store has a Destination field that matches the value of the A field of the load, and
- maintaining the program order for the computation of an effective address of a load with respect to all earlier stores.
Together, these two restrictions ensure that any load that accesses a memory location written to by an earlier store cannot perform the memory access until the store has written the data. Some speculative processors will actually bypass the value from the store to the load directly, when such a RAW hazard occurs.
To summarize, we have looked at the concept of hardware speculation that allows instructions beyond the branch to be executed, before the branch is resolved. Based on the branch prediction, branches are dynamically unrolled. Instructions beyond the branch are fetched, issued and executed, but committed in-order. The book keeping done and the various steps carried out have been elaborated.
| Web Links / Supporting Materials |
| Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th Edition, Morgan Kaufmann, Elsevier, 2009. |
| Computer Architecture – A Quantitative Approach , John L. Hennessy and David A. Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011. |