38 Multiple Issue Processors I
Dr A. P. Shanthi
The objectives of this module are to discuss the need for multiple issue processors, look at the different types of multiple processors and discuss various implementation and design issues.
So far, we have looked at various hardware and software techniques to exploit ILP. The ideal CPI that we can expect in a pipelined implementation is only 1. If we want to further reduce CPI, we need to explore the option of issuing and completing multiple instructions every clock cycle. For example, if we issue and complete two instructions every clock cycle, ideally we should get a CPI of 0.5. Such processors are called multiple issue processors.
Consider the simple MIPS integer pipeline that we are familiar with. This gets extended with multiple functional units for the execution stage when we look at different types of fixed and floating point operations. We can also increase the depth of the pipeline, which may be required because of the increase in clock speeds. Now, in multiple issue processors, we increase the width of the pipeline. Several instructions are fetched and decoded in the front-end of the pipeline. Several instructions are issued to the functional units in the back-end. Suppose if m is the maximum number of instructions that can be issued in one cycle, we say that the processor is m-issue wide.
Types of Multiple Issue Processors: There are basically two variations in multiple issue processors – Superscalar processors and VLIW (Very Long Instruction Word) processors. There are two types of superscalar processors that issue varying numbers of instructions per clock. They are
- statically scheduled superscalars that use in-order execution
- dynamically scheduled superscalars that use out-of-order execution
VLIW processors, in contrast, issue a fixed number of instructions formatted either as one large instruction or as a fixed instruction packet with the parallelism among instructions explicitly indicated by the instruction. Hence, they are also known as EPIC–Explicitly Parallel Instruction Computers. Examples include the Intel/HP Itanium processor. A summary of the characteristics of the various types is provided in the table below.
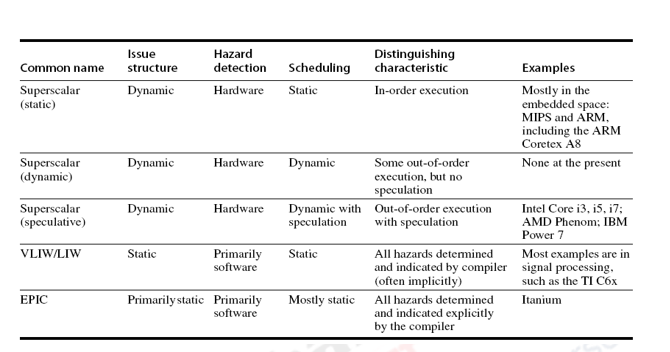
Superscalar processors decide on the fly how many instructions are to be issued. If instructions are issued to the back-end in program order, we have in-order processors. In-order processors are statically scheduled, i.e., the scheduling is done at compile-time. A statically scheduled superscalar must check for any dependences between instructions in the issue packet and any instruction already in the pipeline. They require significant compiler assistance to achieve good performance as the compiler does most of the work of finding and scheduling instructions for parallel execution. In contrast, a dynamically scheduled superscalar requires less compiler assistance, but significant hardware costs. If instructions can be issued to the back-end in any order, we have out-of-order (OOO) processors. OOO processors are dynamically scheduled by the hardware.
An alternative to superscalar approach is to rely on the compiler technology to minimize the potential stalls due to hazards. The instructions are formatted in a potential issue packet so that the hardware need not check explicitly for dependences. The compiler ensures that there are on dependences within the issue packet or indicates when a dependence occurs. This architectural approach was named VLIW. The compiler technology offers the potential advantage of having simpler hardware, while still exhibiting good performance through extensive compiler technology. We will look at details of each of these types of multiple issue processors. This module will focus on the superscalar processors and the next module will discuss the VLIW style of architectures.
Statically Scheduled Superscalar Processors: In such processors, we issue instructions in issue packets with the number of instructions ranging from 0 to 8. Suppose we consider a 4-issue superscalar, then up to four instructions will be taken from the fetch unit. The fetch unit may or may not be able to supply all the four instructions. During the issue stage, all hazards are checked in hardware (dynamic issue capability). The hazards among instructions in the issue packet as well as the ones between the instructions in the packet and the ones already in execution need be checked by the pipeline control logic. If one instruction in the packet cannot be issued, only the preceding instructions are issued. That is, we look at an in-order issue.
Hazard checks normally take a long time and if they are to be done in one clock cycle, then the issue logic decides the minimum clock cycle time. In order to avoid this, the issue stage is split into two and pipelined. The hazards among instructions in the same packet are checked in the 1st stage. The hazards among the instructions in the packet and the ones already in the pipeline are checked in the 2nd. stage.
Statically Scheduled Superscalar MIPS: Let us assume a statically scheduled superscalar MIPS and also assume that two instructions are issued per clock cycle. One of them is a floating point operation and the other is a Load/Store/Branch/ Integer operation. This is much simpler and less demanding than arbitrary dual issue.
