28 Introduction to Multiprocessors
Dr A. P. Shanthi
The objectives of this module are to discuss the different types of parallel processors and the main issues to be considered while designing parallel processors.
We know that there are different types of parallelism that applications exhibit and the architectures try to exploit them. In our earlier modules, we have looked at different techniques to exploit ILP. We have also looked at how thread level parallelism can be exploited using fine grained and coarse grained multithreading. Both ILP and TLP can be combined with SMT. However, when SMT is employed, the single thread performance is likely to go down as the caches, branch predictors, registers, etc. are shared. This effect can be mitigated by trying to prioritize or prefer one or two threads. There are several design challenges associated with SMT, as shown below:
• How many threads?
– Many to find enough parallelism
– However, mixing many threads will compromise execution of individual threads
• Processor front-end (instruction fetch)
– Fetch as far as possible in a single thread (to maximize thread performance)
– However, this limits the number of instructions available for scheduling from other threads
• Larger register files needed
– In order to store multiple contexts
• Minimize clock cycle time
– Not affecting the clock cycle, particularly in critical steps such as instruction issue, where more candidate instructions need to be considered, and in Instruction completion, where choosing what instructions to commit may be challenging
• Cache conflicts
– Ensuring that the cache and TLB conflicts generated by the simultaneous execution of multiple threads do not cause significant performance degradation
• At the end of the day, it is only a single physical processor
– Though SMT enables better threading (e.g. up to 30%), OS and applications perceive each simultaneous thread as a separate “virtual processor”, the chip has only a single copy of each resource
• Difficult to make single-core clock frequencies even higher
• Deeply pipelined circuits:
– Heat problems
– Clock problems
– Efficiency (Stall) problems
• Doubling issue rates above today’s 3-6 instructions per clock, say to 6 to 12 instructions, is extremely difficult
– issue 3 or 4 data memory accesses per cycle,
– rename and access more than 20 registers per cycle, and
– fetch 12 to 24 instructions per cycle
It has been shown that with eight threads in a processor with many resources, SMT yields throughput improvements of roughly 2-4. Alpha 21464, IBM Power5 and Intel Pentium 4 are examples of SMT.
The challenges associated with SMT and a slowdown in uniprocessor performance arising from diminishing returns in exploiting ILP, combined with growing concern over power, is leading to a new era in computer architecture – an era where multiprocessors play a major role. This is also reinforced by other factors like:
• Increasing interest in servers and server performance
• Applications becoming more and more data-intensive
• The insight that increasing performance on the desktop is less important for many applications
• An improved understanding of how to use multiprocessors effectively
• The advantages of leveraging a design investment by replication rather than unique design—all multiprocessor designs provide such leverage
Thus, Multi-core architectures have come to dominate the market. Here, there are several cores, where each is smaller and not as powerful (but also easier to design and manufacture). They are however, great with thread-level parallelism. On the other hand, SMT processors can have one large and fast superscalar core, which has great performance on a single thread and mostly still only exploits instruction-level parallelism.
The traditional definition of a parallel computer goes like this: “A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast” (Almasi and Gottlieb, Highly Parallel Computing ,1989). Whenever we talk of parallel computers, the popular questions to be answered are:
– How large a collection?
– How powerful are processing elements?
– How do they cooperate and communicate?
– How are data transmitted?
– What type of interconnection?
– What are the HW and SW primitives for the programmer?
– What is the programming model?
– How does it translate into performance?
We shall try to answer most of these questions in this module and some of the subsequent modules.
Taxonomy of computers: First of all, we shall look at how computer systems are classified based on the number of instruction streams and data streams by Michael Flynn. According to him, computers can be put into one of four categories:
1. Single instruction stream, single data stream (SISD) – This category is the uniprocessor.
2. Single instruction stream, multiple data streams (SIMD) – The same instruction is executed by multiple processors using different data streams. SIMD computers exploit data-level parallelism by applying the same operations to multiple items of data in parallel. Each processor has its own data memory (hence multiple data), but there is a single instruction memory and control processor, which fetches and dispatches instructions. For applications that display significant data-level parallelism, the SIMD approach can be very efficient. The multimedia extensions available in processor ISAs are a form of SIMD parallelism. Vector architectures, are the largest class of SIMD architectures. Examples of SIMD style of architectures include the Illiac-IV and CM-2. They have the following characteristics:
i. Simple programming model
ii. Low overhead
iii. Flexibility
iv. All custom integrated circuits
We shall discuss all the different ways of exploiting data-level parallelism in a later module.
3. Multiple instruction streams, single data stream (MISD) – No commercial multiprocessor of this type has been built to date.
