35 Warehouse-Scale Computers
Dr A. P. Shanthi
The objectives of this module are to discuss about the salient features of warehouse-scale computers and see how request level parallelism and data level parallelism is exploited here.
There are basically two types of parallelism present in applications . They are – Data Level Parallelism (DLP) as there are many data items that can be operated in parallel and Task Level Parallelism (TLP) that arises because tasks of work are created that can operate independently and in parallel. Computer systems exploit the DLP and TLP exhibited by applications in four major ways. Instruction Level Parallelism (ILP) exploits DLP at modest levels using the help of compilers with ideas like pipelining , dynamic scheduling and speculative execution. Vector Architectures and GPUs exploit DLP. Thread level parallelism exploits either DLP or TLP in a tightly coupled hardware model that allows for interaction among threads. Request Level Parallelism (RPL) exploits parallelism among largely decoupled tasks specified by the programmer or the OS. This module discusses about warehouse-scale computers that basically exploit request level parallelism and data level parallelism.
Warehouse-scale computers (WSCs) form the foundation of internet services that people use for search, social networking, online maps, video sharing, online shopping, email, cloud computing, etc. The ever increasing popularity of internet services has necessitated the creation of WSCs in order to keep up with the growing demands of the public. Although WSCs may seem to be large datacenters, their architecture and operation are different from datacenters. The WSC is a descendant of the supercomputer. Today’s WSCs act as one giant machine. The main parts of a WSC are the building with the electrical and cooling infrastructure, the networking equipment and the servers, about 50000 to 100000 of them. The costs are of the order of $150M to build such an infrastructure . WSCs have many orders of magnitude more users than high performance computing and play a very important role today.
WSCs share many goals and requirements with servers. They are:
Cost-performance: Because of the scale involved, the cost-performance becomes very critical. Even small savings can amount to a large amount of money.
Energy efficiency: There is a lot of money invested in power distribution for consumption and also to remove the heat generated through cooling systems). Hence, work done per joule is critical for both WSCs and servers because of the high cost of building the power and mechanical infrastructure for a warehouse of computers and for the monthly utility bills to power servers. If servers are not energy-efficient they will increase (1) cost of electricity, (2) cost of infrastructure to provide electricity, (3) cost of infrastructure to cool the servers. Therefore, we need to optimize the computation per joule.
Dependability via redundancy: The hardware and software in a WSC must collectively provide at least 99.99% availability, while individual servers are much less reliable. Redundancy is the key to dependability for both WSCs and servers. While servers use more hardware at higher costs to provide high availability, WSC architects rely on multiple cost-effective servers connected by a low cost network and redundancy managed by software. Multiple WSCs may be needed to handle faults in whole WSCs. Multiple WSCs also reduce latency for services that are widely deployed.
Network I/O: Networking is needed to interface to the public as well as to keep data consistent between multiple WSCs.
Both interactive and batch-processing workloads: Search and social networks are interactive and require fast response times. At the same time, indexing, big data analytics etc. create a lot of batch processing workloads also.
WSCs also have characteristics that are not shared with servers. They are:
Ample parallelism: In the case of servers, we need to worry about the parallelism available in applications to justify the amount of parallel hardware. This is not the case with WSCs. Most jobs are totally independent and exploit “Request-level parallelism”. Interactive internet service applications, known as Software as a Service (SaaS) workload consists of independent requests of millions of users . Secondly, data of many batch applications can be processed in independent chunks, exploiting data-level parallelism.
Operational costs count: Server architects normally design systems for peak performance within a cost budget. Power concerns are not too much as long as the cooling requirements are maintained. The operational costs are ignored. WSCs, however, have a longer life times and the building, electrical and cooling costs are very high. So, the operational costs cannot be ignored. All these add up to more than 30% of the costs of a WSC in 10 years. Power consumption is a primary, not secondary constraint when designing the system.
Scale and its opportunities and problems: Since WSCs are so massive internally, you get volume discounts and economy of scale, even if there are not too many WSCs. On the other hand, custom hardware can be very expensive, particularly if only small numbers are manufactured. The economies of scale lead to cloud computing, since the lower per-unit costs of WSCs lead to lower rental rates. The flip side of the scale is failures. Even if a server had a Mean Time To Failure (MTTF) of twenty five years, the WSC architect should design for five server failures per day. Similarly, if there were four disks per server and their annual failure rate was 4%, there would be one disk failure per hour, considering 50,000 servers.
