23 Cache Optimizations I
Dr A. P. Shanthi
The objectives of this module are to discuss the various factors that contribute to the average memory access time in a hierarchical memory system and discuss some of the techniques that can be adopted to improve the same.
The previous module discussed the need for a hierarchical memory system to meet the speed, capacity and cost requirements of the processor and how a cache memory can be used to hide the latency associated with the main memory access. We also looked at the various mapping policies and read / write policies adopted in cache memories.
Memory Access Time: In order to look at the performance of cache memories, we need to look at the average memory access time and the factors that will affect it. The average memory access time (AMAT) is defined as
AMAT = htc + (1 – h) (tm + tc), where tc in the second term is normally ignored.
h : hit ratio of the cache
tc : cache access time
1 – h : miss ratio of the cache
tm : main memory access time
AMAT can be written as hit time + (miss rate x miss penalty). Reducing any of these factors reduces AMAT. You can easily observe that as the hit ratio of the cache nears 1 (that is 100%), all the references are to the cache and the memory access time is governed only by the cache system. Only the cache performance matters then. On the other hand, if we miss in the cache, the miss penalty, which is the main memory access time also matters. So, all the three factors contribute to AMAT and optimizations can be carried out to reduce one or more of these parameters.
There are different methods that can be used to reduce the AMAT. There are about eighteen different cache optimizations that are organized into 4 categories as follows:
Ø Reducing the miss penalty:
§ Multilevel caches, critical word first, giving priority to read misses over write misses, merging write buffer entries, and victim caches
Ø Reducing the miss rate
§ Larger block size, larger cache size, higher associativity, way prediction and pseudo associativity, and compiler optimizations
Ø Reducing the miss penalty or miss rate via parallelism
§ Non-blocking caches, Multi banked caches, hardware & compiler prefetching
Ø Reducing the time to hit in the cache
§ Small and simple caches, avoiding address translation, pipelined cache access, and trace caches
In this module, we shall discuss the techniques that can be used to reduce the miss penalty. The time to handle a miss is becoming more and more the controlling factor. This is because of the great improvement in the speed of processors as compared to the speed of memory. Five optimizations that can be used to address the problem of improving Miss Penalty are:
• Multi-level caches
• Critical Word First and Early Restart
• Giving Priority to Read Misses over Writes
• Merging Write Buffer
• Victim Caches
We shall examine each of these in detail.
Multi-level Caches: The first techniques that we discuss and one of the most widely used techniques is using multi-level caches, instead of a single cache. When we have a single level of cache, we should decide on whether to make the cache faster to keep pace with the CPUs, or make the cache larger to overcome the widening gap between the CPU and the main memory. Both these can be handled by introducing one more level of cache. Thus, adding another level of cache between the original cache and memory simplifies the decision. The first-level cache can be small enough to match the clock cycle time of the fast CPU. Yet, the second level cache can be large enough to capture many accesses that would go to main memory, thereby lessening the effective miss penalty.
Using two levels of caches, the AMAT will have to be changed appropriately. Using the subscripts L1 and L2 to refer, respectively, to a first-level and a second-level cache, the original formula is
Average Memory Access Time = Hit TimeL1 + Miss RateL1 x Miss PenaltyL1 But, Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 x Miss PenaltyL2
Therefore, Average Memory Access Time = Hit TimeL1 + Miss RateL1 x (Hit TimeL2 + Miss RateL2 x Miss PenaltyL2)
We can define two different miss rates – local miss rate and global miss rate. Local miss rate—Number of misses in a cache divided by the total number of memory accesses to this cache (Miss rateL2). Global miss rate—Number of misses in the cache divided by the total number of memory accesses generated by the CPU (Miss RateL1 x Miss RateL2).
The local miss rate is large for second-level caches because the first-level cache skims the cream of the memory accesses. This is why the global miss rate is a more useful measure: It indicates what fraction of the memory accesses that leave the processor go all the way to memory. However, the disadvantage is that it requires extra hardware.
Figure 27.1 gives the miss rates versus the cache size for multilevel caches. It can be observed that the global cache miss rate is very similar to the single cache miss rate of the second-level cache, provided that the second-level cache is much larger than the first-level cache. The miss rate of the second level cache is a function of the miss rate of the first level cache, and hence can vary by changing the first-level cache. Thus, the global cache miss rate should be used when evaluating second-level caches.
