7 Floating Point Arithmetic Unit
Dr A. P. Shanthi
The objectives of this module are to discuss the need for floating point numbers, the standard representation used for floating point numbers and discuss how the various floating point arithmetic operations of addition, subtraction, multiplication and division are carried out.
Floating-point numbers and operations
Representation
When you have to represent very small or very large numbers, a fixed point representation will not do. The accuracy will be lost. Therefore, you will have to look at floating-point representations, where the binary point is assumed to be floating. When you consider a decimal number 12.34 * 107, this can also be treated as 0.1234 * 109, where 0.1234 is the fixed-point mantissa. The other part represents the exponent value, and indicates that the actual position of the binary point is 9 positions to the right (left) of the indicated binary point in the fraction. Since the binary point can be moved to any position and the exponent value adjusted appropriately, it is called a floating-point representation. By convention, you generally go in for a normalized representation, wherein the floating-point is placed to the right of the first nonzero (significant) digit. The base need not be specified explicitly and the sign, the significant digits and the signed exponent constitute the representation.
The IEEE (Institute of Electrical and Electronics Engineers) has produced a standard for floating point arithmetic. This standard specifies how single precision (32 bit) and double precision (64 bit) floating point numbers are to be represented, as well as how arithmetic should be carried out on them. The IEEE single precision floating point standard representation requires a 32 bit word, which may be represented as numbered from 0 to 31, left to right. The first bit is the sign bit, S, the next eight bits are the exponent bits, ‘E’, and the final 23 bits are the fraction ‘F’. Instead of the signed exponent E, the value stored is an unsigned integer E’ = E + 127, called the excess-127 format. Therefore, E’ is in the range 0 £ E’ £ 255.
S E’E’E’E’E’E’E’E’ FFFFFFFFFFFFFFFFFFFFFFF
0 1 8 9 31
The value V represented by the word may be determined as follows:
- If E’ = 255 and F is nonzero, then V = NaN (“Not a number”)
- If E’ = 255 and F is zero and S is 1, then V = -Infinity
- If E’ = 255 and F is zero and S is 0, then V = Infinity
- If 0 < E< 255 then V =(-1)**S * 2 ** (E-127) * (1.F) where “1.F” is intended to represent the binary number created by prefixing F with an implicit leading 1 and a binary point.
- If E’ = 0 and F is nonzero, then V = (-1)**S * 2 ** (-126) * (0.F). These are “unnormalized” values.
- If E’= 0 and F is zero and S is 1, then V = -0
- If E’ = 0 and F is zero and S is 0, then V = 0
For example,
0 00000000 00000000000000000000000 = 0
1 00000000 00000000000000000000000 = -0
0 11111111 00000000000000000000000 = Infinity
1 11111111 00000000000000000000000 = -Infinity
0 11111111 00000100000000000000000 = NaN
1 11111111 00100010001001010101010 = NaN
0 10000000 00000000000000000000000 = +1 * 2**(128-127) * 1.0 = 2
0 10000001 10100000000000000000000 = +1 * 2**(129-127) * 1.101 = 6.5
1 10000001 10100000000000000000000 = -1 * 2**(129-127) * 1.101 = -6.5
0 00000001 00000000000000000000000 = +1 * 2**(1-127) * 1.0 = 2**(-126)
0 00000000 10000000000000000000000 = +1 * 2**(-126) * 0.1 = 2**(-127)
0 00000000 00000000000000000000001 = +1 * 2**(-126) *
0.00000000000000000000001 = 2**(-149) (Smallest positive value)
(unnormalized values)
Double Precision Numbers:
The IEEE double precision floating point standard representation requires a 64-bit word, which may be represented as numbered from 0 to 63, left to right. The first bit is the sign bit, S, the next eleven bits are the excess-1023 exponent bits, E’, and the final 52 bits are the fraction ‘F’:
S E’E’E’E’E’E’E’E’E’E’E’
FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
0 1 11 12
63
The value V represented by the word may be determined as follows:
- If E’ = 2047 and F is nonzero, then V = NaN (“Not a number”)
- If E’= 2047 and F is zero and S is 1, then V = -Infinity
- If E’= 2047 and F is zero and S is 0, then V = Infinity
- If 0 < E’< 2047 then V = (-1)**S * 2 ** (E-1023) * (1.F) where “1.F” is intended to represent the binary number created by prefixing F with an implicit leading 1 and a binary point.