We can consider computer clusters formed with independent computers, standard local area networks and switches as forerunners of WSCs. WSCs are logical extensions of clusters, since we shift from hundreds of computers to tens of thousands of computers. Clusters have higher performance processors and networks since the applications using such clusters are more interdependent and communicate more frequently. Clusters emphasize thread-level parallelism, whereas, WSCs emphasize request-level parallelism.
When compared to a datacenter, the hardware and lower-layer software of a WSC is very homogeneous. Datacenters consolidate different machines and software into one location. Datacenters emphasize virtual machines and hardware heterogeneity in order to serve varied customers. They also do not get the scale advantage of WSCs. Typical datacentres share little with the challenges and opportunities of a WSC, either architecturally or operationally.
Programming Models and Workloads for WSCs: We have already seen that WSCs will have to work with both interactive workloads and offline batch processing. Typical batch processing jobs include converting videos into new formats or creating search indexes from web crawls.
The most popular framework for batch processing in a WSC today is MapReduce and its open source twin Hadoop. MapReduce is a processing technique and a program model for distributed computing based on java. The MapReduce algorithm contains two important tasks, namely Map and Reduce. Map takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). Secondly, the reduce task, takes the output from a map as an input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce task is always performed after the map job.
The major advantage of MapReduce is that it is easy to scale data processing over multiple computing nodes. Under the MapReduce model, the data processing primitives are called mappers and reducers. Decomposing a data processing application into mappers and reducers is sometimes nontrivial. But, once we write an application in the MapReduce form, scaling the application to run over hundreds, thousands, or even tens of thousands of machines in a cluster is merely a configuration change. This simple scalability is what has attracted many programmers to use the MapReduce model.
For example, we can look at one MapReduce program that calculates the number of occurrences of every English word in a large collection of documents. A simplified version of the program that shows just the inner loop and assumes just one occurrence of all English words found in a document is shown below:
– map (String key, String value):
// key: document name
// value: document contents for each word w in value
EmitIntermediate(w,”1”); // Produce list of all words
– reduce (String key, Iterator values):
// key: a word
// value: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v); // get integer from key-value pair
Emit(AsString(result));
Some of the additional features of MapReduce that are worth mentioning are as follows:
· MapReduce can be thought of as a generalization of SIMD, except that we pass a function to be applied to the different data, followed by a function used for reduction.
· In order to accommodate the variability in performance across thousands of computers, the MapReduce scheduler does backup executions for unfinished jobs. That is, if a slow node has not finished execution, it is again assigned to some other node, and the results are taken from the node that finishes first.
· Since failures are common in a WSC, dealing with failures is done by using replicas of data across different servers, detecting failed threads and re-starting them.
· MapReduce relies on the Google File System (GFS) to supply files to any computer, so that MapReduce tasks can be scheduled anywhere.
· WSC storage software often uses relaxed consistency rather than following all the ACID requirements of conventional database systems. That is, it is important that the multiple replicas of data agree eventually, but they do not have to be in agreement always.
· The workload demands of WSCs often vary considerably and the hardware and software should take note of the varying loads. It is important for servers in a WSC to perform well while doing little than perform efficiently at their peak, as they rarely operate at their peak.
· It is worth noting that the use of MapReduce within Google has been growing every year – within a short span, the number of MapReduce jobs has increased 100x times, the data being processed has increased 100x times and the number of servers per job has increased 3x times.
Computer Architecture of WSCs: Networks are the connecting tissue that binds all the tens of thousands of servers in a WSC. WSCs often use a hierarchy of networks for interconnection. Servers are typically placed in 19-inch (48.3-cm) racks. Servers are measured in the number of rack units (U) that they occupy in the rack (1U, 2U, etc.). One U is 1.75 inches (4.45 cm) high and that is the minimum space a server can occupy. A typical rack offers between 42 and 48 U. For example, each 19” rack holds 48 1U servers connected to a rack switch. The most popular switch for a rack is a 48-port Ethernet switch. The bandwidth within the rack is the same for each server.
