37 Exploiting ILP with Software Approaches II
Dr A. P. Shanthi
The objectives of this module are to discuss some more software approaches used for exploiting ILP. The concept of software pipelining, predication and software pipelining are discussed in detail.
All processors since about 1985 have used pipelining to overlap the execution of instructions and improve the performance of the processor. This overlap among instructions is called Instruction Level Parallelism since the instructions can be evaluated in parallel. There are two largely separable techniques to exploit ILP:
- Dynamic and depend on the hardware to locate parallelism
- Static and rely much more on software
Static techniques are adopted by the compiler to improve performance. Processors that predominantly use hardware approaches use other techniques on top of these optimizations to improve performance. The dynamic, hardware-intensive approaches dominate processors like the PIII, P4, and even the latest processors like i3, i5 and i7. The software intensive approaches are used in processors like Itanium. The previous module concentrated on exploiting loop level parallelism through loop unrolling. This module will discuss other techniques that can be used for exploiting ILP.
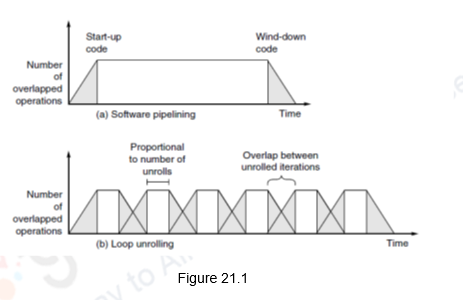
Software Pipelining: This is yet another optimization that can improve the loop-execution performance. It is a symbolic unrolling process. It derives its performance gain by filling the delays within each iteration of a loop body with instructions from different iterations of that same loop. By scheduling instructions from different iterations into a single iteration of the loop, a new loop is formed with independent instructions. These independent instructions form the kernel of the loop and can be executed in parallel. By choosing instructions from different iterations, dependent computations are separated from one another by an entire loop body, increasing the possibility that the unrolled loop can be scheduled without stalls. Since we pick instructions from multiple iterations and form a kernel, some instructions from the initial iterations and the final iterations will not be covered. These will be handled separately as a start up code and winding up code.
The concept of software pipelining is best explained with the help of an example. Consider the same example used for loop unrolling and repeated here for convenience. Consider the following iterative loop and the assembly equivalent of that.
for(i=1;i<=1000;i++)
x(i) = x(i) + s;
Loop: LD F0,0(R1) ;F0=vector element
ADDD F4,F0,F2 ;add scalar from F2
SD 0(R1),F4 ;store result
SUBI R1,R1,8 ;decrement pointer 8bytes (DW)
BNEZ R1,Loop ;branch R1!=zero
NOP ;delayed branch slot
The body of the loop consists of three instructions and each of these is dependent on the other. The true data dependences in the loop are indicated below. The other two instructions are called the loop maintenance code.
Loop: LD F0,0(R1) ;F0=vector element
ADDD F4,F0,F2 ;add scalar in F2
SD 0(R1),F4 ;store result
SUBI R1,R1,8 ;decrement pointer 8B (DW)
BNEZ R1,Loop ;branch R1!=zero
NOP ;delayed branch slot
Let us consider the following set of latencies for discussion purposes:
| Instruction producing result | Instruction using result | Latency in clock cycles
|
| FP ALU operation | Another FP Operation | 3 |
| FP ALU operation | Store double | 2 |
| Load double | FP ALU operation | 1 |
| Load double | Store double | 0 |
| Integer operation | Integer operation | 0 |
Original schedule: If we try to schedule the code for the above latencies, the schedule can be as indicated below. There is one stall between the first and the second dependent instruction, two stalls between the Add and the dependent Store. In the loop maintenance code also, there needs to be one stall introduced because of the data dependency between the Sub and Branch. The last stall is for the branch instruction, i.e. the branch delay slot. One iteration of the loop takes ten clock cycles to execute.
1 Loop: LD F0, 0(R1) ;F0=vector element
2 stall
3 ADDD F4, F0, F2 ;add scalar in F2
4 stall
5 stall
6 SD 0(R1), F4 ;store result
7 SUBI R1, R1, 8 ;decrement pointer 8 Byte (DW)
8 stall
9 BNEZ R1, Loop ;branch R1!=zero
10 stall ;delayed branch slot
Each stall can be treated as a no operation (nop). We could perform useful operations here by inserting instructions from different iterations to replace the nops, which is precisely what software pipelining does.