4. Multiple instruction streams, multiple data streams (MIMD) – Each processor fetches its own instructions and operates on its own data. MIMD computers exploit thread-level parallelism, since multiple threads operate in parallel. In general, thread-level parallelism is more flexible than data -level parallelism and thus more generally applicable. Examples include Sun Enterprise 5000, Cray T3D and SGI Origin. They are
i. Flexible
ii. Use off-the-shelf microprocessors and hence have the cost/performance advantage
iii. Most common parallel computing platform Multicore processors fall under this category.
We shall discuss the MIMD style of architectures in this module.
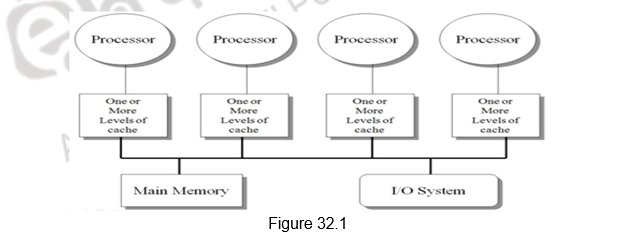
Classes of MIMD architectures: There are basically two types of MIMD architectures, depending on the number of processors involved, which in turn dictates a memory organization and interconnect strategy. We classify multiprocessors based on their memory organization as centralized shared-memory architectures and distributed shared memory architectures. The centralized shared memory architectures normally have a few processors sharing a single centralized memory through a bus based interconnect or a switch. With large caches, a single memory, possibly with multiple banks, can satisfy the memory demands of a small number of processors. However, scalability is limited as sharing a centralized memory becomes very cumbersome as the number of processors increases. Because there is a single main memory, it has a symmetric relationship to all processors and a uniform access time from any processor, and these multiprocessors are most often called symmetric (shared-memory) multiprocessors (SMPs), and this style of architecture is also called uniform memory access (UMA), arising from the fact that all processors have a uniform latency from memory, even if the memory is organized into multiple banks. Figure 32.1 shows the organization of such multiprocessors.
The second class consists of multiprocessors with physically distributed memory. Figure 32.2 shows what these multiprocessors look like. In order to handle the scalability problem, the memory must be distributed among the processors rather than centralized. Each processor has its own local memory and can also access the memory of other processors. The larger number of processors also raises the need for a high-bandwidth interconnect.
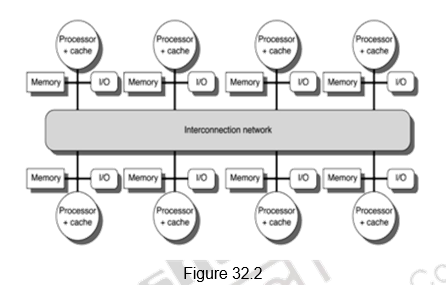
Distributing the memory among the nodes has two major benefits. First, it is a cost-effective way to scale the memory bandwidth if most of the accesses are to the local memory in the node. Second, it reduces the latency for accesses to the local memory. These two advantages make distributed memory attractive. The disadvantages for distributed memory architectures are that communicating data between processors becomes more complex, and that it requires more effort in the software to take advantage of the increased memory bandwidth afforded by the distributed memories. The comparison between the two styles of architecture is given below:
- Centralized shared memory architectures
- Uniform memory access time – UMA processors
- Symmetric processors – Symmetric Shared Memory multiprocessors (SMPs)
- Interconnection is traditionally through a bus – scalability problem
- Simpler software model
- Decentralized or distributed memory architectures
- Non-uniform memory access time – NUMA processors
- Get more memory bandwidth, lower memory latency
- Drawback: Longer communication latency
- Drawback: Software model more complex
Models for Communication: As we have seen, in order to handle the scalability problem, we need to distribute the memory among multiple processors. The use of distributed memory leads to two different paradigms for inter-processor communication, transferring data from one processor to another – shared memory model and message passing model. The comparison between the two models is given below.
1. Shared Memory with “Non Uniform Memory Access” time (NUMA)
- There is logically one address space and the communication happens through the shared address space, as in the case of a symmetric shared memory architecture. One processor writes the data in a shared location and the other processor reads it from the shared location.
2. Message passing “multicomputer” with separate address space per processor
• Each processor has its own address space. It is still NUMA style of architecture. In this case, we can invoke software with Remote Procedure Calls (RPC).
• This is normally done through libraries such as MPI (Message Passing Interface).
• Also called “Synchronous communication” since communication causes synchronization between 2 processes.
Advantages of Shared-memory communication model: Based on the above discussion, the advantages of both the communication models can be presented. The shared memory model has the following advantages:
1. This model has compatibility with the SMP hardware.
2. There is ease of programming when communication patterns are complex or vary dynamically during execution.
3. This model lends the ability to develop applications using the familiar SMP model, with attention only on performance critical accesses .
4. There is lower communication overhead and better use of bandwidth for small items, due to the implicit communication and memory mapping to implement protection in hardware, rather than through the I/O system.
