16 Advanced Concepts of ILP – Dynamic scheduling
Dr A. P. Shanthi
The objectives of this module are to discuss about the advanced concepts used for exploiting ILP and to discuss the concepts of dynamic scheduling in particular.
All processors since about 1985 have used pipelining to overlap the execution of instructions and improve the performance of the processor. This overlap among instructions is called Instruction Level Parallelism since the instructions can be evaluated in parallel. There are two largely separable techniques to exploit ILP:
• Dynamic and depend on the hardware to locate parallelism
• Static and rely much more on software
Static techniques are adopted by the compiler to improve performance. Processors that predominantly use hardware approaches use other techniques on top of these optimizations to improve performance. The dynamic, hardware-intensive approaches dominate processors like the PIII, P4, and even the latest processors like i3, i5 and i7.
We know that,
Pipeline CPI = Ideal pipeline CPI + Structural stalls + Data hazard stalls + Control hazard stalls
The ideal pipeline CPI is a measure of the maximum performance attainable by the implementation.
When we look at performing optimizations, and if we only consider the basic block, then, both the compiler as well as the hardware does not have too many options. A basic block is a straight-line code sequence with no branches in, except to the entry, and no branches out, except at the exit. With the average dynamic branch frequency of 15% to 25%, we normally have only 4 to 7 instructions executing between a pair of branches. Additionally, the instructions in the basic block are likely to depend on each other. So, the basic block does not offer too much scope for exploiting ILP. In order to obtain substantial performance enhancements, we must exploit ILP across multiple basic blocks. The simplest method to exploit parallelism is to explore loop-level parallelism, to exploit parallelism among iterations of a loop. Vector architectures are one way of handling loop level parallelism. Otherwise, we will have to look at either dynamic or static methods of exploiting loop level parallelism. One of the common methods is loop unrolling, dynamically via dynamic branch prediction by the hardware, or statically via by the compiler using static branch prediction.
While performing such optimizations, both the hardware as well as the software must preserve program order. That is, the order in which instructions would execute if executed sequentially, one at a time, as determined by the original source program, should be maintained. The data flow, the actual flow of data values among instructions that produce results and those that consume them, should be maintained. Also, instructions involved in a name dependence can execute simultaneously only if the name used in the instructions is changed so that these instructions do not conflict. This is done by the concept of register renaming. This resolves name dependences for registers. This can again be done by the compiler or by hardware. Preserving exception behavior, i.e., any changes in instruction execution order must not change how exceptions are raised in program, should also be considered.
So far, we have assumed static scheduling with in-order-execution and looked at handling all the issues discussed above using various techniques. In this module, we will discuss about the need for doing dynamic scheduling and how we execute instructions out-of-order.
Dynamic Scheduling is a technique in which the hardware rearranges the instruction execution to reduce the stalls, while maintaining data flow and exception behavior. The advantages of dynamic scheduling are:
• It handles cases when dependences are unknown at compile time
– (e.g., because they may involve a memory reference)
• It simplifies the compiler
• It allows code compiled for one pipeline to run efficiently on a different pipeline
• Hardware speculation, a technique with significant performance advantages, builds on dynamic scheduling
In a dynamically scheduled pipeline, all instructions pass through the issue stage in order; however they can be stalled or bypass each other in the second stage and thus enter execution out of order. Instructions will also finish out-of-order.
Score boarding is a dynamic scheduling technique for allowing instructions to execute out of order when there are sufficient resources and no data dependences. But this technique has some drawbacks. The Tomasulo’s algorithm is a more sophisticated technique that has several major enhancements over Score boarding. We will discuss the Tomasulo’s technique here.