- If E’= 0 and F is nonzero, then V = (-1)**S * 2 ** (-1022) * (0.F) These are “unnormalized” values.
- If E’= 0 and F is zero and S is 1, then V = – 0
- If E’= 0 and F is zero and S is 0, then V = 0
Arithmetic unit
Arithmetic operations on floating point numbers consist of addition, subtraction, multiplication and division. The operations are done with algorithms similar to those used on sign magnitude integers (because of the similarity of representation) — example, only add numbers of the same sign. If the numbers are of opposite sign, must do subtraction.
ADDITION
Example on decimal value given in scientific notation:
3.25 x 10 ** 3
+ 2.63 x 10 ** -1
—————–
first step: align decimal points
second step: add
3.25 x 10 ** 3
+ 0.000263 x 10 ** 3
——————–
3.250263 x 10 ** 3
(presumes use of infinite precision, without regard for accuracy)
third step: normalize the result (already normalized!)
Example on floating pt. value given in binary:
.25 = 0 01111101 00000000000000000000000
100 = 0 10000101 10010000000000000000000
To add these fl. pt. representations,
step 1: align radix points
shifting the mantissa left by 1 bit decreases the exponent by 1
shifting the mantissa right by 1 bit increases the exponent by 1
we want to shift the mantissa right, because the bits that fall off the end should come from the least significant end of the mantissa
-> choose to shift the .25, since we want to increase it’s exponent.
-> shift by 10000101
-01111101
———
00001000 (8) places.
0 01111101 00000000000000000000000 (original value)
0 01111110 10000000000000000000000 (shifted 1 place)
(note that hidden bit is shifted into msb of mantissa)
0 01111111 01000000000000000000000 (shifted 2 places)
0 10000000 00100000000000000000000 (shifted 3 places)
0 10000001 00010000000000000000000 (shifted 4 places)
0 10000010 00001000000000000000000 (shifted 5 places)
0 10000011 00000100000000000000000 (shifted 6 places)
0 10000100 00000010000000000000000 (shifted 7 places)
0 10000101 00000001000000000000000 (shifted 8 places)
step 2: add (don’t forget the hidden bit for the 100)
0 10000101 1.10010000000000000000000 (100)
+ 0 10000101 0.00000001000000000000000 (.25)
—————————————
0 10000101 1.10010001000000000000000
step 3: normalize the result (get the “hidden bit” to be a 1)
It already is for this example.
| result is | 0 10000101 10010001000000000000000 |
SUBTRACTION
Same as addition as far as alignment of radix points
Then the algorithm for subtraction of sign mag. numbers takes over.
before subtracting,
compare magnitudes (don’t forget the hidden bit!)
change sign bit if order of operands is changed.
don’t forget to normalize number afterward.
MULTIPLICATION
Example on decimal values given in scientific notation:
3.0 x 10 ** 1
+ 0.5 x 10 ** 2
—————–
Algorithm: multiply mantissas
add exponents
3.0 x 10 ** 1
+ 0.5 x 10 ** 2
—————–
1.50 x 10 ** 3
Example in binary: Consider a mantissa that is only 4 bits.
0 10000100 0100
x 1 00111100 1100

Add exponents:
always add true exponents (otherwise the bias gets added in twice)

DIVISION
It is similar to multiplication.