5. The use of HW-controlled caching to reduce remote communication by caching of all data, both shared and private.
Advantages of Message-passing communication model: The message passing communication model has the following advantages:
1. The hardware can be simpler. (esp. vs. NUMA)
2. The communication is explicit, which means it is simpler to understand; in shared memory it can be hard to know when communicating and when not, and how costly it is.
3. The explicit communication focuses computation, sometimes leading to programs. attention on costly aspects of parallel improved structure in multiprocessor
4. Synchronization is naturally associated with sending messages, reducing the possibility for errors introduced by incorrect synchronization
5. Easier to use sender-initiated communication, which may have some advantages in performance
Data parallel model: Yet another programming model, whose architectural features we shall discuss in detail later is the data parallel model. Its salient features are listed below:
1. Here, operations can be performed in parallel on each element of a large regular data structure, such as an array.
2. There is one Control Processor that broadcasts to many Processing Elements.
3. There is support for a condition flag per PE so that it can be skipped for certain operations.
4. The data is distributed in each memory.
5. There are data parallel programming languages that lay out data to the processing elements.
6. This SIMD programming model led to the Single Program Multiple Data (SPMD) model, where all processors execute identical programs.
Programming Model Summary: Programming model is the conceptualization of the machine that the programmer uses in coding applications. It basically defines how parts cooperate and coordinate their activities. It also specifies communication and synchronization operations . The various programming models that we have discussed can be summarized as:
• Multiprogramming
– no communication or synchronization at program level
• Shared address space
– like bulletin board
• Message passing
– like letters or phone calls, explicit point to point
• Data parallel:
– more regimented, global actions on data
– implemented with shared address space or message passing
Performance metrics for communication mechanisms: Having looked at the different styles of multiprocessor architectures, we shall now focus on the performance metrics used to evaluate such systems. Performance of multi processor systems is evaluated based on the communication bandwidth, communication latency and techniques used for hiding the communication latency.
1. Communication Bandwidth
– We generally need high bandwidth in communication.
– This is limited by processor, memory and interconnection bandwidth.
2. Communication Latency
– This affects performance, since processor may have to wait for the data to arrive.
– It affects ease of programming, since requires more thought to overlap communication and computation.
– The overhead to communicate is a problem in many machines .
3. Communication Latency Hiding
– What are the mechanisms that will help hide latency?
– This increases programming system burden. Examples include overlapping the message send with computation, prefetching data, switching to other tasks, etc.
Therefore, whichever style of architecture gives high communication bandwidth, low communication latency and supports techniques for hiding communication latency are preferred.
Challenges of parallel processing: When we look at multiprocessor systems, we may run varied tasks ranging from independent tasks requiring no communication at all, to tasks that may require lots of communication among themselves . Therefore, there are two important hurdles that make parallel processing challenging. They are the amount of parallelism available in programs and the communication overhead. Both of these are explainable with Amdahl’s Law, The degree to which these hurdles are difficult or easy is determined both by the application and by the underlying architecture.
The first hurdle has to do with the limited parallelism generally available in programs Limitations in available parallelism make it difficult to achieve good speedups in any parallel processor. The importance of parallelism in programs is illustrated through the following example. Suppose we want to achieve an overall speedup of 80 with 100 processors. In such a scenario, we can calculate the fraction of the original computation that can be sequential. Applying this to Amdahl’s Law, and assuming that the program operates in only two modes – parallel with all processors fully used, which is the enhanced mode, or serial with only one processor in use, we find that only 0.25% of the program should be sequential. That is, to achieve a speedup of 80 with 100 processors, only 0.25% of original computation can be sequential. That shows us the importance of writing parallel programs to harness the power of the multiple processors. In practice, programs do not just operate in fully parallel or sequential mode, but often use less than the full complement of the processors when running in parallel mode.
The second challenge is the relatively high cost of communication among processors. If we consider a 32-processor multiprocessor operating at 1 GHz. and only 0.2% of the instructions involve a remote communication reference which takes 400ns / access, it can be shown even with the most optimistic calculations, that if the remote references are not there, the multiprocessor will be 2.6 times faster. Such is the effect of communication overhead and this has to be ha ndled appropriately.
One solution to reduce the communication overhead is to make use of caches and cache the data needed by every processor. Caches serve to Increase the bandwidth and reduce the latency of access. They are valuable for both private data and shared data. However, there are problems like cache consistency that we have to deal with. This will be elaborated in the subsequent modules.
To summarize, we have looked at the need for multiprocessor systems. The limitations of ILP and TLP as well as power and heat constraints have made us shift from complex uniprocessors to simpler multicores. There are different styles of parallel architectures. We have discussed the major categories along with their advantages and disadvantages. There are also different programming models available. Finally, we have discussed the main challenges associated with multiprocessor systems.
Web Links / Supporting Materials
- Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th Edition, Morgan Kaufmann, Elsevier, 2009.
- Computer Architecture – A Quantitative Approach , John L. Hennessy and David A.Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011.