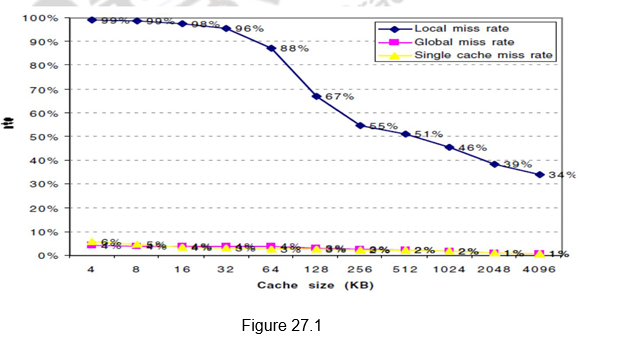
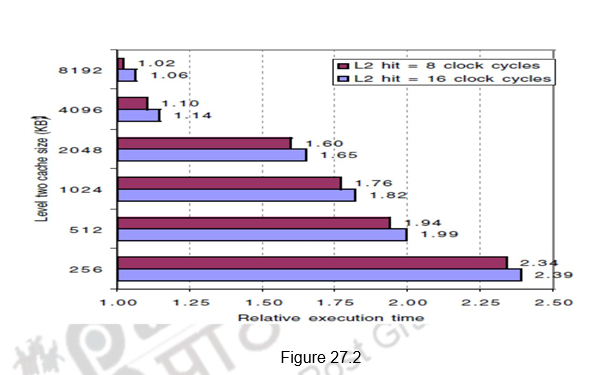
Figure 27.2 shows the relative execution times versus the second level cache size. Observe that the speed of the first-level cache affects the clock rate of the processor, while the speed of the second-level cache only affects the miss penalty of the first-level cache. A major decision is the size of a second-level cache. Since everything in the first-level cache is likely to be in the second-level cache, the second-level cache should be much bigger than the first. If second-level caches are just a little bigger, the local miss rate will be high. This observation inspires the design of huge second-level caches. Also, improving the associativity of the second-level cache will improve performance.
Early Restart and Critical Word First: This technique is based on the observation that the processor normally may need just one word of the block at a time, indicating that we don’t have to wait for the full block to be loaded before sending the requested word and restarting the processor. There are two specific strategies:
Critical word first—Request the exact word from memory and send it to the processor as soon as it arrives so that the processor continues execution as the rest of the words in the block are read. It is also called wrapped fetch and requested word first.
Early restart—Fetch the words in normal order, but as soon as the requested word of the block arrives, send it to the processor and let the processor continue execution.
Generally, these techniques only benefit designs with large cache blocks, since the benefit is low for small blocks. Note that caches normally continue to satisfy accesses to other blocks while the rest of the block is being filled. With spatial locality, there is a good chance that the next reference is to the rest of the block and the miss penalty is not very simple to calculate. When there is a second request in critical word first, the effective miss penalty is the non-overlapped time from the reference until the second piece arrives. Thus, the benefits of critical word first and early restart depend on the size of the block and the likelihood of another access to the portion of the block that has not yet been fetched.
Giving Priority to Read Misses over Writes: In the previous module, we have pointed out the usage of a write buffer. The data to be written into main memory is written into the write buffer and the processor access continues. The optimization proposed here is normally done with a write buffer. Write buffers, however, do complicate memory accesses because they might hold the updated value of a location needed on a read miss. This will lead to RAW hazards. The simplest way to handle this is for the read miss to wait until the write buffer is empty. The other alternative is to check the contents of the write buffer on a read miss, and if there are no conflicts and the memory system is available, allow the read miss to continue. Most of the processors use the second approach, thus, giving reads priority over writes.
This optimization can be effective for write back caches also. Suppose a read miss has to replace a dirty memory block. Instead of writing the dirty block to memory, and then reading memory, we could copy the dirty block to the write buffer, then read memory, and then write memory. This way the processor read will finish faster. However, RAW hazards will have to handled appropriately.