do unsigned division on the mantissas (don’t forget the hidden bit)
subtract TRUE exponents
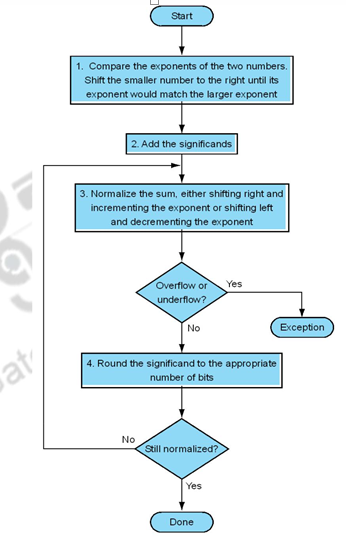
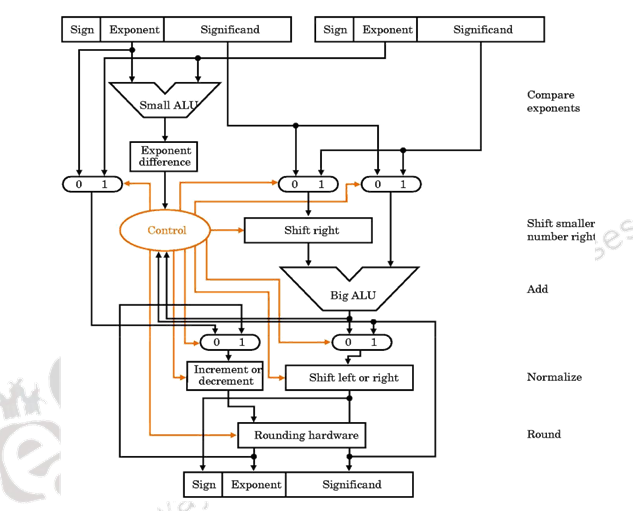
The organization of a floating point adder unit and the algorithm is given below.
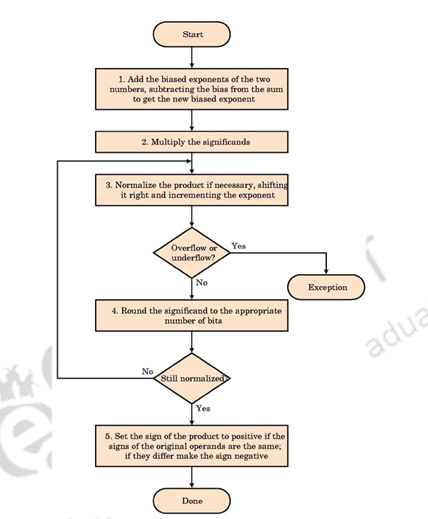
The floating point multiplication algorithm is given below. A similar algorithm based on the steps discussed before can be used for division.
Rounding
The floating point arithmetic operations discussed above may produce a result with more digits than can be represented in 1.M. In such cases, the result must be rounded to fit into the available number of M positions. The extra bits that are used in intermediate calculations to improve the precision of the result are called guard bits. It is only a tradeoff of hardware cost (keeping extra bits) and speed versus accumulated rounding error, because finally these extra bits have to be rounded off to conform to the IEEE standard.
Rounding Methods:
- Truncate
– Remove all digits beyond those supported
– 1.00100 -> 1.00
- Round up to the next value
– 1.00100 -> 1.01
- Round down to the previous value
– 1.00100 -> 1.00
– Differs from Truncate for negative numbers
- Round-to-nearest-even
– Rounds to the even value (the one with an LSB of 0)
– 1.00100 -> 1.00
– 1.01100 -> 1.10
– Produces zero average bias
– Default mode
A product may have twice as many digits as the multiplier and multiplicand
– 1.11 x 1.01 = 10.0011
For round-to-nearest-even, we need to know the value to the right of the LSB (round bit) and whether any other digits to the right of the round digit are 1’s (the sticky bit is the OR of these digits). The IEEE standard requires the use of 3 extra bits of less significance than the 24 bits (of mantissa) implied in the single precision representation – guard bit, round bit and sticky bit. When a mantissa is to be shifted in order to align radix points, the bits that fall off the least significant end of the mantissa go into these extra bits (guard, round, and sticky bits). These bits can also be set by the normalization step in multiplication, and by extra bits of quotient (remainder) in division. The guard and round bits are just 2 extra bits of precision that are used in calculations. The sticky bit is an indication of what is/could be in lesser significant bits that are not kept. If a value of 1 ever is shifted into the sticky bit position, that sticky bit remains a 1 (“sticks” at 1), despite further shifts.
To summarize, in his module we have discussed the need for floating point numbers, the IEEE standard for representing floating point numbers, Floating point addition / subtraction, multiplication, division and the various rounding methods.
Web Links / Supporting Materials
- Computer Organization, Carl Hamacher, Zvonko Vranesic and Safwat Zaky, 5th.Edition, McGraw- Hill Higher Education, 2011.
- Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th.Edition, Morgan Kaufmann, Elsevier, 2009.