The key idea is to allow instructions that have operands available to execute, even if the earlier instructions have not yet executed. For example, consider the following sequence of instructions:
DIV.D F0 , F2 , F4
ADD.D F10 , F0 , F8
SUB.D F12 , F8 , F14
The DIV instruction is a long latency instruction and ADD is dependent on it. So, ADD cannot be executed without DIV finishing. But, SUB has all the operands available, and can be executed earlier than ADD. We are basically enabling out-of-order execution, which will lead to out-of-order completion. With floating point instructions, even with in-order execution, we might have out-of-order completion because of the differing latencies among instructions. Now, with out-of-order execution, we will definitely have out-of-order completion. We should also make sure that no hazards happen in the pipeline because of dynamic scheduling.
In order to allow instructions to execute out-of-order, we need to do some changes to the decode stage. So far, we have assumed that during the decode stage, the MIPS pipeline decodes the instruction and also reads the operands from the register file. Now, with dynamic scheduling, we bring in a change to enable out-of-order execution. The decode stage or the issue stage only decodes the instructions and checks for structural hazards. After that, the instructions will wait until there are no data hazards, and then read operands. This will enable us to do an in order issue, out of order execution and out of order completion. For example, in our earlier example, DIV, ADD and SUB will be issued in-order. But, ADD will stall after issue because of the true data dependency, but SUB will proceed to execution.
There are some disadvantages with dynamic scheduling. They are:
• Substantial increase in hardware complexity
• Complicates exception handling
• Out-of-order execution and out-of-order completion will create the possibility for WAR and WAW hazards. WAR hazards did not occur earlier.
The entire book keeping is done in hardware. The hardware considers a set of instructions called the instruction window and tries to reschedule the execution of these instructions according to the availability of operands. The hardware maintains the status of each instruction and decides when each of the instructions will move from one stage to another. The dynamic scheduler introduces register renaming in hardware and eliminates WAW and WAR hazards. The following example shows how register renaming can be done. There is a name dependence with F6.
• Example:
DIV.DF0,F2,F4
ADD.DF6,F0,F8
S.DF6,0(R1)
SUB.DF8,F10,F14
MUL.D F6,F10,F8
With renaming done as shown below, only RAW hazards remain, which can be strictly ordered.
• Example:
DIV.DF0,F2,F4
ADD.DS,F0,F8
S.DS,0(R1)
SUB.D T,F10,F14
MUL.D F6,F10,T
In the Tomasulo’s approach, the register renaming is provided by reservation stations (RSs). Associated with every functional unit, we have a few reservation stations. When an instruction is issued, a reservation station is allocated to it. The reservation station stores information about the instruction and buffers the operand values (when available). So, the reservation station fetches and buffers an operand as soon as it becomes available (not necessarily involving register file). This helps in avoiding WAR hazards. If an operand is not available, it stores information about the instruction that supplies the operand. The renaming is done through the mapping between the registers and the reservation stations. When a functional unit finishes its operation, the result is broadcast on a result bus, called the common data bus (CDB). This value is written to the appropriate register and also the reservation station waiting for that data. When two instructions are to modify the same register, only the last output updates the register file, thus handling WAW hazards. Thus, the register specifiers are renamed with the reservation stations, which may be more than the registers. For load and store operations, we use load and store buffers, which contain data and addresses, and act like reservation stations.
The three steps in a dynamic scheduler are listed below:
• Issue
• Get next instruction from FIFO queue
• If available RS, issue the instruction to the RS with operand values if available
• If a RS is not available, it becomes a structural hazard and the instruction stalls
• If an earlier instruction is not issued, then subsequent instructions cannot be issued
• If operand values not available, stall the instruction
• Execute
• When operand becomes available, store it in any reservation station waiting for it
• When all operands are ready, issue the instruction for execution
• Loads and store are maintained in program order through the effective address
• No instruction allowed to initiate execution until all branches that proceed it in program order have completed
• Write result
• Write result on CDB into reservation stations and store buffers
• Stores must wait until address and value are received
The dynamic scheduler maintains three data structures – the reservation station, a register result data structure that keeps of the instruction that will modify a register and an instruction status data structure. The third one is more for understanding purposes. The reservation station components are as shown below:
Name —Identifying the reservation station
Op—Operation to perform in the unit (e.g., + or –)
Vj, Vk—Value of Source operands
– Store buffers have V field, result to be stored
Qj, Qk—Reservation stations producing source registers (value to be written)
– Store buffers only have Qi for RS producing result Busy—Indicates reservation station or FU is busy
Register result status—Indicates which functional unit will write each register, if one exists. It is blank when there are no pending instructions that will write that register. The instruction status gives the status of each instruction in the instruction window. All the three data structures are shown in Figure 16.1.