Steps in Software Pipelining: There are three steps to follow in software pipelining.
- Unroll loop body with an unroll factor of n
- – Assuming a value of 3, the unrolled loop is shown below:
LD F0,0(R1)
ADDD F4,F0,F2
SD 0(R1),F4
LD F6,-8(R1)
ADDD F8,F6,F2
SD -8(R1),F8
LD F10,-16(R1)
ADDD F12,F10,F2
SD -16(R1),F12
- – Since the loop has been unrolled, the loop maintenance code has not been included.
- – There three iterations will be “collapsed” into a single loop body containing instructions from different iterations of the original loop body
- Select an order to be followed in the pipelined loop
- – Each instruction (L.D, ADD.D and S.D) must be selected at least once to make sure that we don’t leave out any instructions when we collapse the loop into a single pipelined loop
- – The LD from the (i+2)th. Iteration, ADD from the (i+1)th. iteration and LD from iteration I are selected to form the kernel
- Paste instructions from different iterations into the new pipelined loop body
- – A software-pipelined loop interleaves instructions from different iterations without unrolling the loop, as illustrated below. This technique is the software counterpart to what Tomasulo’s algorithm does in hardware.
There is also some start-up code that is needed before the loop begins as well as code to finish up after the loop is completed. By looking at the unrolled version we can see what the start-up code and finish code will need to be. For start-up, we will need to execute any instructions that correspond to iteration 1 and 2 that will not be executed. These instructions are the L.D for iterations 1 and 2 and the ADD.D for iteration 1. For the finish code, we need to execute any instructions that will not be executed in the final two iterations. These include the ADD.D for the last iteration and the S.D for the last two iterations. The start up code is called the prolog, preamble or preheader. The finish code is called the epilog, postamble or postheader. Note that the process is similar to a hardware pipeline getting filled up. It takes some time for the pipeline to fill up and then the pipeline works with all the stages full and then it takes some time for the pipeline to drain. It is because of this similarity that it is called software pipelining. When the kernel is running, we have a completely independent set of instructions that can be scheduled on a multiple issue processor like VLIW, to get maximum performance.
This loop can be run at a rate of 5 cycles per result, ignoring the start-up and clean-up portions, and assuming that DADDUI is scheduled after the ADD.D and the L.D instruction, with an adjusted offset, is placed in the branch delay slot. Because the load and store are separated by offsets of 16 (two iterations), the loop should run for two fewer iterations. Notice that the reuse of registers (e.g., F4, F0, and R1) requires the hardware to avoid the WAR hazards that would occur in the loop. This hazard should not be a problem in this case, since no data-dependent stalls should occur.
The major advantage of software pipelining over loop unrolling is that software pipelining consumes less code space. Each of them reduce a different type of overhead. Loop unrolling reduces the overhead of the loop—the branch and counter-update code. Software pipelining reduces the time when the loop is not running at peak speed to once per loop at the beginning and end. If we unroll a loop that does 100 iterations a constant number of times, say 5, we pay the overhead 100/5 = 20 times – every time the inner unrolled loop is initiated. Because these techniques attack two different types of overhead, the best performance can come from doing both. The difference between the two techniques is illustrated in Figure 21.1.
Predication: So far, we have looked at different techniques that the compiler uses to exploit ILP. Software support of ILP is best when code is predictable at compile time. But what if there’s no predictability? In such cases, the compiler cannot exploit ILP on its own and relies on the hardware to provide some support. We shall now look at such techniques. First of all, we shall discuss about predication.
Predicated or conditional instructions are provided in the ISA of the processor and the compiler uses these instructions. A predicated instruction is executed if the condition is true and annulled if the condition is false. Thus, branches can be removed and the condition that the branches tested for can be incorporated as a predicate in the instruction. A control dependence is thus transformed to a data dependence. Some architectures have a few predicated instructions, whereas, some architectures support full predication. That is, the execution of all instructions is controlled by a predicate. This feature allows us to simply convert large blocks of code that are branch dependent. When we have an if then else construct, the statements in the if section will be replaced with a predicate and all the statements in the else clause will be replaced with the opposite predicate, say zero and non-zero. This process is called if-conversion.