Merging Write Buffer Entries: This is an optimization used to improve the efficiency of write buffers. Normally, if the write buffer is empty, the data and the full address will be written in the buffer. The CPU continues working, while the buffer prepares to write the word to the memory. Now, if the buffer contains other modified blocks, the addresses can be checked to see if the address of this new data matches the address of a valid write buffer entry. If so, the new data can be combined with the already available entry, called write merging. This is illustrated in Figure 27.3. The first diagram shows the write buffer entries without merging. The second diagram shows the effect of merging of.the write buffer entries. Addresses 100, 108, 116 and 124 are consecutive addresses and so they have been merged into one entry.
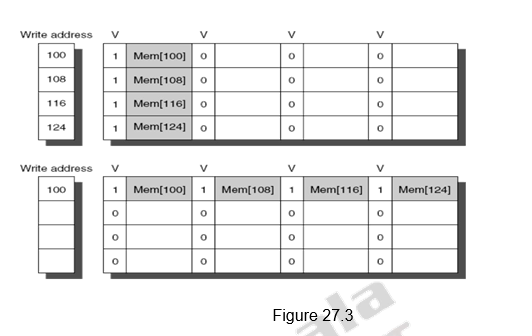
This optimization uses the memory more efficiently since multiword writes are usually faster than writes performed one word at a time. Also it reduces the stalls due to the write buffer being full. If the write buffer had been full and there had been no address match, the cache (and CPU) must wait until the buffer has an empty entry. The Sun Niagara processor is one of the processors that uses write merging. However, I/O addresses cannot allow write merging because separate I/O registers may not act like an array of words in memory.
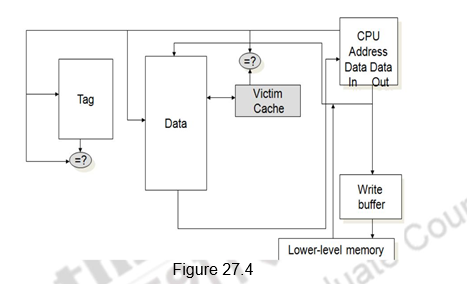
Victim Cache: The last technique that we discuss in this module to reduce miss penalty is the use of a victim cache. One approach to lower the miss penalty is to remember what was discarded in case it is needed again. For example, in the direct mapping, if the discarded block is again needed. Such recycling requires a small, fully associative cache between a cache and its refill path – called the victim cache, because it stores the victims of the eviction policy. The victim cache contains only the blocks that are discarded from a cache because of a miss – ―victims‖ – and are checked on a miss to see if they have the desired data before going to the next lower-level memory. If it is found, then the victim block and the cache block are swapped. Figure 27.4 shows the placement of the victim cache.
Normally, in a write back cache, the block that is replaced is sometimes called the victim. Hence, the AMD Opteron calls its write buffer a victim buffer. The AMD Athlon has a victim cache with eight entries. The write victim buffer or victim buffer contains the dirty blocks that are discarded from a cache because of a miss. Rather than stall on a subsequent cache miss, the contents of the buffer are checked on a miss to see if they have the desired data before going to the next lower-level memory. In contrast to a write buffer, the victim cache can include any blocks discarded from the cache on a miss, whether they are dirty or not. While the purpose of the write buffer is to allow the cache to proceed without waiting for dirty blocks to write to memory, the goal of a victim cache is to reduce the impact of conflict misses. Write buffers are far more popular today than victim caches, despite the confusion caused by the use of ―victim‖ in their title.
To summarize, we have defined the average memory access time in this module. The AMAT depends on the hit time, miss rate and miss penalty. Several optimizations exist to handle each of these factors. We discussed five different techniques for reducing the miss penalty. They are:
- Multilevel caches
- Early restart and Critical word first
- Giving priority to read misses over write misses
- Merging write buffer entries and
- Victim caches
Web Links / Supporting Materials
- Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th Edition, Morgan Kaufmann, Elsevier, 2009.
- Computer Architecture – A Quantitative Approach , John L. Hennessy and David A.Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011.
- Computer Organization, Carl Hamacher, Zvonko Vranesic and Safwat Zaky, 5th.Edition, McGraw- Hill Higher Education, 2011.