Rack switches are uplinked to switch higher in hierarchy. The uplink has 48 / n times lower bandwidth, where n = # of uplink ports. Ratio between the internal bandwidth and uplink bandwidth is called the oversubscription factor. When there is a large oversubscription, we must be aware of the performance consequences when the senders and receivers are placed in different racks. The goal is to maximize locality of communication relative to the rack. The array switch connects an array of 30 racks,
which are more than ten times more expensive (per port) than a rack switch. The hierarchy showing the servers, racks and array switches is illustrated in Figure 39.1. The array switch should have 10 X the bisection bandwidth of rack switch and the cost of n-port switch grows as n2. Network switches are major users of content addressable memory chips and FPGAs.
As far as the storage is concerned, the simplest solution is to use disks inside the servers and use the Ethernet connectivity for accessing information on the disks of remote servers. The other option is to use Network Attached Storage (NAS) through a storage network like Infiniband. This is more expensive, but supports multiple features including RAID for improving dependability. WSCs generally rely on local disks and provide storage software that handle connectivity and dependability. For example, the Google File System (GFS) uses local disks and maintains at least three replicas to provide dependability.

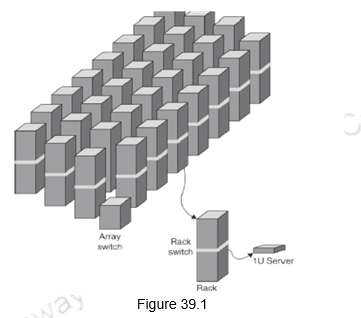
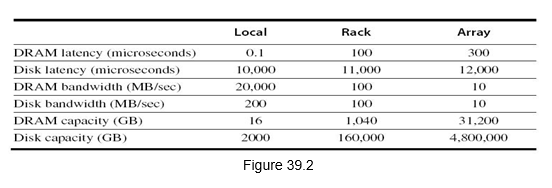
Figure 39.2 shows typical values for the latency, bandwidth and capacity of the memory hierarchy inside a WSC. Servers can access the DRAM and disks on other servers using a NUMA-style interface.
Physical Infrastructure and Costs of WSC: The first step to build a WSC is to build a warehouse. While choosing the location of WSC, we have to consider proximity to Internet backbones, low cost of electricity, low property tax rates and low risks from natural disasters like earthquakes, floods, and hurricanes.
The infrastructure costs for power distribution and cooling in a WSC form a major part. Figure 39.3 shows the power distribution within a WSC. There are about five steps and four voltage changes that happen on the way to the server from the high voltage lines. The substation switches from very high voltage lines to medium voltage lines with an efficiency of about 99.7%. The Uninterrupted Power Supply (UPS) that is used for power conditioning, holding the electrical load while the generators start and come on line, and holding the electrical load when switching back from the generators to the electrical utility, have an efficiency of about 94%. The WSC UPS accounts for 7% to 12% of the cost of all the IT equipment. The transformers that are used have an efficiency of about 98% and the connectors, breakers and electrical wiring have an efficiency of about 99%. Putting everything together, the efficiency from the high voltage source to the server is about 99.7% x 94% x 98% x 98% x 99% = 89%.
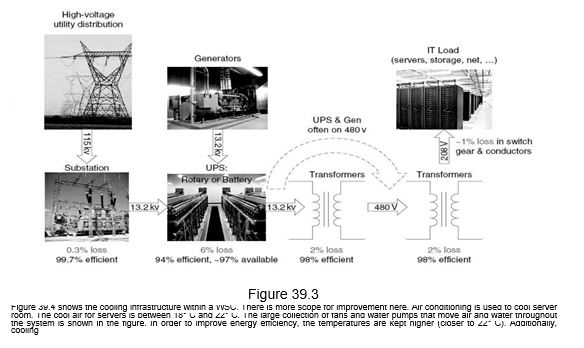
Figure 39.4 shows the cooling infrastructure within a WSC. There is more scope for improvement here. Air conditioning is used to cool server room. The cool air for servers is between 18⁰ C and 22⁰ C. The large collection of fans and water pumps that move air and water throughout the system is shown in the figure. In order to improve energy efficiency, the temperatures are kept higher (closer to 22⁰ C). Additionally, cooling towers can also be used. The minimum temperature that can be achieved by evaporating water with air is called the “wet bulb temperature”.