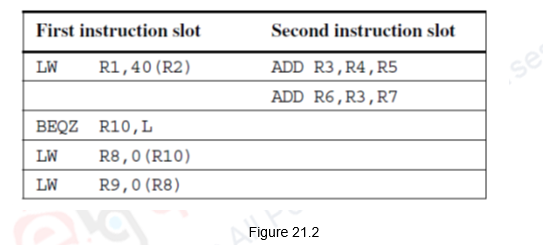
Predicated instructions can also be used to speculatively move an instruction that is time-critical, but may cause an exception if moved before a guarding branch. Consider the following code sequence shown in Figure 21.2 for a two-issue superscalar that can issue a combination of one memory reference and one ALU operation, or a branch by itself, every cycle. The second cycle wastes one slot and the last LW instruction has a data dependence on the previous LW. This will cause a stall if the branch is not taken.
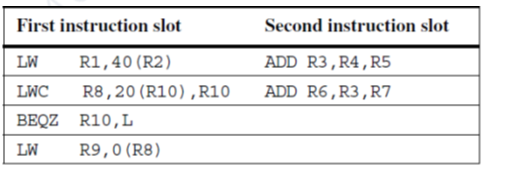
The use of predicated instructions can improve the schedule as indicated in Figure 21.3. The conditional load instruction, LWC helps in filling the slot in the second clock cycle and also avoids the stall due to data dependence for the last instruction. The conditional load is executed unless the third operand is zero. Thus, this gives a better schedule.
Predicated instructions have some drawbacks. They are:
-
-
- Annulled predicated instructions also take some processor resources
- Predicated instructions are more useful when the predicate can be evaluated early
- The use of conditional instructions can be limited when the control flow involves more than a simple alternative sequence
- Conditional instructions may have some speed penalty compared with unconditional instructions
- As data dependences are normally resolved early in the pipeline, this may give rise to stalls
-
Software Speculation with Hardware Support: The compiler uses static prediction to predict the behaviour of branches at compile time either from the program structure or by using a profile. In such cases, the compiler may want to speculate either to improve the scheduling or to increase the issue rate. Predicated instructions provide one method to speculate, but they are really more useful when control dependences can be completely eliminated by if-conversion. However, in many cases, we would like to move speculated instructions not only before branch, but before the condition evaluation, and predication cannot achieve this.
In order to perform aggressive speculation, we need three capabilities:
- The ability of the compiler to find instructions that, with the possible use of register renaming, can be speculatively moved and not affect the program data flow
- The ability to ignore exceptions in speculated instructions, until we know that such exceptions should really occur, and
- The ability to speculatively interchange loads and stores, or stores and stores, which may have address conflicts.
The first of these is a compiler capability, while the last two require hardware support, which we explore next.
Hardware Support for Preserving Exception Behavior: In order to speculate ambitiously, we must be able to move any type of instruction and still preserve its exception behavior. The key to being able to do this is to observe that the results of a speculated sequence that is mispredicted will not be used in the final computation, and such a speculated instruction should not cause an exception.
There are four methods that have been investigated for supporting more ambitious speculation without introducing erroneous exception behavior:
- The hardware and operating system cooperatively ignore exceptions for speculative instructions. This approach preserves exception behavior for correct programs, but not for incorrect ones.
- Speculative instructions that never raise exceptions are used, and checks are introduced to determine when an exception should occur.
- A set of status bits, called poison bits, are attached to the result registers written by speculated instructions when the instructions cause exceptions. The poison bits cause a fault when a normal instruction attempts to use the register.
- A mechanism is provided to indicate that an instruction is speculative and the hardware buffers the instruction result until it is certain that the instruction is no longer speculative.
Finally, a comparison between software and hardware speculation can be done. The comparison is provided below.
-
- In the case of software speculation, memory references must be disambiguated
- Hardware-based speculation works better when control flow is unpredictable
- Hardware-based speculation maintains a completely precise exception model even for speculated instructions
- Hardware-based speculation does not require compensation or bookkeeping code, unlike software speculation mechanisms
- Compiler-based approaches may benefit from the ability to see further in the code sequence, resulting in a better code scheduling than a purely hardware-driven approach
- Hardware-based speculation with dynamic scheduling does not require different code sequences to achieve good performance for different implementations of an architecture
To summarize, we have looked at how software pipelining can be implemented. It does a symbolic unrolling process, just like what Tomasulo does in hardware. We also looked at how the compiler can exploit more ILP using predicated or conditional instructions. The concept of speculation can also be used by the compiler to uncover more ILP, provided the hardware supports in preserving exception behavior and memory disambiguation.
| Web Links / Supporting Materials |
| Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th Edition, Morgan Kaufmann, Elsevier, 2009. |
| Computer Architecture – A Quantitative Approach , John L. Hennessy and David A. Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011. |