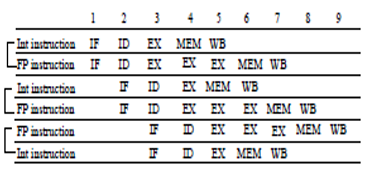
For this processor, upto two instructions will have to be fetched every clock cycle. The hazard checking process is relatively straightforward, since the restriction of one integer and one FP instruction eliminates most hazard possibilities within the issue packet. The only difficulties that arise are when the integer instruction is a floating-point load, store, or move. This possibility creates contention for the floating-point register ports and may also create a new RAW hazard when the second instruction of the pair depends on the first. Finally, the instructions chosen for execution are dispatched to their appropriate functional units. Figure 22.1 shows how the instructions look as they go into the pipeline in pairs. Here, we assume that the floating point instruction takes three clock cycles for execution.
The problems of this superscalar MIPS are the following:
- – Additional hardware in the pipeline
- This definitely requires more hardware than the single issue MIPS
- – Out-of-order completion will lead to imprecise interrupts
- A floating point instruction can finish execution after an integer instruction that is later in program order
- The floating point instruction exception could be detected after the integer instruction completed
- Several solutions like early detection of FP exceptions, the use of software mechanisms to restore a precise exception state before resuming execution, and delaying instruction completion until we know an exception is impossible
- – Hazard penalties may be longer
- The result of a load instruction cannot be used on the same clock cycle or on the next clock cycle, and hence, the next three instructions cannot use the load result without stalling. The branch delay for a taken branch becomes either two or three instructions, depending on whether the branch is the first or second instruction of a pair
Dynamically Scheduled Superscalar MIPS: As we have already discussed in the earlier modules with single issue, dynamic scheduling is one method for improving performance in a multiple issue processor also. When applied to a superscalar processor, dynamic scheduling not only improves performance when there are data dependences, it also allows the processor to potentially overcome the issue restrictions. That is, although the hardware may not be able to initiate execution of more than one integer and one FP operation in a clock cycle, dynamic scheduling can eliminate this restriction at instruction issue, at least until the hardware runs out of reservation stations.
Let us assume that we want to extend the Tomasulo’s algorithm to support dual issue. Instructions will have to be issued in-order to the reservation stations. Otherwise, it will lead to a violation of the program semantics. We can assume that any combination of instructions can be issued, but this will significantly complicate instruction issue. Alternatively, we can separate the data structures for the integer and floating-point registers. Then we can simultaneously issue a floating-point instruction and an integer instruction to their respective reservation stations, as long as the two issued instructions do not access the same register set. Two different approaches have been used to issue multiple instructions per clock in a dynamically scheduled processor. They are:
- Pipelining, so that two instructions can be processed in one clock cycle
- Increase the logic to handle two instructions, including any possible dependences between the instructions. Modern superscalar processors that issue four or more instructions per clock often include both approaches – they both pipeline and widen the issue logic.
Let us now see how a simple loop shown below executes on this dual issue processor.
Loop: LD R2, 0(R1) ;R2=array element
DADDIU R2,R2,#1 ;increment R2
SD R2, 0(R1) ;store result
DADDIU R1,R1,#8 ;increment pointer
BNE R2,R3,LOOP ;branch if not last element
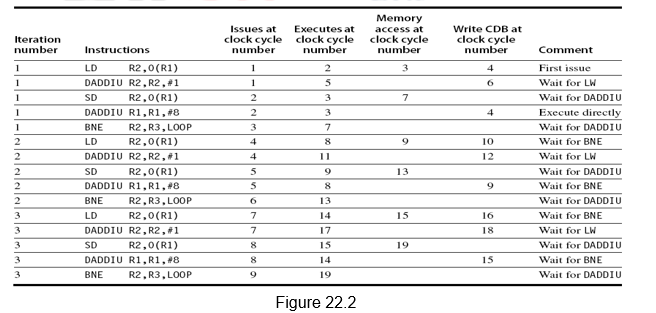
In the first clock cycle, both LD and DADDIU instructions of iteration 1 are issued. LD finishes in the fourth clock cycle and because of the dependency, DADDIU executes in 5 and writes in 6. During the second clock cycle, SD and the second DADDIU of iteration 1 are issued. SD calculates the effective address in 3, but does the memory write in 7. Branch is single-issued in clock cycle 3. The branch is resolved in 7. The LD and DADDIU of iteration 2 are issued in clock cycle 4. However, they execute only after the branch is resolved. So, LD finishes in 10, and so on. The entire schedule is given in Figure 22.2.
Dynamically Scheduled Superscalar MIPS with Speculation: The performance of the dynamically scheduled superscalar can be improved further with speculation. The concept of speculation has already been discussed with respect to single issue processors. The same is extended to multiple issue processors. Instructions beyond the branch are not only fetched and issued, but also executed. The results are put in the ROB. When the instruction is scheduled to commit, the results are written from the ROB to the register file or memory. The architecture of a dynamic scheduler with support for speculation is repeated in Figure 22.3 for ready reference. The instructions go through four steps – issue, execute, write result and commit. The complete schedule for three iterations for the same loop discussed earlier is given in Figure 22.4.