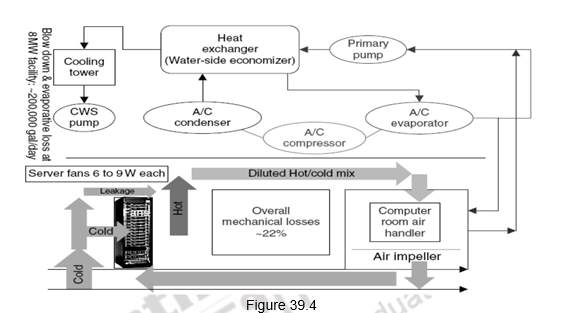
The cooling system also uses water (for evaporation and spills). Typically, an 8MW facility might use about 70,000 to 200,000 gallons per day. The relative power cost breakdown is as follows:
– Chillers: 30-50% of the power used by the IT equipment
– Air conditioning: 10-20% of the IT power, mostly due to fans
Measuring Efficiency of a WSC: A widely used measure to evaluate the efficiency of a datacenter or WSC is the Power Utilization Effectiveness (PEU).
PUE = Total facility power / IT equipment power
PUE must be greater than 1; the bigger the value, the less efficient is the WSC. Typical values range from 1.33 to 3.03, with a median of 1.69. Experiments conducted indicate that the Google average PUE for all WSCs is 1.12 and Facebook Prineville WSC is 1.07.
The cost – performance ratio is the ultimate measure of performance. As the distance from the data increases, the bandwidth drops and the latency increases. While designers of a WSC focus on the bandwidth, programmers developing applications on a WSC are also concerned about latency, because it is seen by users. An analysis of the Bing search engine shows that if a 200ms delay is introduced in the response, the next click by the user is delayed by 500ms. So, a poor response time amplifies the user’s non-producti vity. Because of this, it is required that a high percentage of requests be below a threshold target. Such threshold goals are called Service Level Objectives (SLOs) or Service Level Agreements (SLAs). For example, an SLO might be that 99% of requests be below 100 milliseconds.
We also have to worry about factors like Reliability (MTTF) and Availability (MTTF/MTTF+MTTR), given the large scale . Even if we assume a server with MTTF of 25 years, 50K servers would lead to 5 server failures a day. Similarly, annual disk failure rate is 2-10%, indicating that there will be one disk failure every hour.
While PUE measures the efficiency of a WSC, we also have to worry about what happens inside the IT equipment. The voltage that is supplied to the server has to be further stepped down and distributed to the various chips and there is a further reduction in efficiency. In addition to the power supply, the goal for the whole server should be energy proportionality. That is, servers should consume energy in proportion to the amount of work performed. Ideally, we want energy-proportional computing, but in reality, servers are not energy-proportional. An unloaded server dissipates a large amount of power. We can approach energy-proportionality by turning on a few servers that are heavily utilized.
Cost of a WSC: Designers of WSCs have to worry about both operational costs as well as the cost to build the WSC. Accordingly, the costs are divided as Capital expenditures (CAPEX) and Operational expenditures (OPEX). CAPEX includes all the costs associated with the building of the infrastructure of the WSC. CAPEX can be amortized into a monthly estimate by assuming that the facilities will last 10 years, server parts will last 3 years, and networking parts will last 4 years . OPEX includes the cost to operate a WSC. For example, the monthly bill for energy, failures, personnel, etc.
To summarize, we have looked at the requirements and working of a WSC in this module. Warehouse-scale computers form the basis of internet usage and have gained popularity. They share some commonalities with servers, yet are different in some ways. The important design factors to be considered are Cost-performance ratio, Energy efficiency, Dependability via redundancy, Network I/O and Handling of interactive and batch processing workloads. Infrastructure costs form an important part of the costs of a WSC and the Power Utilization Effectiveness is an important measure of efficiency.
Web Links / Supporting Materials
- Computer Architecture – A Quantitative Approach , John L. Hennessy and David A. Patterson, 5th Edition, Morgan Kaufmann, Elsevier, 2011.