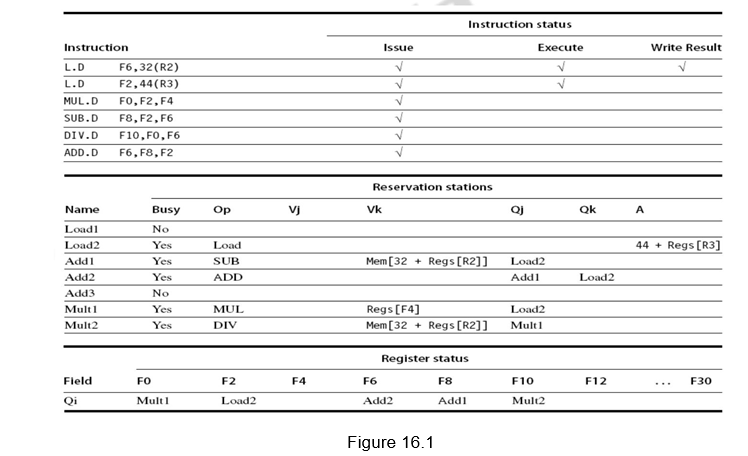
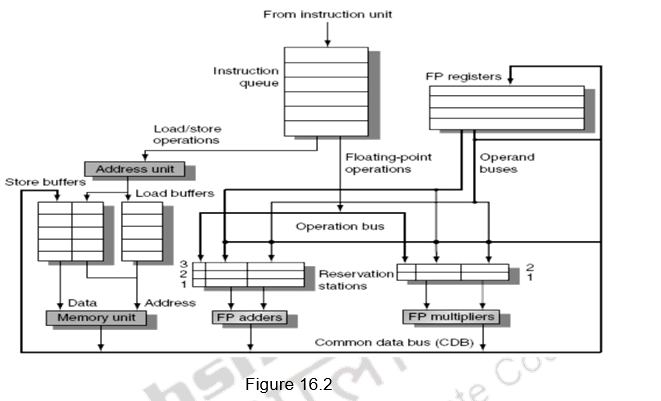
Figure 16.2 shows the organization of the Tomasulo’s dynamic scheduler. Instructions are taken from the instruction queue and issued. During the issue stage, the instruction is decoded and allocated an RS entry. The RS station also buffers the operands if available. Otherwise, the RS entry marks the pending RS value in the Q field. The results are passed through the CDB and go to the appropriate register, as dictated by the register result data structure, as well as the pending RSs.
Dependences with respect to memory locations will also have to be handled properly. A load and a store can safely be done out of order, provided they access different addresses. If a load and a store access the same address, then either
- the load is before the store in program order and interchanging them results in a WAR hazard, or
- the store is before the load in program order and interchanging them results in a RAW hazard.
Similarly, interchanging two stores to the same address results in a WAW hazard. Hence, to determine if a load can be executed at a given time, the processor can check whether any uncompleted store that precedes the load in program order shares the same data memory address as the load. Similarly, a store must wait until there are no unexecuted loads or stores that are earlier in program order and share the same data memory address.
To summarize, we have discussed the importance of dynamic scheduling, wherein the hardware does a dynamic reorganization of code at run time. We have discussed the Tomasulo’s dynamic scheduling approach. The book keeping done and the various steps used have been elaborated.
Web Links / Supporting Materials
- Computer Organization and Design – The Hardware / Software Interface, David A. Patterson and John L. Hennessy, 4th Edition, Morgan Kaufmann, Elsevier, 2009.
- Computer Architecture – A Quantitative Approach , John L. Hennessy and David A. Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011.