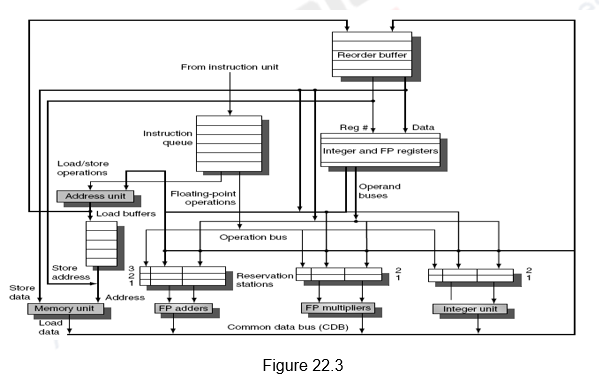
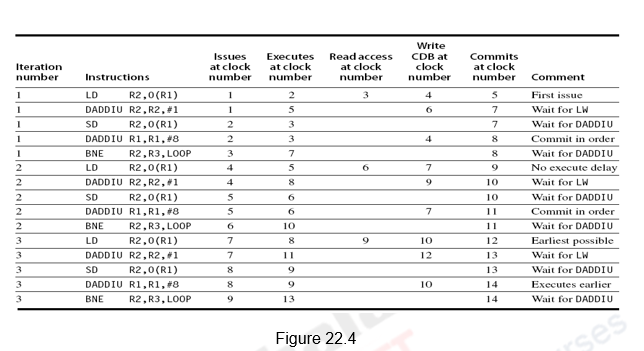
The schedule is generated as before except for the following changes:
- Since it a speculative execution, a fourth stage called commit is included.
- Also, since it is a speculative execution, the instructions after the Branch need not have to wait for the branch to resolve.
- Note that even though the branch gets resolved only in clock cycle 7, the following LD instruction executes in clock cycle 5 itself.
- Since multiple issue and execute might lead to multiple instructions finishing in the same clock cycle, two CDBs and two commits per clock cycle have been assumed.
Implementation Issues: The following points will have to be remembered while performing dynamic scheduling with speculation. We need each of the following steps to take place in 1 cycle apiece:
- o Fetch some number of instructions from instruction cache and branch prediction/target buffer
- apply the prediction
- update the buffer on miss-predictions and cache misses
- o Find instructions from the queue that can be issued in parallel
- Are reservation stations available for the collection of instructions?
- Is there room in the ROB?
- Handle WAW/WAR hazard through register renaming
- Move instructions to ROB
- o Execute at the functional units as data become available (number of cycles varies by type of functional unit)
- o Send results out on CDB if it is not currently busy
- o CDB bottle neck?
- o Commit the next instruction(s) in the ROB
- forwarding data to register/store units
- with the multi-issue, we might want to commit > 1 instruction per cycle or the ROB becomes a potential bottleneck
Design Issues with Speculation: There are many design issues that will have to be considered. They are discussed below.
- How Much Can We Speculate?
One of the main advantages of speculation is that it will handle events that might stall the pipeline earlier, say, cache misses. However, if the processor speculates and executes a costly event like a TLB miss and later on finds that this should not have been executed, the advantage of speculation is lost. Therefore, most pipelines with speculation will allow only low-cost exceptional events (such as a first-level cache miss) to be handled in speculative mode. If an expensive exceptional event occurs, such as a second-level cache miss or a TLB miss, the processor will wait until the instruction causing the event is no longer speculative before handling the event. Although this may slightly degrade the performance of some programs, it avoids significant performance losses in others, especially those that suffer from a high frequency of such events coupled with less than excellent branch prediction.
2. Speculating Through Multiple Branches: Normally we assume that we speculate on one branch. What happens if there is another branch coming in before the earlier branch is resolved? Can we speculate across multiple branches? This becomes more complicated and is a design issue.
3. Window Size: If the issue unit must look at n instructions (n is our window size) to find those that can be issued simultaneously, it requires (n-1)2 comparisons. A window of 4 instructions would require 9 comparisons, a window of 6 instructions would require 25 comparisons. These comparisons must take place in a short amount of time so that the instructions can be issued in the same cycle and data forwarded to reservation stations and ROB. That’s a lot of work in 1 cycle! Modern processors have a window size of 2-8 instructions although the most aggressive has a window 32.
To summarize, we have looked at the need for multiple issue processors. We have discussed the different types of such processors. Statically scheduled superscalars are statically scheduled, but are dynamically issued and the hazard detection is done in hardware. On the other hand, dynamically scheduled superscalars are dynamically scheduled, with dynamic issue and the hazard detection done in hardware. We also discussed the implementation issues and design issues associated with superscalar processors. The other type of multiple issue processor, namely, VLIW will be dealt with in detail in the next module.
| Web Links / Supporting Materials |
| Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th Edition, Morgan Kaufmann, Elsevier, 2009. |
| Computer Architecture – A Quantitative Approach , John L. Hennessy and David A. Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011. |